项目架构&架构部署&网站分析&网站优化
一、架构演变
一个项目至少由三层内容组成:web访问层、数据库层、存储层
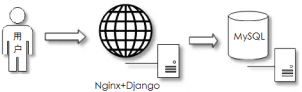
初级阶段
单体阶段
常见场景:项目初期
部署特点:所有应用服务都在一台主机
应用特点:开发简单
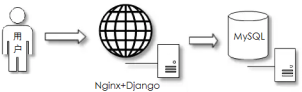
应用/数据分离阶段
常见场景:项目初期,用户访问数据库有压力
部署特点:应用和数据库单独部署
应用特点:开发简单
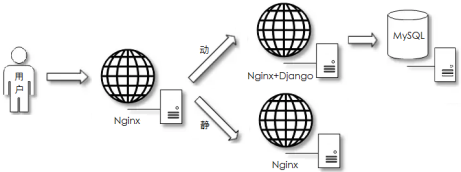
页面动静分离阶段
常见场景:项目初期,用户访问页面有压力
部署特点:剥离用户读请求和写请求操作
应用特点:开发简单
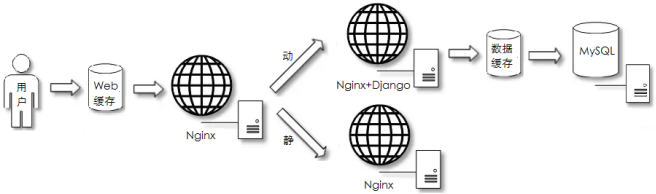
页面/数据缓存阶段
常见场景:项目初期,用户访问有压力
部署特点:代理和数据库前面增加缓存组件
应用特点:开发简单
中期阶段
应用服务集群阶段
常见场景:项目初期,用户访问有压力
部署特点:应用服务所在主机做集群负载均衡
应用特点:业务中等
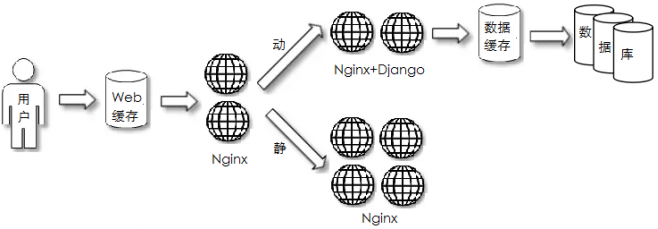
数据库读写分离化
常见场景:项目初期,用户访问数据有压力
部署特点:对数据库集群做读写分离,静态文件做共享存储
应用特点:业务中等
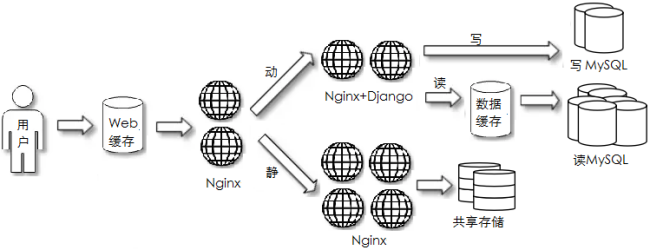
存储分布式
常见场景:项目中期,数据存储有压力
部署特点:对数据库分库/分表扩展,数据文件使用分布式存储
应用特点:业务中等
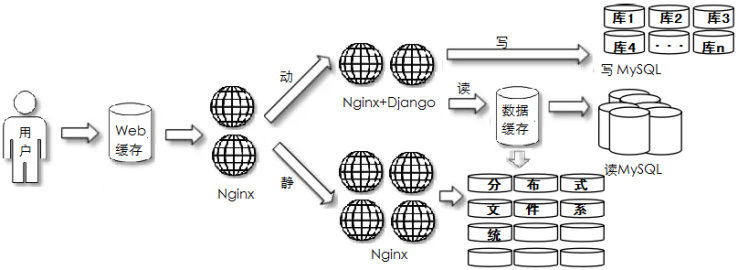
业务应用拆分
常见场景:项目中期,业务访问/团队管理有压力
部署特点:项目应用进行拆分
应用特点:业务复杂
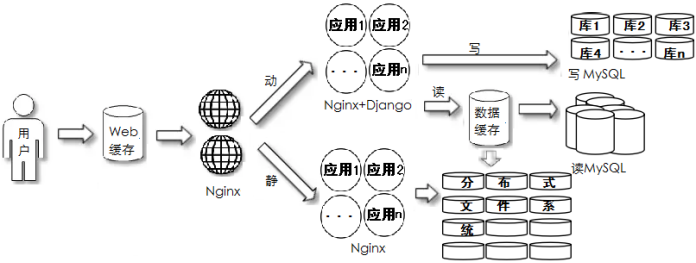
中后期阶段
业务拆分
常见场景:项目中后期,业务处理有压力
部署特点:所有功能以服务形式单独部署,引入配置管理管理中心、消息中间件,搜索引擎等功能
应用特点:业务复杂
微服务阶段
常见场景:项目后期,精益求精
部署特点:所有服务都可以自由部署
应用特点:业务复杂
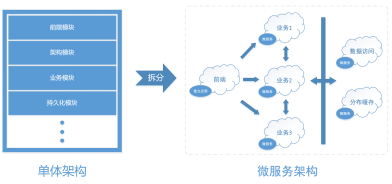
二、架构部署
通用架构

一级定位:核心组成部分
web 、数据库、存储层
二级定位:功能增强部分
web缓存、代理、数据库缓存
部署项目
部署项目时,遵循主次原则:
- 架构层中的一级角色,部署原则是:站在用户访问资源角度,从后向前依次部署。
- 架构层中的二级角色,部署原则是:站在用户访问资源压力角度,需要部署哪里,就部署哪里,注意前后的信息交流。
三、网站分析
IP: 独立IP数,指一天内使用不同IP地址的用户访问网站的数量。
特点:同一个IP无论访问多少网页,独立IP数均为1
PV:Page view页面浏览量,指一天内网站的浏览次数,它是衡量网站用户访问页面的数量。
特点:用户每打开一个页面就记录一次,就算访问同一页面多次,就记录多次
UV:Unique Visitor 访问网站的用户,指一天内访问某站点的人数,以cookie/客户端为依据
特点:一天内,同一访问用户的多次访问只记录1次
VV:Visit View 用户访问网站次数,指一天内某个用户访问了多少次网站
