Re:prime 关于质数的算法
Re:prime 关于质数的所有算法
绪言
所有代码若无说明,均采用快读模板
关于质数,无非就两大类:
- 判断一个数字是不是质数
- 找出[1,n]中所有的质数
先讲1:
Judge
判断x是不是质数
根据质数的定义,我们可以枚举所有小于x,大于1的正整数i。如果x%i==0,即i是x的因数,则x不是质数。
很明显,一个质数的因数是成对出现,且分别在sqrt(x)的两边。所以只要枚举到sqrt(x)即可。
bool judge(LL & x)
{
if(x<2) return 0;
LL sq=sqrt(x);
for(re LL i=2;i<=sq;i++)
{
if(!(x%i)) return 0;
}
return 1;
}
时间复杂度O(sqrt(n))
那么,这里插一句嘴——只要再从1~n枚举一个数,不就可以得出1~n中所有的质数了嘛?!
(另外一种判断质数的方法等会再讲)
n=1.5*10^6
上面是指极限下1s能过的数据
bool judge(LL & x)//n=1.5*10^6 这里用IL反而会慢0.01s
{
if(x<2) return 0;
LL sq=sqrt(x);
for(re LL i=2;i<=sq;i++)
{
if(!(x%i)) return 0;
}
return 1;
}
LL n;
int main()
{
freopen("prime.in","r",stdin);
freopen("nsqrtn.out","w",stdout);
n=read();
for(re LL i=1;i<=n;i++)
{
if(judge(i)) write(i);
}
return 0;
}
时间复杂度O(nsqrt(n))
n=4*10^6
这里只要把上面的那个n=1.5*10^6做一个小小的优化(可以理解为记忆化)
其实,我们在尝试枚举因数的时候,我们可以只要枚举质因数就好。
比如x=91
如果我枚举到i=2(某个质数)发现不能整除,那么91当然也不能被2的倍数(质数的(2倍以上的)倍数是不是质数)整除啊
所以,judge()中的枚举i只需要枚举1~sqrt(x)中的质数即可。
使用一个数组存储所有的质数吧。
LL his[1000000];
LL size;
bool judge(LL & x)//n=4*10^6
