pyspark遇到报错:_PYSPARK_DRIVER_CONN_INFO_PATH
1. 环境 : centos,启动pyspark,执行如下python命令:
import pyspark
from pyspark import SparkContext
from pyspark import SparkConf
conf=SparkConf().setAppName("miniProject").setMaster("local[*]")
sc=SparkContext.getOrCreate(conf) #flatMap() 对RDD中的item执行同一个操作以后得到一个list,然后以平铺的方式把这些list里所有的结果组成新的list
sentencesRDD=sc.parallelize(['Hello world','My name is Patrick'])
wordsRDD=sentencesRDD.flatMap(lambda sentence: sentence.split(" "))
print (wordsRDD.collect())
print (wordsRDD.count())
用root账号没问题:
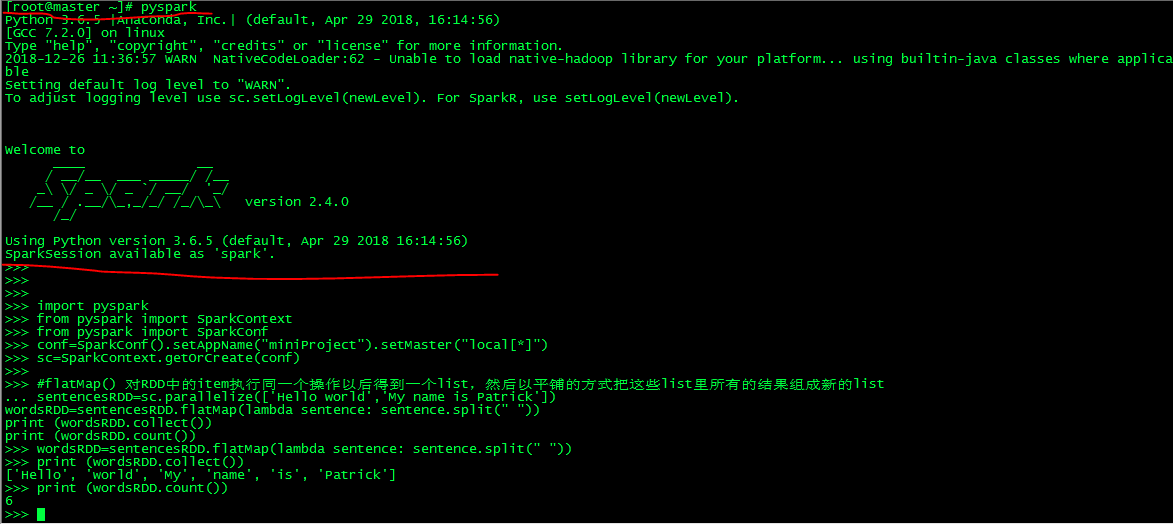
用非root账号会有此问题如下:_PYSPARK_DRIVER_CONN_INFO_PATH,后台设置下/etc/profile 中环境变量可以了。
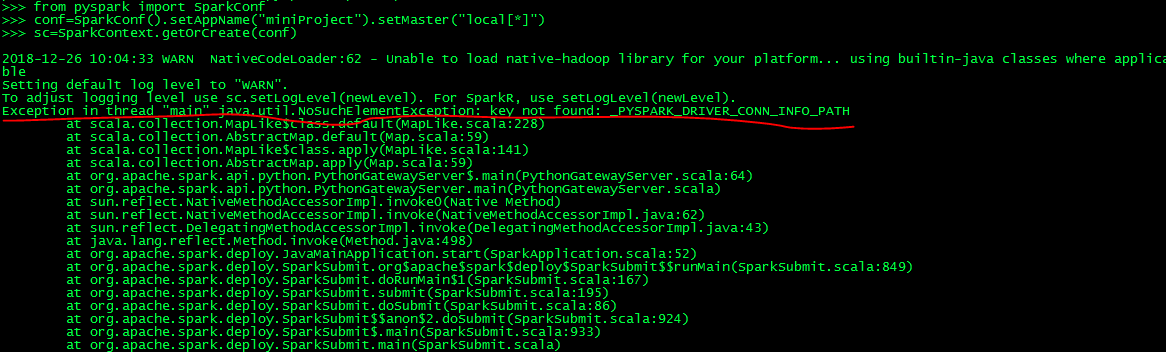
vi /etc/profile 加入: ,source /etc/profile
,source /etc/profile
2. 后来在 jupyter notebook远程登录后(非root账号),发现还是有这个问题。(其实就是环境变量没有加载完全。)
解决方法在脚本开头加入:
#jupyter需要初始化pyspark相关环境变量
import findspark
findspark.init()
import os,sys
os.environ['SPARK_HOME'] = "/bin/spark-2.4.0"
sys.path.append("/bin/spark-2.4.0/python")
sys.path.append("/bin/spark-2.4.0/python/lib/py4j-0.10.7-src.zip")
pyspark遇到报错:_PYSPARK_DRIVER_CONN_INFO_PATH的更多相关文章
- linux服务器配置pyspark解决py4j报错等问题
1.下载spark,python包 略 2.环境变量配置 打开 ~/.bashrc配置文件 如图添加下列环境变量及path 3.退出配置文件,输入 source ~/.bashrc 来执行你添加的一些 ...
