linux上hadoop2.4.0安装配置
1 环境准备
安装java-1.6(jdk)
安装ssh
1.1 安装jdk
(1)下载安装jdk
在/usr/lib下创建java文件夹,输入命令:
cd /usr/lib
mkdir java
输入命令:
sudo apt-get install sun-java6-jdk
下载后执行安装文件
(2)配置环境变量
输入命令:
sudo gedit /etc/environment
将如下内容加入其中:
JAVA_HOME=/usr/lib/java/jdk1.6.0_45
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:
/usr/lib/java/jdk1.6.0_45/bin:/usr/lib/java/jdk1.6.0_45:/home/ylf/hadoop/bin:/home/ylf/hadoop/sbin"
CLASSPATH=/usr/lib/java/jdk1.6.0_45/lib:/usr/lib/java/jdk1.6.0_45/jre/lib
其中path部分是在你原有的path变量基础上加入你所安装的jdk路径。
执行如下命令使得配置生效:
source /etc/environment
(3)验证java是否安装成功
输入命令:
java -version
1.2 配置ssh免密码登录
输入命令:
sudo apt-get install ssh
配置可以无密码登陆本机:
在当前用户目录下新建隐藏文件.ssh,输入命令:
mkdir .ssh
接下来,输入命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
这个命令会在.ssh文件夹下创建两个文件id_dsa及id_dsa.pub,这是一对私钥和公钥,然后把id_dsa.pub(公钥)追加到授权的key里面去,输入命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
验证ssh已安装成功及无密码登陆本机,输入命令:
ssh -version
显示结果:
Bad escape character 'rsion'.
这显示ssh已经安装成功。
登陆ssh,输入命令:
ssh localhost
第一次登陆可能会询问是否继续链接,输入yes即可,以后登陆直接登进去。
显示结果:
Welcome to Ubuntu 14.04.1 LTS (GNU/Linux 3.13.0-32-generic x86_64) * Documentation: https://help.ubuntu.com/ Last login: Sun Oct 12 13:27:58 2014 from localhost
2.安装hadoop2.4.0
2.1 下载hadoop2.4.0
从官网上下载hadoop-2.4.0.tar.gz
2.2 解压hadoop-2.4.0.tar.gz,并重命名为hadoop
tar xzvf hadoop-2.4.0.tar.gz
mv hadoop-2.4.0 hadoop
2.3 配置环境变量
sudo gedit /etc/environment
在文件中加入:
HADOOP_HOME=/home/ylf/hadoop
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:
/usr/lib/java/jdk1.6.0_45/bin:/usr/lib/java/jdk1.6.0_45:/home/ylf/hadoop/bin:/home/ylf/hadoop/sbin"
其中path为原有的path变量中加入hadoop的路径。
执行如下命令,使之生效:
source /etc/environment
2.4单机模式配置
单机模式不用任何配置就可以直接进行测试。
运行hadoop自带的wordcount实例,统计一批文本文件中单词出现的次数
bin/hadoop jar /usr/local/hadoop2.4.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar wordcount input output
其中input已经上传至hdfs中,上传命令:
./bin/hdfs dfs -put input /input
2.5 伪分布式模式
2.5.1 修改配置文件
