了解Spark源码的概况
本文旨在帮助那些想要对Spark有更深入了解的工程师们,了解Spark源码的概况,搭建Spark源码阅读环境,编译、调试Spark源码,为将来更深入地学习打下基础。
一、项目结构
在大型项目中,往往涉及非常多的功能模块,此时借助于Maven进行项目、子项目(模块)的管理,能够节省很多开发和沟通成本。整个Spark项目就是一个大的Maven项目,包含着多个子项目。无论是Spark父项目还是子项目,本身都可以作为独立的Maven项目来管理。core是Spark最为核心的功能模块,提供了RPC框架、度量系统、Spark UI、存储体系、调度系统、计算引擎、部署模式等功能的核心实现。这些Spark中主要子项目(模块)的功能如下:
- spark-catalyst:Spark的词法、语法分析、抽象语法树(AST)生成、优化器、生成逻辑执行计划、生成物理执行计划等。
- spark-core:Spark最为基础和核心的功能模块。
- spark-examples:使用多种语言,为Spark学习人员提供的应用例子。
- spark-sql:Spark基于SQL标准,实现的通用查询引擎。
- spark-hive:Spark基于Spark SQL,对Hive元数据、数据的支持。
- spark-mesos:Spark对Mesos的支持模块。
- spark-mllib:Spark的机器学习模块。
- spark-streaming:Spark对流式计算的支持模块。
- spark-unsafe:Spark对系统内存直接操作,以提升性能的模块。
- spark-yarn:Spark对Yarn的支持模块。
二、阅读环境准备
准备Spark阅读环境,就需要一台好机器。笔者调试源码的机器的内存是8GB。源码阅读的前提是首先在IDE环境中打包、编译通过。常用的IDE有 IntelliJ IDEA和Eclipse,笔者选择用Eclipse编译和阅读Spark源码,原因有二:一是由于使用多年对它比较熟悉,二是社区中使用Eclipse编译Spark的资料太少,在这里可以做个补充。笔者在Mac OS系统编译Spark源码,除了安装JDK和Scala外,还需要安装以下工具。
1.安装SBT
