源码阅读之LinkedHashMap(JDK8)
概述
LinkedHashMap继承自HashMap,实现了Map<K,V>接口。其内部还维护了一个双向链表,在每次插入数据,或者访问、修改数据时,会增加节点、或调整链表的节点顺序。以决定迭代时输出的顺序。
默认情况,遍历时的顺序是按照插入节点的顺序。这也是其与HashMap最大的区别。
也可以在构造时传入accessOrder参数,使得其遍历顺序按照访问的顺序输出。
因继承自HashMap,所以除了输出无序,其他LinkedHashMap都有,比如扩容的策略,哈希桶长度一定是2的N次方等等。
LinkedHashMap在实现时,就是重写override了几个方法。以满足其输出序列有序的需求。
内部结构
LinkedHashMap的实现主要分两部分,一部分是哈希表,另外一部分是链表。
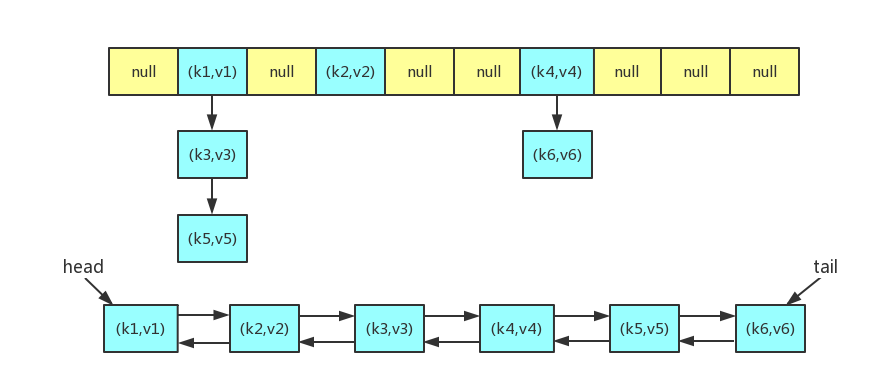
数据结构
//LinkedHashMap的链表节点继承了HashMap的节点,而且每个节点都包含了前指针和后指针,
//所以这里可以看出它是一个双向链表
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
} //双向链表的头指针
transient LinkedHashMap.Entry<K,V> head;
//双向链表的尾指针
transient LinkedHashMap.Entry<K,V> tail;
//默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序。
//为true时,可以在这基础之上构建一个LruCach
final boolean accessOrder;
构造函数
//指定初始化时的容量,和扩容的加载因子
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
//指定初始化时的容量
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
} public LinkedHashMap() {
super();
accessOrder = false;
} //利用另一个Map 来构建,
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
} //指定初始化时的容量,和扩容的加载因子,以及迭代输出节点的顺序
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
构造函数和HashMap相比,就是增加了一个accessOrder参数,用于控制迭代时的节点顺序,默认是false。
覆盖的方法
在HashMap中有三个模版方法,供子类来覆盖,在访问、插入、删除某个节点之后,进行一些特殊处理。
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
1. afterNodeAccess方法,会将当前被访问到的节点e,移动至内部的双向链表的尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;//原尾节点
//如果accessOrder 是true ,且原尾节点不等于e
if (accessOrder && (last = tail) != e) {
//节点e强转成双向链表节点p
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p现在是尾节点, 后置节点一定是null
p.after = null;
//如果p的前置节点是null,则p以前是头结点,所以更新现在的头结点是p的后置节点a
if (b == null)
head = a;
else//否则更新p的前直接点b的后置节点为 a
b.after = a;
//如果p的后置节点不是null,则更新后置节点a的前置节点为b
if (a != null)
a.before = b;
else//如果原本p的后置节点是null,则p就是尾节点。 此时 更新last的引用为 p的前置节点b
last = b;
if (last == null) //原本尾节点是null 则,链表中就一个节点
head = p;
else {//否则 更新 当前节点p的前置节点为 原尾节点last, last的后置节点是p
p.before = last;
last.after = p;
}
//尾节点的引用赋值成p
tail = p;
//修改modCount。
++modCount;
}
}
2.afterNodeInsertion方法,在哈希表中插入了一个新节点时调用的,它会把链表的头节点删除掉,删除的方式是通过调用HashMap的removeNode方法。
//回调函数,新节点插入之后回调 , 根据evict 和 判断是否需要删除最老插入的节点。如果实现LruCache会用到这个方法。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//LinkedHashMap 默认返回false 则不删除节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//LinkedHashMap 默认返回false 则不删除节点。 返回true 代表要删除最早的节点。通常构建一个LruCache会在达到Cache的上限是返回true
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
3.afterNodeRemoval方法,把在HashMap中删除的那个键值对一并从链表中删除,保证了哈希表和链表的一致性。
//在删除节点e时,同步将e从双向链表上删除
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//待删除节点 p 的前置后置节点都置空
p.before = p.after = null;
//如果前置节点是null,则现在的头结点应该是后置节点a
if (b == null)
head = a;