在当前用户目录下创建文件夹hadoop_tmp,输入命令:
mkdir hadoop_tmp
配置文件都在安装目录的etc/hadoop下
修改hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}改为你自己安装的jdk路径:
export JAVA_HOME=/usr/lib/java/jdk1.6.0_45
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/ylf/hadoop_tmp</value>
</property>
</configuration>
修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ylf/hadoop/dfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ylf/hadoop/dfs/datanode</value>
<final>true</final>
</property>
<property>
<name>dfs.http.address</name>
<value>localhost:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/home/ylf/hadoop/mapred/system</value>
<final>true</final>
</property> <property>
<name>mapred.local.dir</name>
<value>file:/home/ylf/hadoop/mapred/local</value>
<final>true</final>
</property>
</configuration>
修改yarn-site.xml:
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
<description>hostname of Resource Manager</description>
</property>
</configuration>
修改slaves文件
localhost
默认就是localhost,所以不用修改。
启动伪分布式模式:
第一次启动都要格式化下数据文件,命令:
./bin/hdfs namenode -format
启动hadoop,命令:
./sbin/start-all.sh
查看,命令:
jps
结果:
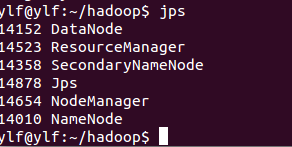
表示启动成功。
2.6 web访问端口
| NameNode | 50070 |
| ResourceManager | 8088 |
| MapReduce JobHistory Server | 19888 |
访问http://localhost:50070

访问http://localhost:8088
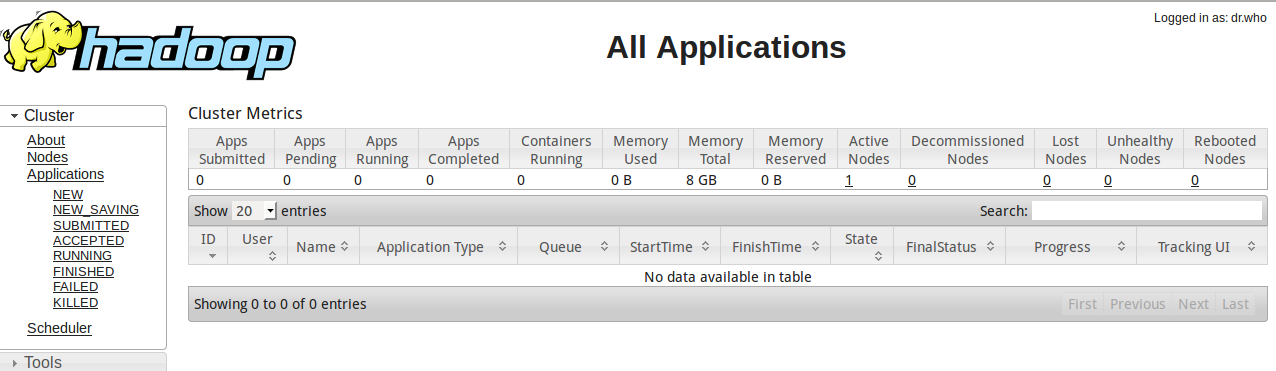
其中19888端口要启动JobHistoryServer进程,启动命令如下:
./sbin/mr-jobhistory-daemon.sh start historyserver
然后访问http://localhost:19888
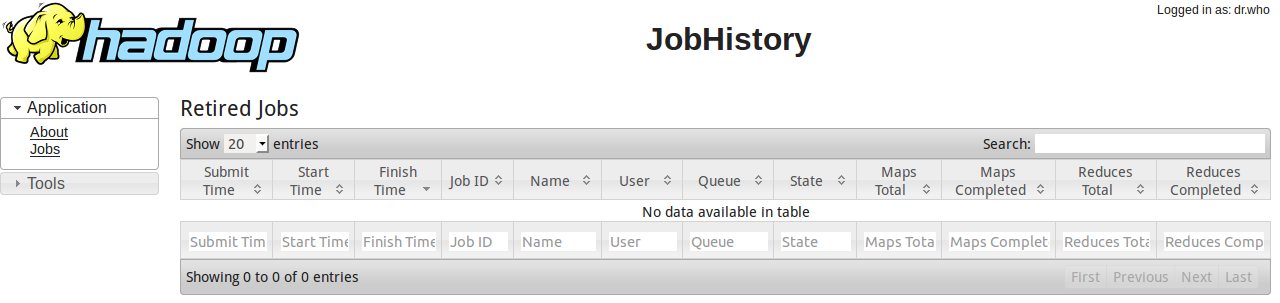
到此为止,hadoop的伪分布式安装配置讲解完毕。
hadoop基本命令:
1.查看hdfs 文件夹下文件命令
hadoop fs -ls dir
2.从本地上传至hdfs
hadoop fs -copyFromLocal input/hello.txt /input/hello.txt
3.从hdfs下载至本地
hadoop fs -copyToLocal /input/hello.txt input/hello.copy.txt
4.创建文件夹
hadoop fs -mkdir testDir
5.查看hdfs文件列表
hadoop fs -lsr /testDir
linux上hadoop2.4.0安装配置的更多相关文章
- HADOOP2.2.0安装配置指南
一. 集群环境搭建 这里我们搭建一个由三台机器组成的集群: Ip地址 用户名/密码 主机名 集群中角色 操作系统版本 192.168.0.1 hadoop/hadoop Hadoop-mast ...
