用浏览器控制台抓取shodan、搜索引擎、zone-h的结果
0x00 前言
大部分内容来自参考连接的内容,只是一种爬取内容的思路。
在很久以前自己会有爬取zone-h做目标测试的需求,但是总是有各种反爬限制。而且个别网址还有前端自动生成内容的功能,使用JavaScript可以很方便的让我们得到自己想要得结果做数据整理。
- 会用到DOM属性如下:
document.getElementsByClassName() 返回文档中所有指定类名的元素集合,作为 NodeList 对象。
document.getElementById() 返回对拥有指定 id 的第一个对象的引用。
document.getElementsByName() 返回带有指定名称的对象集合。
document.getElementsByTagName() 返回带有指定标签名的对象集合。
- js截取指定字符前面或后面的内容
function getCaption(obj,state) {
var index=obj.lastIndexOf("\-");
if(state==0){
obj=obj.substring(0,index);
}else {
obj=obj.substring(index+1,obj.length);
}
return obj;
}
var data = 'aaa-bbb'
//截取符号前面部分
getCaption(data,0) //输出aaa
//截取符号后面部分
getCaption(data,1) //输出bbb
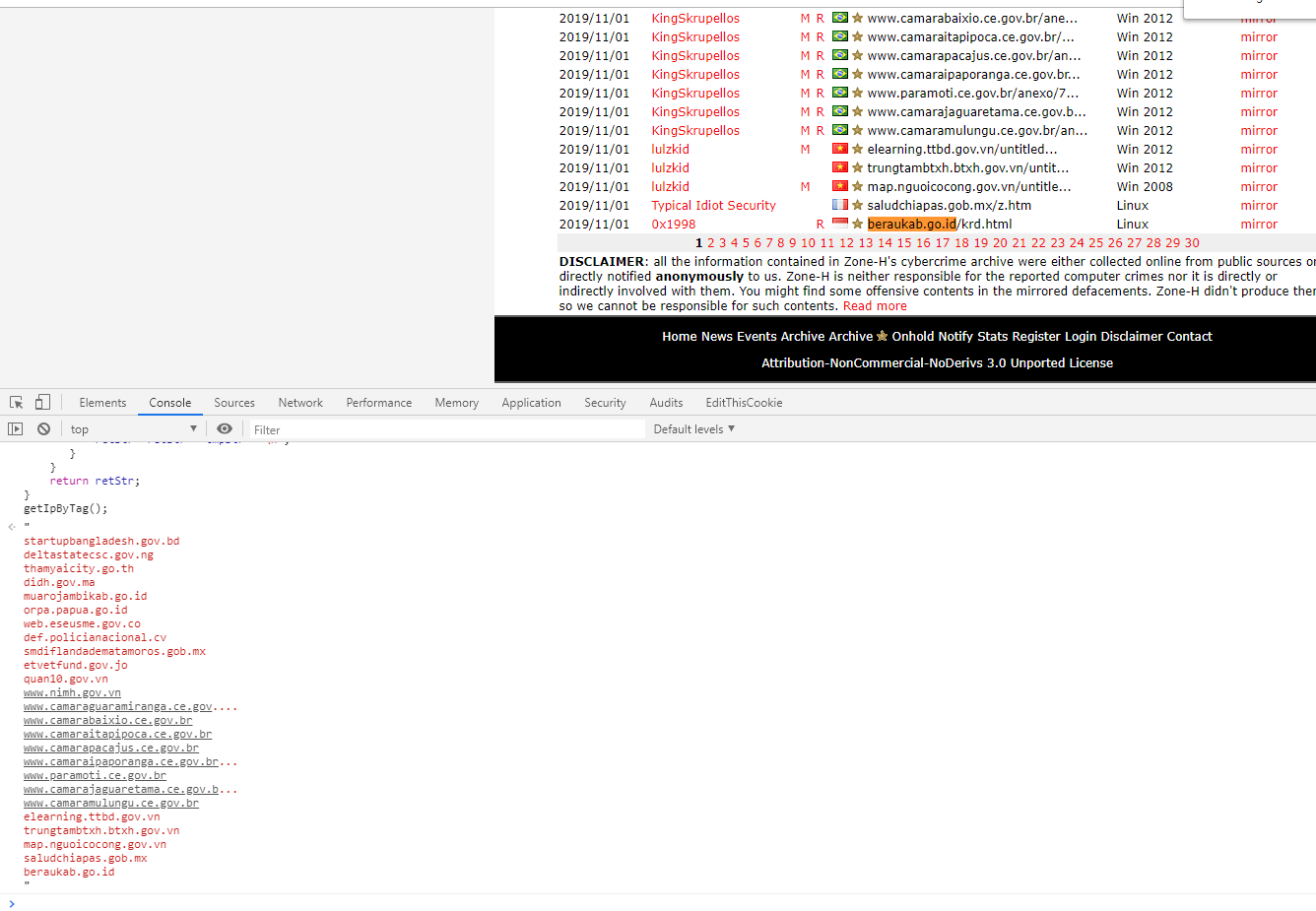
0x01 提取zone-h结果
function getIpByTag(){
var trVal = document.getElementsByTagName("tr");
var retStr="\n";
var tmpStr="";
for(var i=1;i< trVal.length-4;i++)
{
tmpStr = trVal[i].getElementsByTagName('td')[7].innerHTML.trim();
var index = tmpStr.indexOf('/');
if(index>0)
{
retStr= retStr + tmpStr.substring(0,index) + "\n";}
else
{
retStr= retStr + tmpStr+ "\n";
}
console.log(i,tmpStr)
}
return retStr;
}
getIpByTag();
0x02 提取Shodan结果ip
Shadan
//方法1:获取标签提取
console.log(document.getElementsByClassName("ip")[0].firstChild.innerHTML)
function getIpByTag()
{
var ip = document.getElementsByClassName("ip");
var str = "\n";
for(var i=0; i < ip.length; i++)
{
var node = ip[i].firstChild;
str = str + node.innerHTML + "\n";
}
return str;
}
getIpByTag();
//方法2:正则提取
function getIpByTag(){
var tag = document.getElementsByClassName("span9")[0];
var re = new RegExp();
var str = tag.innerHTML;
var re = /\d+\.\d+\.\d+\.\d+/g;
var arr = str.match(re);
console.log(arr);
//数组去重
arr.sort();
for(var i = 0; i < arr.length-1;) {
//用当前的元素与他的前一个元素进行对比
if(arr[i] == arr[i + 1]) {
//如果相同的话,就删除掉第i个元素
arr.splice(i, 1);
}else{ i++;}
}
console.log(arr);
0x03 抓取Google结果
Google
console.log(document.getElementsByClassName("r")[0.].firstChild.href)
function getIpByTag()
{
var r = document.getElementsByClassName("r");
var str = '\n';
for(var i=0;i< r.length;i++)
{
str = str + r[i].firstChild.href + '\n';
}
return str;
}
