基于主成分分析(PCA)的数据降维
一、概述
主成分分析(Principal Component Analysis,PCA)是一种用于数据降维的方法,其核心目标是在尽可能保留原始数据信息的前提下,将高维数据映射到低维空间。该算法基于方差最大化理论,通过寻找数据的主要变化方向(即主成分),将原始数据投影到这些方向上,从而实现降维。
二、算法过程
1.数据中心化
指将数据的每个特征减去其均值,使得数据的均值为 0。这样做的目的是将数据的分布中心移到原点,便于后续计算协方差矩阵等操作,因为协方差矩阵的计算对于数据的中心位置比较敏感,中心化后可以更好地反映数据的内在结构和相关性。
值得说明的是,在某些情况下,特别是当不同特征的量纲差异较大或者数据的分布比较复杂时,除了数据中心化外,还会进行数据标准化。数据标准化是指将数据的每个特征减去对应特征列的均值再除以标准差,这样可以进一步消除不同特征在尺度上的差异,使得不同特征在后续的分析中具有相同的重要性,避免因特征尺度不同而导致的结果偏差。
2. 计算协方差矩阵
对中心化后的数据矩阵计算协方差,协方差矩阵描述了数据特征之间的相关性。
总体协方差矩阵计算公式为 \(Cov=\frac{1}{n}X_{c}^{T}X_c\)
样本协方差矩阵计算公式为 \(S=\frac{1}{n-1}X_{c}^{T}X_{c}\)
其中\(n\)是样本数量。实际计算中通常使用样本协方差,其中的\(\frac{1}{n-1}\)是总体协方差的无偏估计。
3. 计算协方差矩阵的特征值和特征向量
通过求解协方差矩阵\(S\)的特征方程 \(\left| S-\lambda I \right|=0\) ,得到特征值\(\lambda_i\)和对应的特征向量\(v_i\)。特征值反映了数据在对应特征向量方向上的方差大小,特征值越大,说明数据在该方向上的变化程度越大,包含的信息越多。
4. 选择主成分
将特征值按照从大到小的顺序排列,对应的特征向量也随之重新排序。选择前 \(k\) 个最大的特征值及其对应的特征向量,这些特征向量构成了新的低维空间的基向量。\(k\) 的选择通常基于一个阈值,例如保留能够解释原始数据方差累计百分比达到一定比例(如 80%、90% 等)的主成分。
5.数据投影
将原始数据投影到由选定的 \(k\) 个特征向量构成的低维空间中,得到降维后的数据。投影的计算公式为
\]
其中,\(X_c\)是中心化后的数据矩阵,\(W\)是由前\(k\)个特征向量组成的投影矩阵,\(Y\) 是降维后的数据矩阵。
三、示例
现有一组二维数据 \(X=
\begin{bmatrix}
1 & 2 \\
2 & 3 \\
3 & 4 \\
4 & 5 \\
5 & 6
\end{bmatrix}\) ,下面使用PCA方法进行降维,将其从二维降至一维。
1.数据标准化
首先,计算每列的均值:
第一列均值:\(\bar x_1=\frac{1+2+3+4+5}{5}=3\)
第二列均值:\(\bar x_2=\frac{2+3+4+5+6}{5}=4\)
然后,对矩阵\(X\)进行中心化,得到矩阵\(X_c\)
\(X_c=\)\(\begin{bmatrix}
1-3 & 2-4 \\
2-3 & 3-4 \\
3-3 & 4-4 \\
4-3 & 5-4 \\
5-3 & 6-4
\end{bmatrix}\)\(=\)\(\begin{bmatrix}
-2 & -2 \\
-1 & -1 \\
0 & 0 \\
1 & 1 \\
2 & 2
\end{bmatrix}\)
2. 计算协方差矩阵
协方差矩阵\(S\)的计算公式为\(S=\frac{1}{n-1}X_{c}^{T}X_{c}\),其中\(n\)是样本数量。
\(X_c^TX_c=\)\(\begin{bmatrix}
-2 & -1 &0 & 1 & 2 \\
-2 & -1 &0 & 1 & 2
\end{bmatrix}\)\(\begin{bmatrix}
-2 & -2 \\
-1 & -1 \\
0 & 0 \\
1 & 1 \\
2 & 2
\end{bmatrix}\)\(=\)\(\begin{bmatrix}
10 & 10 \\
10 & 10
\end{bmatrix}\)
则协方差矩阵 \(S\) 为
\(S=\frac{1}{5-1}\)\(\begin{bmatrix}
10 & 10 \\
10 & 10
\end{bmatrix}\)\(=\)\(\begin{bmatrix}
2.5 & 2.5 \\
2.5 & 2.5
\end{bmatrix}\)
3. 计算协方差矩阵的特征值和特征向量
对于矩阵 \(S\),其特征方程为 \(\left| S-\lambda I \right|=0\) ,其中 \(I\) 是单位矩阵。
\(\begin{vmatrix}
2.5-\lambda & 2.5 \\
2.5 & 2.5-\lambda
\end{vmatrix}\)\(=\)\({(2.5-\lambda)}^{2}-2.5^2\)\(=\)\(0\)
展开可得 \(\lambda^2-5\lambda=0\) ,解得特征值为 \(\lambda_1=5\),\(\lambda_2=0\)。