由于Scala使用SBT作为构建工具,所以需要下载SBT。下载地址: http://www.scala-sbt.org/,下载最新的安装包sbt-0.13.12.tgz并安装。
移动到选好的安装目录,例如:
mv sbt-0.13.12.tgz~/install/
进入安装目录,执行以下命令:
chmod 755 sbt-0.13.12.tgz
tar -xzvf sbt-0.13.12.tgz
配置环境:
cd ~
vim .bash_profile
添加如下配置:
export SBT_HOME=$HOME/install/sbt
export PATH=$SBT_HOME/bin:$PATH
输入以下命令使环境变量快速生效:
source .bash_profile
安装完毕后,使用sbt about命令查看,确认安装正常,如图1所示。

图1 查看sbt安装是否正常
2.安装Git
由于Spark源码使用Git作为版本控制工具,所以需要下载Git的客户端工具。下载地址:https://git-scm.com,下载最新的版本并安装。
安装完毕后可使用git –version命令来查看安装是否正常,如图2所示。

图2 查看git是否安装成功
3.安装Eclipse Scala IDE插件
Eclipse通过强大的插件方式支持各种IDE工具的集成,要在Eclipse中编译、调试、运行Scala程序,就需要安装Eclipse Scala IDE插件。下载地址:http://scala-ide.org/download/current.html。
由于笔者本地的Eclipse版本是Eclipse Mars.2 Release (4.5.2),所以选择安装插件http://download.scala-ide.org/sdk/lithium/e44/scala211/stable/site,如图3:

图3 EclipseScala IDE插件安装地址
在Eclipse中选择“Help”菜单,然后选择www.feifanyule.cn/ “www.qinlinyule.cn www.120xh.cn Install New www.089188.cn Software…”选项,打开Install对话框,如图4所示:
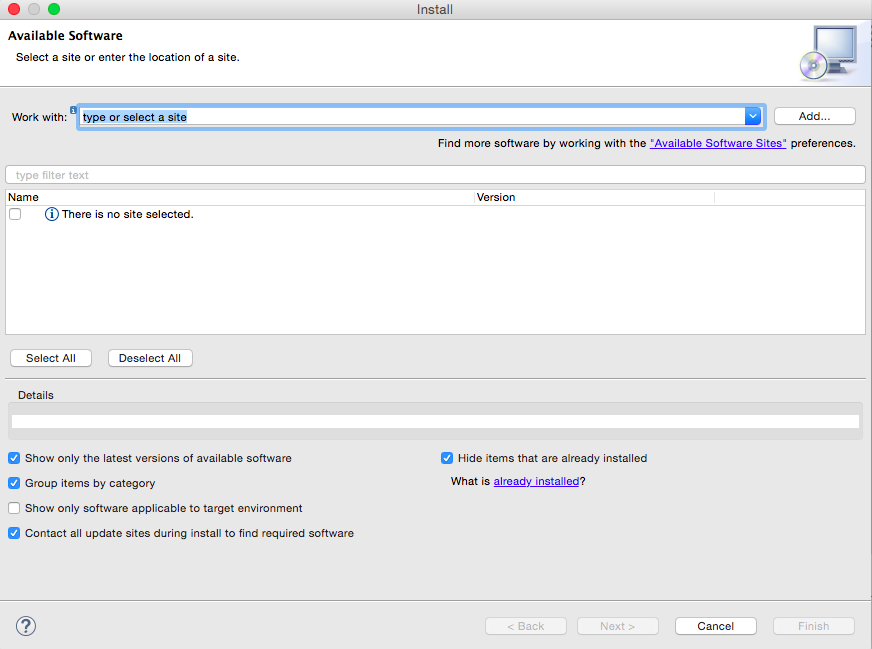
图4 安装Scala IDE插件
点击“Add…”按钮,打开“Add Repository”对话框,输入插件地址,如5图所示:
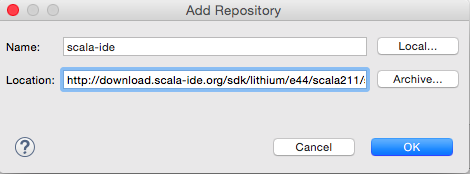
图5 添加Scala IDE插件地址
全选插件的内容,完成安装,如图6所示:
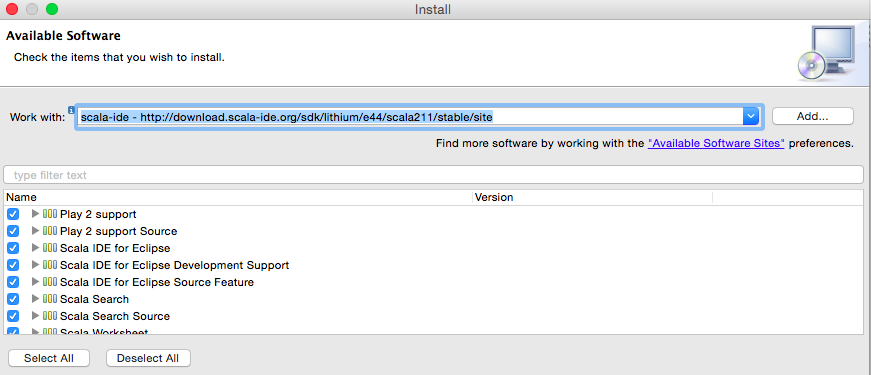
图6 安装Scala IDE插件
三、Spark源码编译与调试
1.下载Spark源码
首先,访问Spark官网http://spark.apache.org/,如图7所示。
图7 Spark官网
点击“Download Spark”按钮,在下一个页面找到Git地址,如图8所示。

图8 Spark官方Git地址
笔者在当前用户目录下创建Source文件夹作为放置Spark源码的地方,进入此文件夹并输入git clonegit://github.com/apache/spark.git命令将源码下载到本地,如9图所示。

图9下载Spark源码
2.构建Scala应用
进到Spark根目录,执行sbt命令。会下载和解析很多jar包,要等很长的时间,笔者大概花费了一个多小时,才执行完,如图10所示。

图10 构建Scala应用
从图10可以看出,sbt构建完毕时会出现提示符>。
3.使用sbt生成eclipse工程文件
在sbt命令出现提示符>后,输入eclipse命令,开始生成eclipse工程文件,也需要花费很长的时间,笔者本地大致花费了40分钟。完成时的状况,如图11所示。
图11 sbt编译过程
现在我们查看Spark下的子文件夹,发现其中都生成了.project和.classpath文件。比如mllib项目下就生成了.project和.classpath文件,如图12所示。
图12 sbt生成的项目文件
4. 编译Spark源码
由于Spark使用Maven作为项目管理工具,所以需要将Spark项目作为Maven项目导入到Eclipse中,如13图所示:
图13 导入Maven项目