getIpByTag();
0x04 提取百度结果
Baidu
console.log(document.getElementsByClassName("t")[0].getElementsByTagName('a')[0].href)
function getIpByTag()
{
var t = document.getElementsByClassName("t");
var str = '\n';
for(var i=0;i< t.length;i++)
{
str = str + '"' + t[i].getElementsByTagName('a')[0].href + '",\n';
}
str = str.substring(0,str.length-2)
str = str + '\n'
return str;
}
getIpByTag();
将百度加密后的url转成真正的地址:
import requests
urlList = [
"http://www.baidu.com/link?url=M1SN1OPmF9xM43i4jwjeDVvn-uD-i7xOf1nDxZDdIh4iCQRPXnmJnpzEFaRpcLNbSzXJGnlGiRClt_kX_KjXo_",
"http://www.baidu.com/link?url=9J00kAi9Fu07zxr4q4v_WZ2b0lW6WM-eIuzzcRtKQSS8Hd2u7hqAyBYyDOm1JbAwGgrUAubK8cR3V2_7RFJ1j_",
"http://www.baidu.com/link?url=kJuAmhEDNtu9VT5tpF_Grdi5fv246Dyf6ESnWqyBrR9HZD8BniQXVqOEinUox_hn",
"http://www.baidu.com/link?url=9Zlb9C0SnpP01To84341TBe2Tr1888CY8vkv86ZJAB94GoDO0II9m19lJpAKmSlm",
"http://www.baidu.com/link?url=e-jNCpBOgKCFOAGakRSt7jsqeKM4Z7kAKxmzFXyizOybrMP3Ig5MVmIHd6cwgsug",
"http://www.baidu.com/link?url=mhPGHLye4mCUdZOKGZz-RY_d7vzNThy_ifVZ8qGpAkvEGYUspJKT5wvHX0LSvPVd",
"http://www.baidu.com/link?url=NOw1rL9Juxdl-_FYexMJq8n1I3vliWRPjMAVZT8YQ-S9nHOXn-EuI8YnIz6-8EXF",
"http://www.baidu.com/link?url=3iCH4yJeE6UA_Pura3WMiNcoLBOYKePK0teNAwELb3667oy-RXOSuanprur6GjUN",
"http://www.baidu.com/link?url=w_7v1e_uvw8YSQyZEA-SN1vnIIljpmknKaVLTtdZqxM8qLXi0C0LwLAUQJyrZYTY8aU4DjPnXtQeUQlP-zqzXK",
"http://www.baidu.com/link?url=DjXRm8KwbnSAOaPtt3NtR7XzwCnWizbgJDxeC9DPB0GBeSJIiYb2ObZHQ5mLsYjP"
]
for someurl in urlList:
response = requests.get(someurl)
if response.history:
print(response.url)
else:
print("Request was not redirected")
参考
[1] 使用Chrome console提取页面数据
https://www.cnblogs.com/liun1994/p/7265828.html
[2] Google浏览器URL采集的一种思路
https://blog.csdn.net/qq_29647709/article/details/84379170
[3] 使用浏览器控制台抓取信息
https://lufe1.cn/2017/09/20/使用浏览器控制台抓取信息/
[4] js截取指定字符前面或后面的内容
https://blog.csdn.net/caiyongshengCSDN/article/details/88420416
用浏览器控制台抓取shodan、搜索引擎、zone-h的结果的更多相关文章
- python+selenium+chromedriver抓取shodan搜索结果
作用:免积分抓取shodan的搜索结果,并把IP保存为txt 前提: ①shodan会员(ps:黑色星期五打折) ②安装有python27 ③谷歌浏览器(ps:版本一定要跟chromedriver匹配 ...