求特征向量:
对于 \(\lambda_1=5\) 求解 \((S-5I)v_1=0\)
\(\begin{bmatrix}
2.5-5 & 2.5 \\
2.5 & 2.5-5
\end{bmatrix}\)\(\begin{bmatrix}
v_{11} \\
v_{12}
\end{bmatrix}\)\(=\)\(\begin{bmatrix}
-2.5 & 2.5 \\
2.5 & -2.5
\end{bmatrix}\)\(\begin{bmatrix}
v_{11} \\
v_{12}
\end{bmatrix}\)\(=\)\(\begin{bmatrix}
0 \\
0
\end{bmatrix}\)
取 \(v_{11}=1\) ,则 \(v_{12}=1\) ,单位化后得到特征向量 \(v_1=
\begin{bmatrix}
\frac{1}{\sqrt{2}} \\
\frac{1}{\sqrt{2}}
\end{bmatrix}\) 。
对于 \(\lambda_2=0\) ,求解 \((S-0I)v_2=0\)
\(\begin{bmatrix}
2.5 & 2.5 \\
2.5 & 2.5
\end{bmatrix}\)\(\begin{bmatrix}
v_{21} \\
v_{22}
\end{bmatrix}\)\(=\)\(\begin{bmatrix}
0 \\
0
\end{bmatrix}\)
取 \(v_{21}=1\) ,则 \(v_{22}=-1\) ,单位化后得到特征向量 \(v_2=
\begin{bmatrix}
\frac{1}{\sqrt{2}} \\
-\frac{1}{\sqrt{2}}
\end{bmatrix}\) 。
4. 选择主成分
按照特征值从大到小排序,选择前 \(k\) 个特征值对应的特征向量作为主成分。这里我们选择最大特征值 \(\lambda_1=5\)
对应的特征向量 \(v_1=
\begin{bmatrix}
\frac{1}{\sqrt{2}} \\
\frac{1}{\sqrt{2}}
\end{bmatrix}\) 作为主成分。
5. 数据投影
将中心化后的数据 \(X_c\) 投影到主成分上,得到降维后的数据
\(Y=X_cv_1=\)\(\begin{bmatrix}
-2 & -2 \\
-1 & -1 \\
0 & 0 \\
1 & 1 \\
2 & 2
\end{bmatrix}\)\(\begin{bmatrix}
\frac{1}{\sqrt{2}} \\
\frac{1}{\sqrt{2}}
\end{bmatrix}\)\(=\)\(\begin{bmatrix}
-2\sqrt{2} \\
-\sqrt{2} \\
0 \\
\sqrt{2} \\
2\sqrt{2}
\end{bmatrix}\) 。
四、Python实现
scikit-learn实现:
import numpy as np
from sklearn.decomposition import PCA
# 数据
data = np.array([[1, 2],
[2, 3],
[3, 4],
[4, 5],
[5, 6]])
# 创建PCA对象,指定降维后的维度为1
pca = PCA(n_components=1)
# 使用PCA对数据进行降维
reduced_data = pca.fit_transform(data)
# 降维后的数据
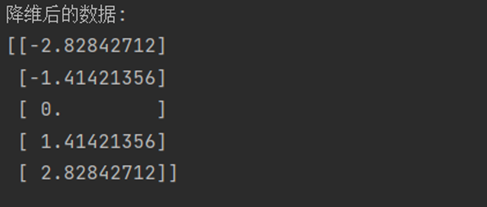
print("降维后的数据:")
print(reduced_data)

#### 函数实现:
import numpy as np
def pca(X, n_components):
# 数据中心化
X_mean = np.mean(X, axis=0)
X_centered = X - X_mean
# 计算协方差矩阵
cov_matrix = np.cov(X_centered, rowvar=False)
# 计算协方差矩阵的特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# 对特征值进行排序,获取排序后的索引
sorted_indices = np.argsort(eigenvalues)[::-1]
# 选择前n_components个最大特征值对应的特征向量
top_eigenvectors = eigenvectors[:, sorted_indices[:n_components]]
# 将数据投影到选定的特征向量上
X_reduced = np.dot(X_centered, top_eigenvectors)
return X_reduced
# 数据
X = np.array([[1,2],
[2,3],
[3,4],
[4,5],
[5,6]])
# 降至1维
n_components = 1
X_reduced = pca(X, n_components)
# 降维后的数据
print("降维后的数据:")
print(X_reduced)
End.