点击Next按钮进入下一个对话框,如图14所示:
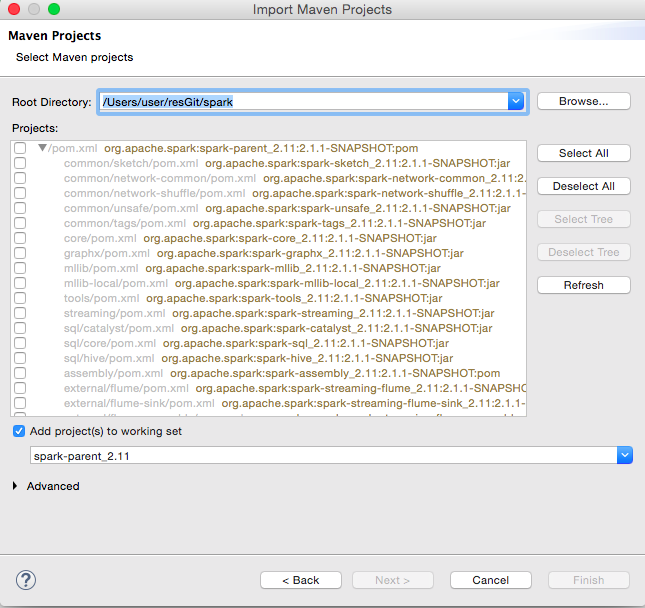
图14 选择Maven项目
全选所有项目,点击finish按钮。这样就完成了导入,如图15所示:
图15 导入完成的项目
导入完成后,需要设置每个子项目的build path。右键单击每个项目,选择“Build Path”→“Configure BuildPath…”,打开Build Path对话框,如图16:
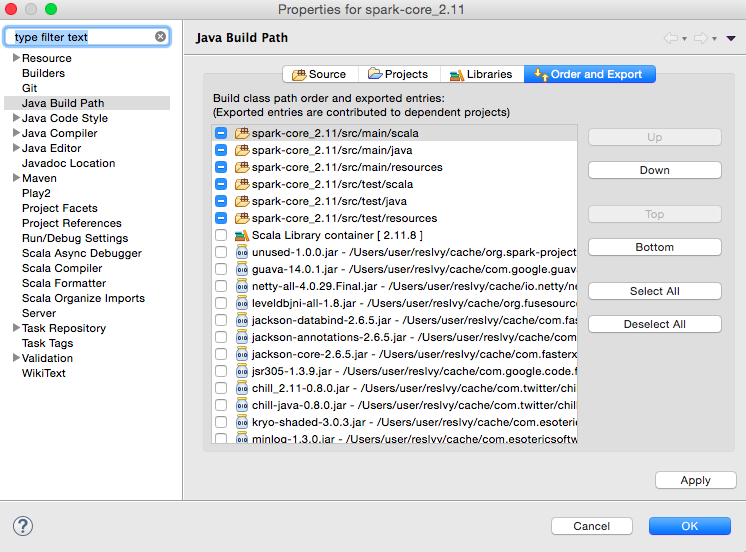
图16 Java构建路径
Eclipse在对项目编译时,可能会出现很多错误,只要仔细分析报错原因就能一一排除。所有错误解决后运行mvn clean install,如图17所示:
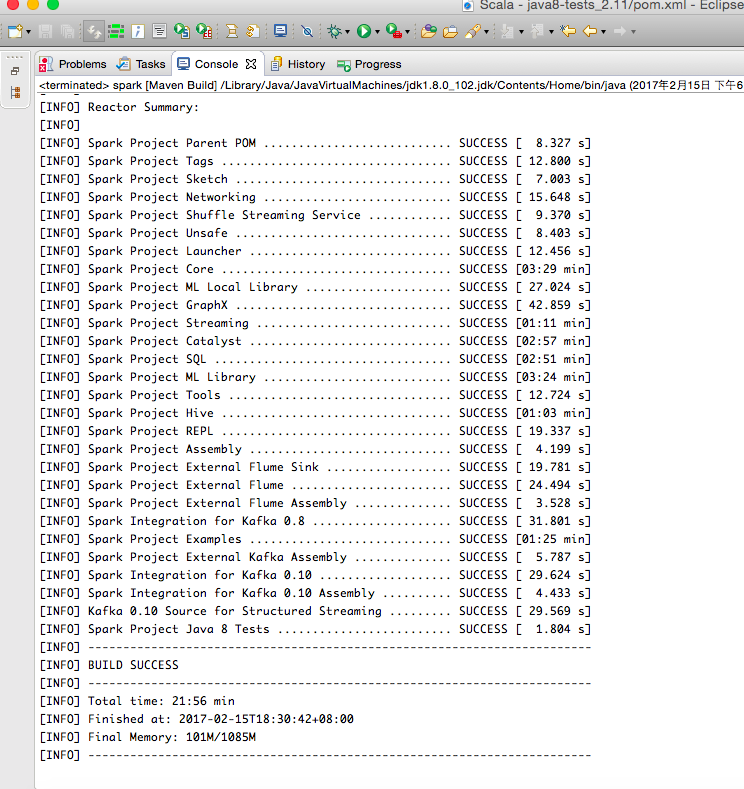
图17 编译成功
5.调试Spark源码
以Spark源码自带的JavaWordCount为例,介绍如何调试Spark源码。右键单击JavaWordCount.java,选择“Debug As”→“Java Application”即可。如果想修改配置参数,右键单击JavaWordCount.java,选择“Debug As”→“DebugConfigurations…”,从打开的对话框中选择JavaWordCount,在右侧标签可以修改Java执行参数、JRE、classpath、环境变量等配置,如图18所示:
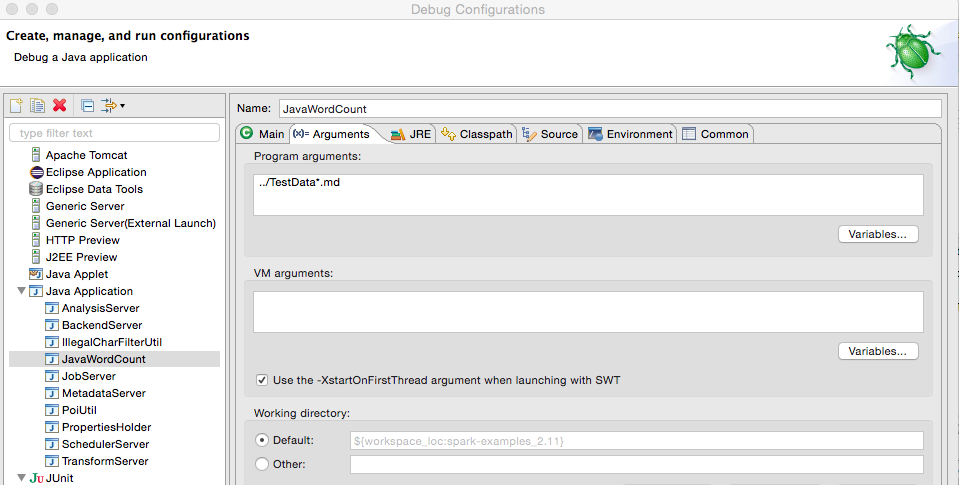
图18 源码调试
读者也可以在Spark源码中设置断点,进行跟踪调试。
关于《Spark内核设计的艺术 架构设计与实现》
了解Spark源码的概况的更多相关文章
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- Apache Spark源码剖析
Apache Spark源码剖析(全面系统介绍Spark源码,提供分析源码的实用技巧和合理的阅读顺序,充分了解Spark的设计思想和运行机理) 许鹏 著 ISBN 978-7-121-25420- ...