{
if(x<2) return 0;
LL sq=sqrt(x);
for(re LL i=0;his[i]<=sq&&i<size;i++)
{
if(!(x%his[i])) return 0;
}
return 1;
}
LL n;
int main()
{
freopen("prime.in","r",stdin);
freopen("nsqrtnpro.out","w",stdout);
n=read();
his[size++]=2;
if(n>=2) write(2);
for(re LL i=3;i<=n;i++)
{
if(judge(i)) write(i),his[size++]=i;
}
return 0;
}
时间复杂度O(?)
接下来在看看
n=3*10^7
这次是埃氏筛(埃拉托斯特尼筛法)。
每找到一个质数,就将它的倍数打上标记即可。
如果循环到某个数的时候,它没有被打上标记
那么它就一定是质数了,
就再拿它去更新它的倍数。
bool book[30000000];
LL prime[30000000];
LL size;
LL n;
int main()//n=3*10^7
{
freopen("prime.in","r",stdin);
freopen("Eratosthenes.out","w",stdout);
n=read();
book[1]=1;
prime[size++]=2;
for(re LL i=2;i<=n;i++)
{
if(!book[i])
{
prime[size++]=i;
write(i);
for(re LL j=2;i*j<=n;j++)
{
book[i*j]=1;
}
}
}
return 0;
}
时间复杂度O(nloglogn),已经非常接近于线性的了

(注意,虽然它的图像在10000以内的斜率看似比y=x还要小,但是我们比较的是其增长性,即:nloglogn的导数是单调递增的)

可能一阶导看不出来
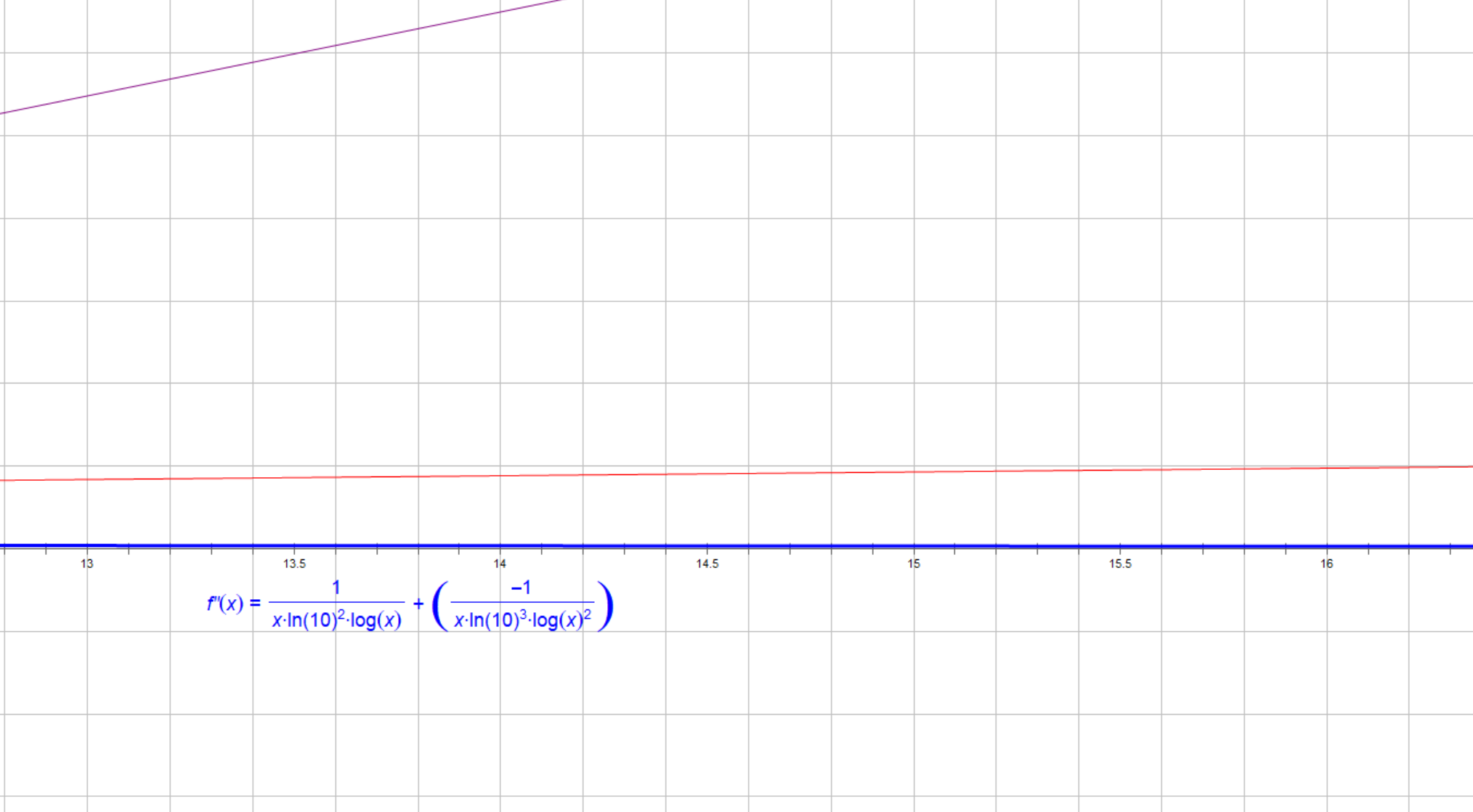
紫色:nloglogn
红色:f'(x)
蓝色:f''(x)
好了,不管那么多了,再看这次最强的筛法:欧拉筛 吧
n=3*10^7(***)
请先思考一下
为什么埃氏筛会超过线性呢?
