大数据学习——hadoop安装
上传centOS6.7-hadoop-2.6.4.tar.gz
解压 tar -zxvf centOS6.7-hadoop-2.6.4.tar.gz
hadoop相关修改配置
1 修改 /root/apps/hadoop/etc/hadoop 目录下的hadoop-env.sh
vi hadoop-env.sh 中 export JAVA_HOME=${JAVA_HOME}修改为 export JAVA_HOME=/root/apps/jdk1.7.0_80保存退出
2 修改 core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mini:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/apps/hadoop/tmp</value>
</property>
修改后的文件内容如下:
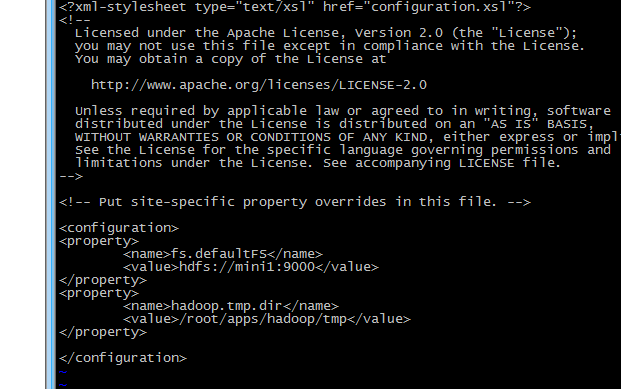
保存退出。
3修改hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>mini1:50090</value>
</property>
修改后的文件为:
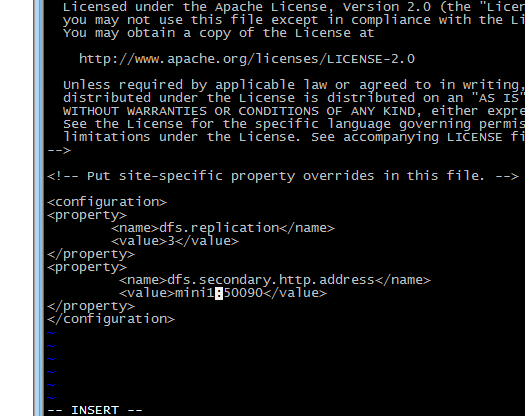
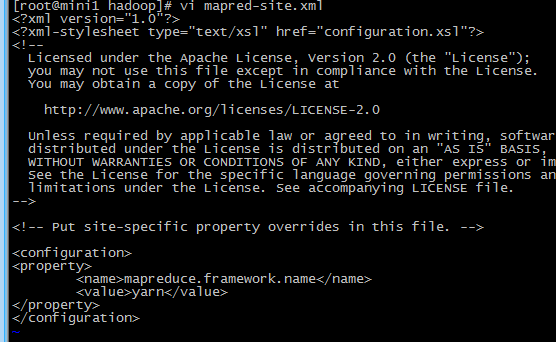
4 修改 mapred-site.xml(mv mapred-site.xml.template mapred-site.xml)
没有该文件,先cp一份(cp mapred-site.xml.template mapred-site.xml)
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5修改yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend-1206-01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
将hadoop添加到环境变量
vi /etc/proflie
export JAVA_HOME=/root/apps/jdk1.7.0_80
export HADOOP_HOME=/root/apps/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改后的文件如下
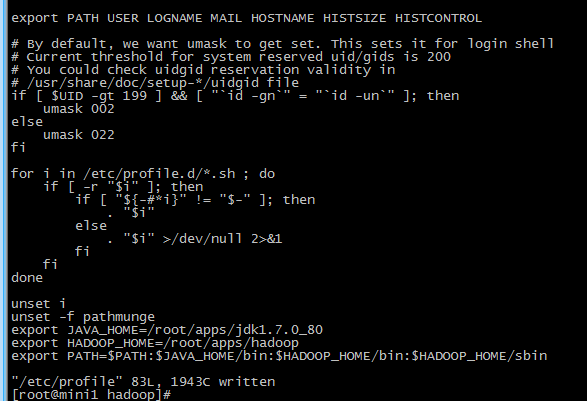
把修改后的hadoop发送到mini2,mini3
scp -r /root/apps/hadoop/ root@mini2:/root/apps/
scp -r /root/apps/hadoop/ root@mini3:/root/apps/

把修改的环境变量文件cp到mini2,mini3
scp -r /etc/profile root@mini2:/etc/profile
scp -r /etc/profile root@mini3:/etc/profile
在mini1,mini2,mini3上重新加载一下
source /etc/profile
完成
大数据学习——hadoop安装的更多相关文章
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——Hadoop第一天
1.1 什么是HADOOP HADOOP是apache旗下的一套开源软件平台 HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理 HADOOP的核心组件有 HD ...
