cpu指令重排序的原理
目录:
1.重排序场景
2.追根溯源
3.缓存一致性协议
4.重排序原因
一、重排序场景
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //
flag = true; //
}
Public void reader() {
if (flag) { //
int i = a * a; //
……
}
}
}
当两个线程 A 和 B,A 首先执行writer() 方法,随后 B 线程接着执行 reader() 方法。线程B在执行操作4时,能否看到线程 A 在操作1对共享变量 a 的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
二、追根溯源
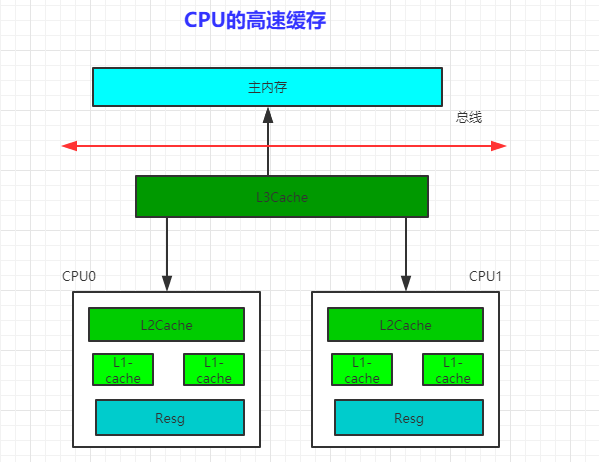
三、缓存一致性协议
据不一致

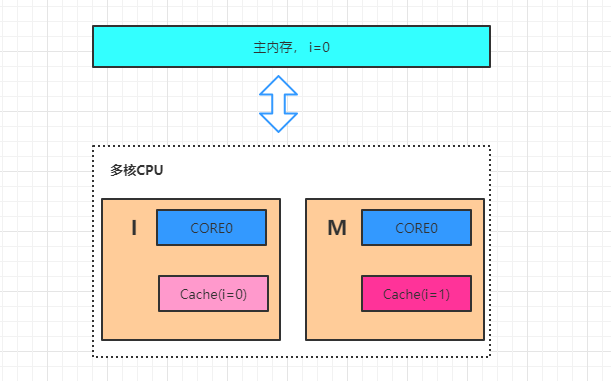
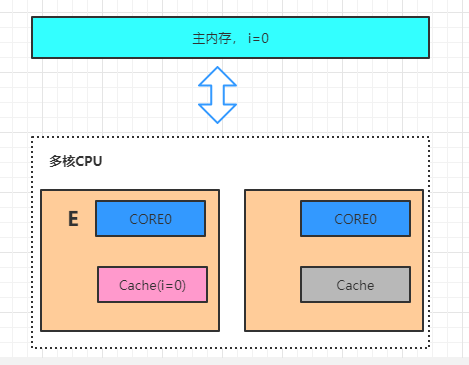
四、重排序原因
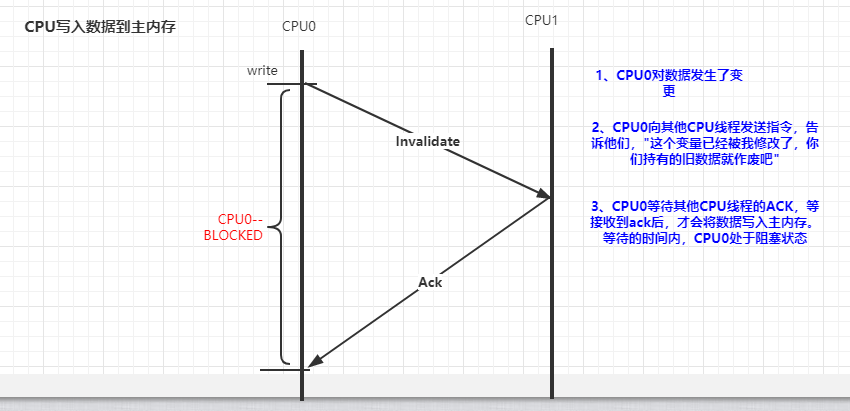
基于上图中的原因,CPU又引入了storeBuffers的缓冲区。CPU0 只需要在写入共享数据时,直接把数据写入到 storebufferes 中,同时发送 invalidate 消息,然后继续去处理其

这个时候,我们再来看上述标题一中的重排序场景。
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当执行1操作时,a的状态从S->M,此时,线程A会先把变更写入到storebuffers,然后发送invalidate去异步通知其他CPU线程,紧接着就执行了下面的2操作。
此时,可能1的变更还在storebuffers中,并未提交到主内存。什么时候会提交到主内存,也不确定。
所以,线程B调用read方法可能会出现,看到了flag的变更,但是看不到a的变更,就出现了重排序的现象。
cpu指令重排序的原理的更多相关文章
- CPU指令重排序与MESI缓存一致性
一.重排序场景 class ResortDemo { int a = 0; boolean flag = false; public void writer() { a = 1; //1 flag = ...