因为其实,一个合数可能会被打上多次的合数标记
比如,枚举到2是质数的时候,会把4、6、8、10……打上标记
枚举到3是质数的时候,会把6、9、12……打上标记
然后6就被打了两次标记。
有一个更加严重的例子,一些合数甚至被打了很多次,这就浪费了很多次的机会,比如60
60这个数字被它的质因数们:2、3、5打了标记
而510510被它的质因数们:2、3、5、7、11、13、17打了标记。。。
浪费的时间就在这里了。。。
那么,欧拉筛:
#define MAXN 50000000
LL prime[MAXN];
bool book[MAXN];
LL n,size;
int main()
{
freopen("prime.in","r",stdin);
freopen("Euler.out","w",stdout);
n=read();
prime[size++]=2;
book[1]=1;
for(re LL i=2;i<=n;i++)
{
if(!book[i]) prime[size++]=i,write(i);
for(re LL j=0;j<size&&i*prime[j]<=n;j++)
{
book[i*prime[j]]=1;
if(i%prime[j]==0) break;
}
}
return 0;
}
一样的套路。
首先一定要记忆化(保存prime数组)
其次无论当前的数是不是质数都要用这个数字i向后筛
但是仅仅筛到i%prime[j]==0,即i可以被从小到大的某个质数整除为止。
所以,对于一个i,第二层for仅仅会筛到它的最小质因数倍的i
即比如i=5,就只会筛走2*5,3*5,5*5(然后5%5==0 -> break;)
所以每个数只会被它的最小质因数筛——只会被筛一遍
所以它的时间复杂度是O(n)的
如果你还是不信:


#define MAXN 50000000
LL prime[MAXN];
bool book[MAXN];
LL n,size;
int main()
{
// freopen("prime.in","r",stdin);
// freopen("Euler.out","w",stdout);
n=read();
prime[size++]=2;
book[1]=1;
for(re LL i=2;i<=n;i++)
{
if(!book[i]) prime[size++]=i,write(i);
for(re LL j=0;j<size&&i*prime[j]<=n;j++)
{
book[i*prime[j]]=1;
cout<<i<<" "<<i*prime[j]<<endl;
if(i%prime[j]==0) break;
}
}
return 0;
}
验证

被筛的数字是不会相同的。
咦?那这个算法1s极限怎么和高贵的埃氏筛相差无几(明明是根本一样好吧!)啊~
因为它有一定的常数(用到了取模),还一定要保存质数(这个影响不大)
但是,在更大的数据下,欧拉筛才能展现出其真正的魅力!
比如说这个数据:
200'000'000(2*10^8,两亿)
看上去就很不错
用埃氏筛来跑,需要3.682s左右
但是用欧拉筛,只需要2.943s左右!
(以上数据为无输出数据,且仅用于对比,无实际意义)
所以以后考试的时候还是打埃氏筛吧——又简单常数又小!
最后——
Miller·Rabin
快速的大质数判断,基于随机算法。
可以在O(klogn)内判断一个数字是不是质数,其中k为判断的次数(稍后你就懂了),n是这个数字的大小。
我不太懂它的证明过程,但是我觉得我这么菜,只要会用就好了……
以下是步骤:
- f是一个小质数,a是要测试的数字,d=a-1
- 去除d的因数2(即把d除以二直到d变成奇数)
- 计算t=f^d%a(快速幂)
- 循环{d/=2;t*=t;t%a;}直到d=a-1或t=1或t=a-1
- 这时如果t==a-1或者d是奇数,那么可以粗劣地判断a是质数
- 多选几个f判断,同时满足的话,就可以说是质数了
Re:prime 关于质数的算法的更多相关文章
- [LeetCode] Prime Palindrome 质数回文数
Find the smallest prime palindrome greater than or equal to N. Recall that a number is prime if it's ...
- POJ 3126 Prime Path(BFS算法)
思路:宽度优先搜索(BFS算法) #include<iostream> #include<stdio.h> #include<cmath> #include< ...
- POJ2689 Prime Distance 质数筛选
题目大意 求区间[L, R]中距离最大和最小的两对相邻质数.R<2^31, R-L<1e6. 总体思路 本题数据很大.求sqrt(R)的所有质数,用这些质数乘以j, j+1, j+2... ...
- SPFA,dijskra,prime,topu四种算法的模板
////#include<stdio.h> ////#include<string.h> ////#include<queue> ////#include<a ...
- BZOJ3070 : [Pa2011]Prime prime power 质数的质数次方
对于$a^b$,如果$b=2$,那么在$[\sqrt{n},\sqrt{n}+k\log k]$内必定能找到$k$个质数作为$a$. 筛出$n^{\frac{1}{4}}$内的所有质数,暴力枚举所有落 ...