- pyspark报错Exception: Java gateway process exited before sending its port number解决方法
1.问题 搭建spark的python环境好后简单使用,源代码如下: 然后就给我丢了一堆错误: 2.解决办法 这里指定一下Java的环境就可以了,添加代码: import os os.environ[ ...
- filebeat+kafka+SparkStreaming程序报错及解决办法
// :: WARN RandomBlockReplicationPolicy: Expecting replicas with only peer/s. // :: WARN BlockManage ...
- Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient报错,问题排查
背景 最近在整合pyspark与hive,新安装spark-2.3.3以客户端的方式访问hive数据,运行方式使用spark on yarn,但是在配置spark读取hive数据的时候,这里直接把hi ...
- Windows 7上执行Cake 报错原因是Powershell 版本问题
在Windows 7 SP1 电脑上执行Cake的的例子 http://cakebuild.net/docs/tutorials/getting-started ,运行./Build.ps1 报下面的 ...
- 关于VS2015 ASP.NET MVC添加控制器的时候报错
调试环境:VS2015 数据库Mysql WIN10 在调试过程中出现类似下两图的同学们,注意啦. 其实也是在学习的过程中遇到这个问题的,找了很多资料都没有正面的解决添加控制器的时候报错的问题,还是 ...
- php报错 ----> Call to undefined function imagecreatetruecolor()
刚才在写验证码的时候,发现报错,然后排查分析了一下,原来是所用的php版本(PHP/5.3.13)没有开启此扩展功能. 进入php.ini 找到extension=php_gd2.dll ,将其前面的 ...
- scp报错 -bash: scp: command not found
环境:RHEL6.5 使用scp命令报错: [root@oradb23 media]# scp /etc/hosts oradb24:/etc/ -bash: scp: command not fou ...
- VS2015使用scanf报错的解决方案
1.在程序最前面加: #define _CRT_SECURE_NO_DEPRECATE 2.在程序最前面加: #pragma warning(disable:4996) 3.把scanf改为scanf ...
随机推荐
- C# winform C/S WebBrowser 微信第三方登录
网上很多的资料都是B/S结构的,这里是基于C# C/S 结构的微信第三方授权登录 一.准备知识 1 http Get和Post方法.做第三方授权登录,获取信息基本上都是用get和post方法,做之前需 ...
- STM32 一直进入串口接收中断
解决方法一: .串口初始化配置时,需要打开ORE 溢出中断,否则串口中断没有及时读取数据会触发溢出中断(打开接收中断默认开启溢出中断,但是为了读取溢出标志位还需要明确执行以下打开溢出中断),如果没有清 ...
- mui dtpicker 时间的设置 以及MUI的弹窗
1)引入mui.min.css,然后引入mui.picker.min.css 注意这个mui.picker.min.css 与 mui.picker.css 不一样 2)引入 ...
- 内置窗口 pyqt5
1.使用Qt Designer设计三个窗口 注意:在主窗口中需要添加一个girdLayout 2.创建**.py from PyQt5.QtWidgets import QMainWindow, QA ...
- php脚本#!/usr/bin/env php 写法
脚本语言的第一行,目的就是指出,你想要你的这个文件中的代码用什么可执行程序去运行它. 比如php脚本的第一行可以写成如下几种格式 #!/usr/bin/php #!/usr/bin/env php # ...
- 网络编程基础【day09】:解决socket粘包之大数据(七)
本节内容 概述 linux下运行效果 sleep解决粘包 服务端插入交互解决粘包问题 一.概述 刚刚我们在window的操作系统上,很完美的解决了,大数据量的数据传输出现的问题,但是在Linux环境下 ...
- C#复习正则表达式
由于前段时间为了写工具学的太J8粗糙 加上最近一段时间太浮躁 所以静下心来复习 一遍以前学的很弱的一些地方 1 委托 public delegate double weituo(double a, d ...
- Cannot send, channel has already failed: tcp://127.0.0.1:8161
解决方案一 我觉得你可能需要把服务完全停掉了 然后重启一下. http://localhost:8161(管理端口) tcp://127.0.0.1:61616(服务端口)
- QT_地图导航 源码下载
https://github.com/douzujun/MyMapView 主要算法讲解: 1. 计算最短路径(dijkstra算法) Step1: (1)找到最短路径已经确定的顶点,从它已经确定的顶 ...
- 解决audio和video在手机端无法自动播放问题
各大浏览器都为了节省流量,做出了优化,在用户没有行为动作时(交互)不予许自动播放 <audio src="music/bg.mp3" autoplay loop contro ...