- java高并发核心要点|系列4|CPU内存指令重排序(Memory Reordering)
今天,我们来学习另一个重要的概念. CPU内存指令重排序(Memory Reordering) 什么叫重排序? 重排序的背景 我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多.当CP ...
- Java的多线程机制系列:不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- Java的多线程机制系列:(四)不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- 深入浅出Java并发包—指令重排序
前面大致提到了JDK中的一些个原子类,也提到原子类是并发的基础,更提到所谓的线程安全,其实这些类或者并发包中的这么一些类,都是为了保证系统在运行时是线程安全的,那到底怎么样才算是线程安全呢? Java ...
- JVM并发机制的探讨——内存模型、内存可见性和指令重排序
并发本来就是个有意思的问题,尤其是现在又流行这么一句话:“高帅富加机器,穷矮搓搞优化”. 从这句话可以看到,无论是高帅富还是穷矮搓都需要深入理解并发编程,高帅富加多了机器,需要协调多台机器或者多个CP ...
- 深入浅出 Java Concurrency (4): 原子操作 part 3 指令重排序与happens-before法则
转: http://www.blogjava.net/xylz/archive/2010/07/03/325168.html 在这个小结里面重点讨论原子操作的原理和设计思想. 由于在下一个章节中会谈到 ...
- 轻松学JVM(二)——内存模型、可见性、指令重排序
上一篇我们介绍了JVM的基本运行流程以及内存结构,对JVM有了初步的认识,这篇文章我们将根据JVM的内存模型探索java当中变量的可见性以及不同的java指令在并发时可能发生的指令重排序的情况. 内存 ...
- 【java多线程系列】java内存模型与指令重排序
在多线程编程中,需要处理两个最核心的问题,线程之间如何通信及线程之间如何同步,线程之间通信指的是线程之间通过何种机制交换信息,同步指的是如何控制不同线程之间操作发生的相对顺序.很多读者可能会说这还不简 ...
随机推荐
- 冠捷显示成功的信息化建设(MES应用案例)
企业介绍 冠捷科技集团是驰誉全球的大型高科技跨国企业,产品包括彩色显示器( CRT monitor ).液晶显示器( LCD monitor ).液晶电视( LCD-TV )与等离子电视( PDP ) ...
- Java部分目录
一.Java基础 1.访问权限控制 2.重载和覆盖 3.面向对象的特征 4.接口和抽象类 5.Java环境变量配置 6.Java英文缩写详解 7.如何在Maven项目中引入自己的jar包 8.使用ba ...
- 二十六、聊聊mysql如何实现分布式锁
分布式锁的功能 分布式锁使用者位于不同的机器中,锁获取成功之后,才可以对共享资源进行操作 锁具有重入的功能:即一个使用者可以多次获取某个锁 获取锁有超时的功能:即在指定的时间内去尝试获取锁,超过了超时 ...
- 尚学堂JAVA基础学习笔记
目录 尚学堂JAVA基础学习笔记 写在前面 第1章 JAVA入门 第2章 数据类型和运算符 第3章 控制语句 第4章 Java面向对象基础 1. 面向对象基础 2. 面向对象的内存分析 3. 构造方法 ...
- 大数据之kafka-02.搞定kafka专业术语
02.搞定kafka专业术语 在kafka的世界中有很多概念和术语是需要我们提前理解并且熟练掌握的,下面来盘点一下. 之前我们提到过,kafka属于分布式的消息引擎系统,主要功能是提供一套完善的消息发 ...
- CentOS安装MySQL8.x
MySQL的安装 (4,5,6可省略) 声明:CentOS版本为7.6,安装的MySQL版本为8.0.17 1. 首先要卸载掉本机自带的mysql相关,包括MariaDB. rpm -pa | gre ...
- Linux命令——od
参考:Linux OD Command Tutorial for Beginners (6 Examples) 简介 查看普通文本文件,可以使用cat.head.tail.tac.less.more等 ...
- MySQL/MariaDB数据库的查询缓存优化
MySQL/MariaDB数据库的查询缓存优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MySQL架构 Connectors(MySQL对外提供的交互接口,API): ...
- 《TensorFlow2深度学习》学习笔记(三)Tensorflow进阶
本篇笔记包含张量的合并与分割,范数统计,张量填充,限幅等操作. 1.合并与分割 合并 张量的合并可以使用拼接(Concatenate)和堆叠(Stack)操作实现,拼接并不会产生新的维度,而堆叠会创建 ...
- 《Java程序设计实验》 软件工程18-1,3 OO实验2