- jmeter旅程第一站:Jmeter抓包浏览器或者抓取手机app的包
学习jmeter?从实际出发,我也是一个初学者,会优先考虑先用来做一些简单的抓包.接口测试,在实践的过程中学习jmeter用途.那么接下来,这篇文章我会以jmeter抓包开启我的jmeter旅程. 这 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- [安全]appscan 使用代理抓取其他客户端的请求
自己安全测试技能很低, 上级给的安全测试的任务给了自动化组的同事来做, 自己之前使用appscan的时候 只知道使用appscan的内置浏览器测试抓取请求 今天与自动化美女同事沟通发现有一个代理的功能 ...
- 强大的chrome(1)以acfun为例抓取视频
chrome很强大,很强大,很强大. 想要了解他的强大呢,就先要掌握一些基本的chrome命令. 1. chrome://flags 可用来启用或者关闭某些chrome的体验特性 2. chr ...
- 如何让搜索引擎抓取AJAX内容? 转
越来越多的网站,开始采用"单页面结构"(Single-page application). 整个网站只有一张网页,采用 Ajax 技术,根据用户的输入,加载不同的内容. 这种做法的 ...
- 如何让搜索引擎抓取AJAX内容?
越来越多的网站,开始采用"单页面结构"(Single-page application). 整个网站只有一张网页,采用Ajax技术,根据用户的输入,加载不同的内容. 这种做法的好处 ...
随机推荐
- html5添加视频为背景自动播放
客户想做个打开官网自动播放一段视频,楼主使用了video标签,即下面的代码:: 于是我在video标签上添加了属性 autoplay=“autoplay” loop=“loop” 然而通过地址栏进去的 ...
- MP4文件批量转码成MP3
需求背景:最近为了学python爬虫,在论坛里找了不少视频教程,非常棒.但有时看视频不方便,就想着能否把视频批量转码成音频,这样在乘坐地铁公交的时候也能学习了. 解决路径:有了需求,我首先在论坛里搜了 ...
- 11.vue-router编程式导航
页面导航的两种方式 声明式导航:通过点击链接实现导航的方式,叫做声明式导航 例如:普通网页中的链接或vue中的 编程式导航:通过调用JavaScrip形式的API实现导航的方式,叫做编程式导航 例如: ...
- 机房断电,导致xfs文件系统损坏
记一次机房断电,导致xfs文件系统损坏处理方法 挂载时报以下错误: mount: mount /dev/sdb on /dev/sdb failed: Structure needs cleaning ...
- 让更多浏览器支持html5元素的简单方法
当我们试图使用web上的新技术的时候,旧式浏览器总是我们心中不可磨灭的痛!事实上,所有浏览器都有或多或少的问题,现在还没有浏览器能够完整的识别和支持最新的html5结构元素.但是不用担心,你依然可以在 ...
- 4-html图片与链接
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- git工具免密拉取、推送
很苦恼每次都要配置明文密码才能正常工作 其实也可以配置成非明文 打开控制面板 →用户账号 管理 Windows凭证 对应修改响应网址即可
- selenium原理解析
相信很多测试小伙伴儿都听过或者使用过web自动化selenium,那您有没有研究过selenium的原理呢?为什么要使用webdriver.exe,webdriver.exe是干啥用的?seleniu ...
- 学到了林海峰,武沛齐讲的Day49 django
django 终于等到啦,好东西上场了 blog---- 个体应用文件 model.py 数据库文件 views.py 视图文件 admin.py 后台文件,操纵数据库文件 manage.py --- ...
- 金字塔原理(Pyramid Principle)
什么是金字塔原理?简单来说,金字塔原理就是“中心论点---分论点---支撑论据”这样的一个结构. 图片摘自:http://www.woshipm.com/pmd/306704.html 人类通常习惯于 ...