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
http://blog.csdn.net/licongcong_0224/article/details/12972889 历时一周多,终于搭建好最新版本hadoop2.2集群,期间遇到各种问题,作为 ...
- Hadoop2.2.0安装配置手册
第一部分 Hadoop 2.2 下载 Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2.官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独 ...
- hadoop2.4.0 安装配置 (2)
hdfs-site.xml 配置如下: <?xml version="1.0" encoding="UTF-8"?> <?xml-styles ...
- Windows和Linux下apache-artemis-2.10.0安装配置
window下安装配置 一.官网下载 http://activemq.apache.org/artemis/download.html 二.百度网盘下载 链接:https://pan.baidu.c ...
- 【转发】【linux】【ftp】CentOS 7.0安装配置Vsftp服务器
adduser -d /var/www/android -g ftp -s /sbin/nologin ftp2 一.配置防火墙,开启FTP服务器需要的端口 CentOS 7.0默认使用的是firew ...
- Hadoop2.6.0安装 — 集群
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6034187.html 这里写点 Hadoop2.6.0集群的安装和简单配置,一方面是为自 ...
- Linux下Hadoop2.6.0集群环境的搭建
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安装与配置 现在直接到Oracle官网(http:/ ...
- Linux系统中ElasticSearch搜索引擎安装配置Head插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
随机推荐
- 使用Lucene的java api 写入和读取索引库
import org.apache.commons.io.FileUtils;import org.apache.lucene.analysis.standard.StandardAnalyzer;i ...
- 关于EF使用脏读(连接会话开始执行设置隔离级别)
SQL Server中事物隔离级别Read Uncommitted和with(nolock) 注意:应该使用后者(修改后的版本):
- flask中的上下文_请求上下文和应用上下文
前引 在了解flask上下文管理机制之前,先来一波必知必会的知识点. 面向对象双下方法 首先,先来聊一聊面向对象中的一些特殊的双下划线方法,比如__call__.__getattr__系列.__get ...
- luogu3760 [TJOI2017]异或和
看这里 #include <iostream> #include <cstring> #include <cstdio> using namespace std; ...
- python 多线程、多进程、协程性能对比(以爬虫为例)
基本配置:阿里云服务器低配,单核2G内存 首先是看协程的效果: import requests import lxml.html as HTML import sys import time impo ...
- layer2-1 二层
一 概述 一层的相关介绍 CSMA/CD 网桥和交换机的区别 冲突 共享 端口密度 性能 功能 交换机的三种主流转发方式 存储转发 完整的收到 ...
- x86 idt
Interrupt/trap gate
- vscode & code snippets
code snippets vscode & code snippets https://github.com/xgqfrms/FEIQA/tree/master/000-xyz/templa ...
- DIV垂直/水平居中2(DIV宽度和高度是动态的)
<!doctype html><html><head><meta charset="utf-8"><title>块元素D ...
- 【Luogu】P3414组合数(快速幂)
题目链接 从n的元素中选零个,选一个,选两个,选三个...选n个的方案数和,其实就是n个元素中取任意多个元素的方案数,那对于每一个元素,都有取或不取两种情况,所以方案数最终为2^n个. #includ ...