else//否则将前置节点b的后置节点指向a
b.after = a;
//同理如果后置节点时null ,则尾节点应是b
if (a == null)
tail = b;
else//否则更新后置节点a的前置节点为b
a.before = b;
}
添加元素
LinkedHashMap并没有重写任何put方法,但是其重写了构建新节点的newNode()方法,newNode()会在HashMap的putVal()方法里被调用。在每次构建新节点时,通过linkNodeLast(p),将新节点链接在内部双向链表的尾部。在putVal()里也调用了afterNodeInsertion方法
//在构建新节点时,构建的是`LinkedHashMap.Entry` 不再是`Node`.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//将新增的节点,连接在链表的尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//集合之前是空的
if (last == null)
head = p;
else {//将新节点连接在链表的尾部
p.before = last;
last.after = p;
}
}
删除元素
LinkedHashMap也没有重写remove()方法,因为它的删除逻辑和HashMap并无区别。 但它重写了afterNodeRemoval()这个回调方法,在remove方法里会调用这个afterNodeRemoval方法。
查询元素
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
对比HashMap中的实现,LinkedHashMap只是增加了在成员变量(构造函数时赋值)accessOrder为true的情况下,要去回调void afterNodeAccess(Node<K,V> e)函数。
遍历
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
} abstract class LinkedHashIterator {
//下一个节点
LinkedHashMap.Entry<K,V> next;
//当前节点
LinkedHashMap.Entry<K,V> current;
int expectedModCount; LinkedHashIterator() {
//初始化时,next 为 LinkedHashMap内部维护的双向链表的扁头
next = head;
//记录当前modCount,以满足fail-fast
expectedModCount = modCount;
//当前节点为null
current = null;
}
//判断是否还有next
public final boolean hasNext() {
//就是判断next是否为null,默认next是head 表头
return next != null;
}
//nextNode() 就是迭代器里的next()方法 。
//该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。
final LinkedHashMap.Entry<K,V> nextNode() {
//记录要返回的e。
LinkedHashMap.Entry<K,V> e = next;
//判断fail-fast
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
//如果要返回的节点是null,异常
if (e == null)
throw new NoSuchElementException();
//更新当前节点为e
current = e;
//更新下一个节点是e的后置节点
next = e.after;
//返回e
return e;
}
//删除方法 最终还是调用了HashMap的removeNode方法
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
示例
Map<String, String> map = new LinkedHashMap<>();
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("4", "d"); Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
} System.out.println("以下是accessOrder=true的情况:"); map = new LinkedHashMap<String, String>(10, 0.75f, true);
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
map.put("4", "d");
map.get("2");//2移动到了内部的链表末尾
map.get("4");//4调整至末尾
map.put("3", "e");//3调整至末尾
map.put(null, null);//插入两个新的节点 null
map.put("5", null);//
iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
结果:
1=a
2=b
3=c
4=d
以下是accessOrder=true的情况:
1=a
2=b
4=d
3=e
null=null
5=null
源码阅读之LinkedHashMap(JDK8)的更多相关文章
- 源码阅读之HashMap(JDK8)
概述 HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的. HashMap最多只允许一条记录的键为null,允许多条记录 ...
- jdk源码阅读笔记-LinkedHashMap
Map是Java collection framework 中重要的组成部分,特别是HashMap是在我们在日常的开发的过程中使用的最多的一个集合.但是遗憾的是,存放在HashMap中元素都是无序的, ...