- Spark源码学习1.2——TaskSchedulerImpl.scala
许久没有写博客了,没有太多时间,最近陆续将Spark源码的一些阅读笔记传上,接下来要修改Spark源码了. 这个类继承于TaskScheduler类,重载了TaskScheduler中的大部分方法,是 ...
- Spark源码在Eclipse中部署/编译/运行
(1)下载Spark源码 到官方网站下载:Openfire.Spark.Smack,其中Spark只能使用SVN下载,源码的文件夹分别对应Openfire.Spark和Smack. 直接下载Openf ...
- 使用 IntelliJ IDEA 导入 Spark源码及编译 Spark 源代码
1. 准备工作 首先你的系统中需要安装了 JDK 1.6+,并且安装了 Scala.之后下载最新版的 IntelliJ IDEA 后,首先安装(第一次打开会推荐你安装)Scala 插件,相关方法就不多 ...
- 搭建openfire Android 客户端学习和开发【二】spark源码导入eclipse
首先声明下 这是我在eoe上转载的 写的很好就摘抄了... 第一步 下载源码 svn下载,下载地址:spark:http://svn.igniterealtime.org/svn/repos/spar ...
- Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
欢迎转载,转载请注明出处,徽沪一郎. 概要 上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅.本篇讲述如何使用 ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之6 -- 存储子系统分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数 ...
随机推荐
- 1060: [ZJOI2007]时态同步
Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 3610 Solved: 1521[Submit][Status][Discuss] Descript ...
- BZOJ4128: Matrix(BSGS 矩阵乘法)
Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 813 Solved: 442[Submit][Status][Discuss] Descriptio ...
- 浅谈MySQL字符集
Preface MySQL use character set & collation to organize the different charater.It provid ...
- linux面试集
shell:1.$# 和 $*之类的特殊变量 特殊变量列表 变量 含义 $0 当前脚本的文件名 $n 传递给脚本或函数的参数.n是一个数字,表示第几个参数.例如,第一个参数就是$1 $# 传递给脚本或 ...
- django中的分页管理
有时,展示的对象太多,需要对他们进行分页展示,不能一页把所有的结果都展示出来吧,那样的话,哈哈,挺逗 使用Django分页器功能 从Django中导入Paginator模块(没有的话,自行下载,我是w ...
- linux无名管道
特点 无名管道是半双工的,也就是说,一个管道要么只能读,要么只能写 只能在有共同祖先的进程间使用(父子进程.兄弟进程.子孙进程等) fork或者execve调用创建的子进程,继承了父进程的文件描述符 ...
- python基础之继承组合应用、对象序列化和反序列化,选课系统综合示例
继承+组合应用示例 1 class Date: #定义时间类,包含姓名.年.月.日,用于返回生日 2 def __init__(self,name,year,mon,day): 3 self.name ...
- Spring.net Ioc 依赖注入
控制反转 (Inversion of Control,英文缩写为IoC)是一个重要的面向对象编程的法则来削减计算机程序的耦合问题,也是轻量级的Spring框架的核心. 控制反转一般分为两种类型,依赖注 ...
- android onNewIntent 为什么要在onNewIntent的时候要显示的去调用setIntent
原因: 当调用到onNewIntent(intent)的时候,需要在onNewIntent() 中使用setIntent(intent)赋值给Activity的Intent.否则,后续的getInte ...
- gettid 和pthread_self的区别
转: Linux中,每个进程有一个pid,类型pid_t,由getpid()取得.Linux下的POSIX线程也有一个id,类型 pthread_t,由pthread_self()取得,该id由线程库 ...