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- 大数据学习——hive安装部署
1上传压缩包 2 解压 tar -zxvf apache-hive-1.2.1-bin.tar.gz -C apps 3 重命名 mv apache-hive-1.2.1-bin hive 4 设置环 ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习——VMware安装
---恢复内容开始--- 一.下载VMware,安装 二.新建虚拟机 1.FIle-->new virtual machine 后面进入硬件资源分配,其中cpu给1个,内存至少给1G,网卡的选择 ...
- 大数据学习——hadoop的RPC框架
项目结构 服务端代码 test-hadoop-rpc pom.xml <?xml version="1.0" encoding="UTF-8"?> ...
- 大数据学习——redis安装
用源码工程来编译安装 / 到官网下载最新stable版 / 解压源码并进入目录 .tar.gz -C ./redis-src/ / make 如果报错提示缺少gcc,则安装gcc : yum inst ...
- 大数据学习——yum安装tomcat
https://www.cnblogs.com/jtlgb/p/5726161.html 安装tomcat6 yum install tomcat6 tomcat6-webapps tomcat6-a ...
随机推荐
- 135 Candy 分配糖果
There are N children standing in a line. Each child is assigned a rating value.You are giving candie ...
- RxJava+Retrofit实现网络请求
RxJava+Retrofit实现网络请求: 首先要添加依赖 compile 'io.reactivex:rxjava:x.y.z' compile 'io.reactivex:rxandroid:1 ...
- solr查询优化【转】filtercache
solr查询优化(实践了一下效果比较明显) 什么是filtercache? solr应用中为了提高查询速度有可以利用几种cache来优化查询速度,分别是fieldValueCache,queryRes ...
- C#基础学习1
开发入门,最基础的学习!
- .net excel 导入 导出
哎,好好的代码今天说来个实验,结果用的是office15 气死人了,网上最高office14.dll 文章转自2012年 QQ群:13615607 MR.Young protected void Bt ...
- 【学习笔记】Sass入门指南
本文将介绍Sass的一些基本概念,比如说“变量”.“混合参数”.“嵌套”和“选择器继承”等.著作权归作者所有. 什么是Sass? Sass是一门非常优秀的CSS预处语言,他是由Hampton Catl ...
- filter和map的使用
if ( this.dataAggridvue.filter( item => item.Accepted == true && item.InvoiceGroupCode != ...
- 毕业设计:主界面(ViewPager + FragmentPagerAdapter)
一.主要思路 应用程序的主界面包含三个部分:顶部标题栏.底部标识栏和中间的内容部分.顶部标题栏内容基本不变,用于显示当前模块或者整个应用的名称:底部既能标识出当前Page,又能通过触发ImageBut ...
- Java Script 学习笔记(一)
示例如下: JavaScript-警告(alert 消息对话框) 我们在访问网站的时候,有时会突然弹出一个小窗口,上面写着一段提示信息文字.如果你不点击“确定”,就不能对网页做任何操作,这个小窗口就是 ...
- jQuery ajax参数后台获取不到的问题
<script type="text/javascript"> init(); var alldate = {a : "0",b:"1&q ...