- 【Java算法】求质数的算法
计算100以内的质数 1.质数:大于1的整数中,只能被自己和1整除的数为质数. 如果这个数,对比自己小1至2之间的数字,进行求余运算,结果都不等于0,则可以判断该数为质数. public class ...
- 最小生成树之算法记录【prime算法+Kruskal算法】【模板】
首先说一下什么是树: 1.只含一个根节点 2.任意两个节点之间只能有一条或者没有线相连 3.任意两个节点之间都可以通过别的节点间接相连 4.除了根节点没一个节点都只有唯一的一个父节点 5.也有可能是空 ...
- 最小生成树(prime算法 & kruskal算法)和 最短路径算法(floyd算法 & dijkstra算法)
一.主要内容: 介绍图论中两大经典问题:最小生成树问题以及最短路径问题,以及给出解决每个问题的两种不同算法. 其中最小生成树问题可参考以下题目: 题目1012:畅通工程 http://ac.jobdu ...
- [ACM训练] 算法初级 之 搜索算法 之 广度优先算法BFS (POJ 3278+1426+3126+3087+3414)
BFS算法与树的层次遍历很像,具有明显的层次性,一般都是使用队列来实现的!!! 常用步骤: 1.设置访问标记int visited[N],要覆盖所有的可能访问数据个数,这里设置成int而不是bool, ...
- hash算法总结收集
hash算法的意义在于提供了一种快速存取数据的方法,它用一种算法建立键值与真实值之间的对应关系,(每一个真实值只能有一个键值,但是一个键值可以对应多个真实值),这样可以快速在数组等条件中里面存取数据. ...
随机推荐
- surpac 中如何删除点
找到显示的编号 输入线窜线段编号
- TSP问题的不可近似性
\(\S\) 结论 TSP问题:n阶带权无向完全图中,找权值最小的哈密顿回路(无向图中遍历所有顶点的回路) 优化问题,记最优解为OPT 对于一般的n顶点TSP问题(非Metric),任意 多项式时间内 ...
- Web前端入门第3问:前端需要学习哪些技术?
Web前端开发技术学习路径 基础知识 必备 HTML+CSS+JavaScript ,就目前来看,这三板斧是入门前端开发的门槛,无论如何都是逃不掉了. 进阶知识 必须会一门主流的前端框架,比如:Rea ...
- Visio绘制时间轴安排图的方法
本文介绍基于Visio软件绘制时间轴.日程安排图.时间进度图等的方法. 在很多学习.工作场合中,我们往往需要绘制如下所示的一些带有具体时间进度的日程安排.工作流程.项目进展等可视化图表. ...
- k8s DCGM GPU采集指标项说明
dcgm-exporter 采集指标项 https://help.aliyun.com/document_detail/433222.html#section-oin-6mf-6j0 指标 解释 dc ...
- 使用SVM在数字验证码识别中的应用研究课程报告
第1章 概要设计 1.1 设计目的 支持向量机作为一类强大的监督学习模型,以其出色的泛化能力,在手写数字识别.面部检测.图像分类等多个领域展现出了其优越性.其在处理小样本.非线性及高维模式识别任务中表 ...
- selenium自动化测试-获取动态页面小说
有的网站页面是动态加载的资源,使用bs4库只能获取静态页面内容,无法获取动态页面内容,通过selenium自动化测试工具可以获取动态页面内容. 参考之前的"bs4库爬取小说工具"文 ...
- 业余无线电爱好者,自制天线比较容易上手天线“莫克森天线”Moxon
本文仅作为笔记分享,如有疑问可以留言交流. 莫克森天线尺寸计算软件:Moxon rectangle 高手门做的成品,参考资料: 英文文献资料:
- 常见的 AI 模型格式
来源:博客链接 过去两年,开源 AI 社区一直在热烈讨论新 AI 模型的开发.每天都有越来越多的模型在 Hugging Face 上发布,并被用于实际应用中.然而,开发者在使用这些模型时面临的一个挑战 ...
- php文件和文件夹操作类
文件和文件夹操作 移动 | 复制 | 删除 | 重命名 | 下载 <?php namespace Framework\Tools; use PharData; class FileManager ...