基于主成分分析(PCA)的数据降维的更多相关文章
- 降维(一)----说说主成分分析(PCA)的源头
降维(一)----说说主成分分析(PCA)的源头 降维系列: 降维(一)----说说主成分分析(PCA)的源头 降维(二)----Laplacian Eigenmaps --------------- ...
- 数据降维技术(2)—奇异值分解(SVD)
上一篇文章讲了PCA的数据原理,明白了PCA主要的思想及使用PCA做数据降维的步骤,本文我们详细探讨下另一种数据降维技术—奇异值分解(SVD). 在介绍奇异值分解前,先谈谈这个比较奇怪的名字:奇异值分 ...
- 高维数据降维 国家自然科学基金项目 2009-2013 NSFC Dimensionality Reduction
2013 基于数据降维和压缩感知的图像哈希理论与方法 唐振军 广西师范大学 多元时间序列数据挖掘中的特征表示和相似性度量方法研究 李海林 华侨大学 基于标签和多特征融合的图像语义空间学习技 ...
- 数据降维-PCA主成分分析
1.什么是PCA? PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法.PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特 ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- [机器学习之13]降维技术——主成分分析PCA
始终贯彻数据分析的一个大问题就是对数据和结果的展示,我们都知道在低维度下数据处理比较方便,因而数据进行简化成为了一个重要的技术.对数据进行简化的原因: 1.使得数据集更易用使用.2.降低很多算法的计算 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
随机推荐
- log4net 配置数据库连接
http://logging.apache.org/log4net/release/config-examples.html MS SQL Server The database table defi ...
- test1111
了解客户端和服务端的请求原理 HTTP协议及其组成 HTTPS交互原理分析 访问支付宝,微信的开放接口 都是基于HTTP 对外提供的开放服务 API都是基于HTTP协议的, 微服务中的服务之间的调用大 ...
- 如何测试网络是否支持ipv6地址?如何打开ipv6?
疑难解答加微信机器人,给它发:进群,会拉你进入八米交流群 机器人微信号:bamibot 简洁版教程访问:https://bbs.8miyun.cn 一.什么是IPv6: 1.IPv6简介: IPv6是 ...
- 机器学习 | 强化学习(5) | 价值函数拟合(Value Function Approximation)
价值函数拟合(Value Function Approximation) 导论(Introduction) 目前的价值函数都是基于打表法(lookup table)进行穷举 对于所有状态\(s\)都有 ...
- PHP检测用户是否关闭浏览器的方法
1.例子1 echo str_repeat(" ",3000); ignore_user_abort(true); mylog('online'); while (true) { ...
- 分布式锁—3.Redisson的公平锁
大纲 1.Redisson公平锁RedissonFairLock概述 2.公平锁源码之加锁和排队 3.公平锁源码之可重入加锁 4.公平锁源码之新旧版本对比 5.公平锁源码之队列重排 6.公平锁源码之释 ...
- HTTP请求中包含账号密码
如果你需要在HTTP请求中包含账号密码,你可以使用基本的HTTP身份验证.在C#中,你可以通过设置 HttpClient 的 DefaultRequestHeaders 来添加身份验证信息.以下是修改 ...
- Mysql 8.0 创建用户、授权用户、更改密码、撤销用户权限、删除用户
一. 创建用户 CREATE USER 'username'@'host' IDENTIFIED BY 'password'; 说明: username: 你将创建的用户名 host: 指定该用户在哪 ...
- CentOS7图形化界面和命令行界面之间的转换
最近在学习Lunix操作系统下的CentOS7系统,参考了网页上大多数的资料并进行在自己的亲身实践,最终想要记录一下我在CentOS7系统中有关命令行和图形化界面之间的转换.1.查看当前的默认界面形式 ...
- 适配器设计模式--java进阶day03
1.设计模式 通俗来讲,设计模式就是其他程序员遇到某些问题时的解决经验,我们学习设计模式,在遇到了同样的问题后便可解决 2.适配器设计模式 有人可能会感到疑惑,接口和实现类会有什么问题,我们举两个例子 ...