特点:打开网页A,浏览完毕后关闭该页面,表示一次访问
BR:Bounce Rate 跳出率,指一天内访问用户中,用户打开网站后没有做任何事情,一会就离开了的比例
特点:如果跳出率很高,说明我们的网页没有什么吸引力,网页设计效果不怎么好
CR:Conversion Rate 转化率,指一天内访问用户中,打开网站后,继续浏览该网站其他页面的比例
特点:转化率一般体现在项目的关键流程的部分,而它对网站的某些关键流程优化是一个很重要的直播
常见分析工具:服务器服务日志、公司内部监控平台、互联网网站分析工具包括站长工具、百度统计、云平台监控等
四、网站优化
缓存层方面
问题描述:
怎么在现有的主机资源情况下,花最小的代价抗住大量的用户访问量?
解决思路:
最常见的是自建Web缓存,或者购买CDN,将用户经常访问的、更新频率低的资源存放起来,这样用户再次请求相同资源的时候,就不会对后端的服务造成影响。若要防止互联网上的恶意访问/爬虫,应该做好相应的安全措施。缓存之类的措施一定要适合公司的当前业务,如果是项目的静态资源很多,只要购买的CDN足够好,就能抗住足够的用户访问量。
代理层方面
问题描述:
如何提高用户高质量的请求分发。
解决思路:
以Nginx代理为例,提高用户高质量的请求分发,最好的方法就是基于请求的关键字进行合理的分流。
基于请求的IP地址信息,封闭恶意IP访问,提高正常IP用户访问效率
基于请求的浏览器信息,分发到相应的后端应用,
基于请求的协议方法,做好读写分离业务的精确分流,
基于请求的路径信息,做好指定业务的精确分流,
问题描述:
对于前端使用nginx进行代理的项目,会随着功能的层层迭代逐渐增加数十个upstream,location规则的数量有可能达到数百个,这个时候偶尔有些 URL 会出现 404 的问题,对于这种情况怎么办?
解决思路:
1 按照功能描述,将upstream拆分到不同的功能目录中
2 对location的匹配规则尽量描述清楚,特别是匹配的location_match,最好使用^/$来锚定首尾字母
项目后端web访问
问题描述:
关于动态web请求过多,压力有些大,常见的解决方法有哪些?
解决思路:
首先分析动态的web请求主要的瓶颈点在哪里,是请求量大,还是数据访问大
请求量大:Web缓存/CDN,或者动态web集群可以考虑一下
数据库操作多:分析请求内容是否频繁/集中,是,页面静态化考虑一下;否,参看数据库的演变思路
如何提高静态web资源的访问质量?结合前段缓存的功能,在代码或者代理部分设置合理的资源缓存过期时间,定时/实时推送相关信息到前段的缓存层。
数据层方面
问题描述:
用户访问数据有压力
解决思路:
对于热点数据读取频繁的话,可以考虑前端数据缓存、分部数据缓存、优化查询搜索等方法
对于数据频繁写入压力的话,可以考虑数据库集群、读写分离、分库分表、增加数据管理层等方法
开发角度:关注数据库表的设计,表的索引合理、查询的时候,尽量使用条件查询
存储层方面:
问题描述:
如何保证我们数据存储的质量
解决思路:
存储设备的购买质量、分布式存储、备份策略
项目架构&架构部署&网站分析&网站优化的更多相关文章
- Weapsy 分析网站架构
Weapsy 分析(一)网站架构 这个项目看了好久了,但是老没时间写一些分析心得.下班后想了想,事情也不能老拖着,还是得做. 如图所示:Weapsy由5个项目所组成,有点可惜了,没有测试的项目,说明一 ...