- 源码阅读之LinkedList(JDK8)
inkedList概述 LinkedList是List和Deque接口的双向链表的实现.实现了所有可选列表操作,并允许包括null值. LinkedList既然是通过双向链表去实现的,那么它可以被当作 ...
- 源码阅读之ArrayList(JDK8)
ArrayList概述 ArrayList是一个的可变数组的实现,实现了所有可选列表操作,并允许包括 null 在内的所有元素.每个ArrayList实例都有一个容量,该容量是指用来存储列表元素的数组 ...
- java8 ArrayList源码阅读
转载自 java8 ArrayList源码阅读 本文基于jdk1.8 JavaCollection库中有三类:List,Queue,Set 其中List,有三个子实现类:ArrayList,Vecto ...
- JDK1.8源码阅读系列之四:HashMap (原创)
本篇随笔主要描述的是我阅读 HashMap 源码期间的对于 HashMap 的一些实现上的个人理解,用于个人备忘,有不对的地方,请指出- 接下来会从以下几个方面介绍 HashMap 源码相关知识: 1 ...
- 【JDK1.8】Java 8源码阅读汇总
一.前言 万丈高楼平地起,相信要想学好java,仅仅掌握基础的语法是远远不够的,从今天起,笔者将和园友们一起阅读jdk1.8的源码,并将阅读重点放在常见的诸如collection集合以及concu ...
- 【JDK1.8】JDK1.8集合源码阅读——HashMap
一.前言 笔者之前看过一篇关于jdk1.8的HashMap源码分析,作者对里面的解读很到位,将代码里关键的地方都说了一遍,值得推荐.笔者也会顺着他的顺序来阅读一遍,除了基础的方法外,添加了其他补充内容 ...
- 【JDK1.8】JDK1.8集合源码阅读——LinkedList
一.前言 这次我们来看一下常见的List中的第二个--LinkedList,在前面分析ArrayList的时候,我们提到,LinkedList是链表的结构,其实它跟我们在分析map的时候讲到的Link ...
随机推荐
- HUST 1407(数据结构)
1407 - 郁闷的小J 小J是国家图书馆的一位图书管理员,他的工作是管理一个巨大的书架.虽然他很能吃苦耐劳,但是由于这个书架十分巨大,所以他的工作效率总是很低,以致他面临着被解雇的危险,这也正是他所 ...
- 使用流的方式去进行post请求解决中文乱码问题返回xml格式
/** * 请求post * @Title: getHttpURLConnection * @Description: TODO(这里用一句话描述这个方法的作用) * @param: @param u ...
- 更新数据库中数据时出现: Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode, toggle the option in Preferences 问题
使用workbench在数据库中更新数据时报错: You are using safe update mode and you tried to update a table without a WH ...
- Java函数式接口Function
Function 提供了一个抽象方法 R apply(T t) 接收一个参数 返回 一个值,还有两个默认方法和一个静态方法 compose 是一个嵌套方法,先执行before.apply() 得到运 ...
- 选择器的使用(empty选择器)
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head><meta ...
- 断路器监控(Hystrix Dashboard)
继上一篇http://www.cnblogs.com/EasonJim/p/7613595.html介绍了断路器之后,其实它还提供了一个管理页面来监控这些应用的调用数据. 首先,我是基于上一个例子Zo ...
- 【SQL Server 学习系列】-- 随机生成日期时间的SQL脚本
DECLARE @dt1 DATETIME,@dt2 DATETIME,@a BIGINT,@b BIGINT SET @dt1='2010-01-01'--开始日期 SET @dt2='2010-0 ...
- HDU2577 How to Type【DP】
题目链接: pid=2577">http://acm.hdu.edu.cn/showproblem.php? pid=2577 题目大意: 给你一个仅仅包括大写和小写字母的字符串,如今 ...
- Zabbix 监控服务器
Zabbix 操作系统 :CentOS7.5 两台服务器: server端:192.168.206.6 client 端: 192.168.206.3 zabbix : 4.0 mariiadb : ...
- iOS下JSON反序列化开源库
iOS下JSON字符串反序列化成对象.在正式的项目中比較常见.例如以下几个经常使用开源库.能够依据个人喜好任选其一: 1. JSONModel: https://github.com/icanzilb ...