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 九.LNMP网站架构实践部署
期中集群架构-第九章-期中架构LNMP章节====================================================================== 01. LNMP ...
- b2c项目基础架构分析(一)b2c 大型站点方案简述 已补充名词解释
我最近一直在找适合将来用于公司大型bs,b2b b2c的基础架构. 实际情况是要建立一个bs架构b2b.b2c的网站,当然还包括wap站点.手机app站点. 一.现有公司技术人员现状: 1.熟悉asp ...
- Windows Azure 入门 -- VS 2015部署 ASP.NET网站(项目) 与 数据库
Windows Azure 入门 -- 部署 ASP.NET网站(项目) 与数据库 https://www.dotblogs.com.tw/mis2000lab/2015/12/24/windowsa ...
- 大型Java Web项目的架构和部署问题
一位ID是jackson1225的网友在javaeye询问了一个大型Web系统的架构和部署选型问题,希望能提高现有的基于Java的Web应用的服务能力.由于架构模式和部署调优一直是Java社区的热门话 ...
- CssStats – 分析和优化网站 CSS 代码的利器
CssStats 是一个在线的 CSS 代码分析工具,你只需要输入网址或者直接 CSS 地址即可进行 CSS 代码的全方位分析,是前端开发人员和网页设计师分析网站 CSS 代码的利器,可以统计出 CS ...
- 分享一个大型进销存供应链项目(多层架构、分布式WCF多服务器部署、微软企业库架构)
项目源码下载: WWW.DI81.COM 分享一个大型进销存供应链项目(多层架构.分布式WCF多服务器部署.微软企业库架构) 这是一个比较大型的项目,准备开源了.支持N家门店同时操作.远程WCF+企 ...
- Equinox开源项目CQRS架构分析
CQRS架构下Equinox开源项目分析 一.DDD分层架构介绍 本篇分析CQRS架构下的Equinox开源项目.该项目在github上star占有2.4k.便决定分析Equinox项目来学习下CQR ...
随机推荐
- Linux 中的 ~/. 表示的意思
在Linux中, ~ 表示用户的目录, 如用户名是Gavin, 那么~/表示 /home/Gavin 所以~/. 表示 用户目录下的隐藏文件. 扩展: 若以用户身份登录 ~ 表示 /home 目录 ...
- mysql 免费的图形管理工具
在学习go语言开发时,使用了mysql 使用了两天mysql命令行,感觉实在是无法忍受, 找到了一个免费好用的 图形数据库管理工具SQLyog Professional 版本: 注册名:luoye25 ...
- 简单的3D森林
package { import flash.display.Sprite; public class Tree extends Sprite { public var xpos:Number = 0 ...
- Arm-Linux 移植 Nginx
有关博客: <Windows 编译安装 nginx 服务器 + rtmp 模块>.<Ubuntu 编译安装 nginx>.<Arm-Linux 移植 Nginx> ...
- jquery 如何获取select 选中项的下一个选项的值
<select> <option value="1" selected="selected">a</option> < ...
- Spring系列(三):Spring IoC源码解析
一.Spring容器类继承图 二.容器前期准备 IoC源码解析入口: /** * @desc: ioc原理解析 启动 * @author: toby * @date: 2019/7/22 22:20 ...
- VS 引用dll版本冲突问题
1.删除项目中的对应引用: 2.如果是有用到NetGet引用的删除项目中的packages里面的对应包文件: 3.如果是在NetGet中引用的注释项目中packages.config对应的插件名: 4 ...
- python-django中的APPEND_SLASH实现
关于django中的APPEND_SLASH APPEND_SLASH 它是啥? 看变量名大概能知道做什么,就是添加斜线,用路由系统那里. 路由文件,只写了路由关系代码 ...... urlpatte ...
- there is no route defined for key Agreement(react native bug记录)
调试react native的项目有一个报错: there is no route defined for key XXXX 它发生在我调试TabNavigator选项卡路由器的时候,我把如下代码的A ...
- Air for ANE:打包注意的地方
来源:http://blog.csdn.net/hero82748274/article/details/8631982 今天遇到了一个打包ANE 文件的问题,导致花费了几个小时查找,最后师弟的一句话 ...