Bagging、Boosting、Stacking的原理
Bagging、Boosting、Stacking是常见集成学习的形式,它们都是通过对多个学习器进行有机组合,达到比单个学习器性能更好的目标。
一、Bagging
1.算法概述
Bagging(Bootstrap Aggregating)算法即自助聚合算法,是一种基于统计学习理论的集成学习算法,主要用于提高机器学习模型的稳定性和泛化能力。具体来说就是,先以Bootstrap方式(有放回重复采样)构造多个样本集,每个样本集分别训练得到一个学习器,最后将各学习器的输出综合起来,得到一个最终的输出,如果是分类,多采用多数投票的方式,如果是回归,采用取平均的方式,代表性算法如随机森林。
示意图
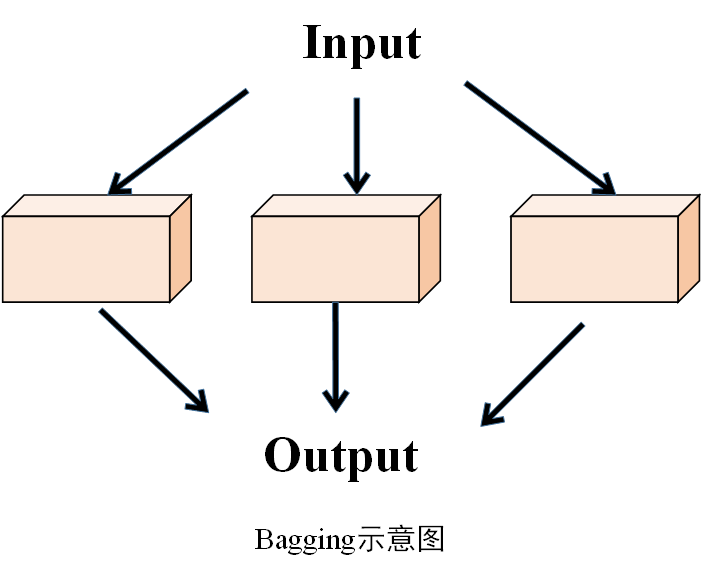
2.算法过程
(1) 数据采样
从原始训练数据集\(D\)中,采用有放回的抽样方式,随机抽取 \(n\)个样本,组成一个新的训练数据集 \(D_i\)。这个过程会重复\(K\)次,从而得到\(K\)个不同的自助样本集\(\left\{ D_1,D_2,...,D_K \right\}\) 。由于是有放回抽样,每个自助样本集中可能会包含一些重复的样本,同时也会有一些原始数据集中的样本未被选中。
(2)模型训练
对于每个自助样本集\(D_i\),分别使用相同的基学习算法(如决策树、神经网络等)进行训练,得到\(K\)个不同的基模型\(\left\{ h_1,h_2,...,h_K \right\}\)。这些基模型在训练过程中会学习到不同的特征和模式,因为它们所使用的训练数据是不同的。
(3) 模型融合
将训练好的\(K\)个基模型进行融合,以得到最终的预测结果。对于分类任务,通常采用投票法,即让\(K\)个基模型对测试样本进行预测,然后统计每个类别出现的次数,将得票最多的类别作为最终的预测结果。对于回归任务,一般采用平均法,即计算\(K\)个基模型对测试样本的预测值的平均值,将其作为最终的预测结果。
过程图示如下
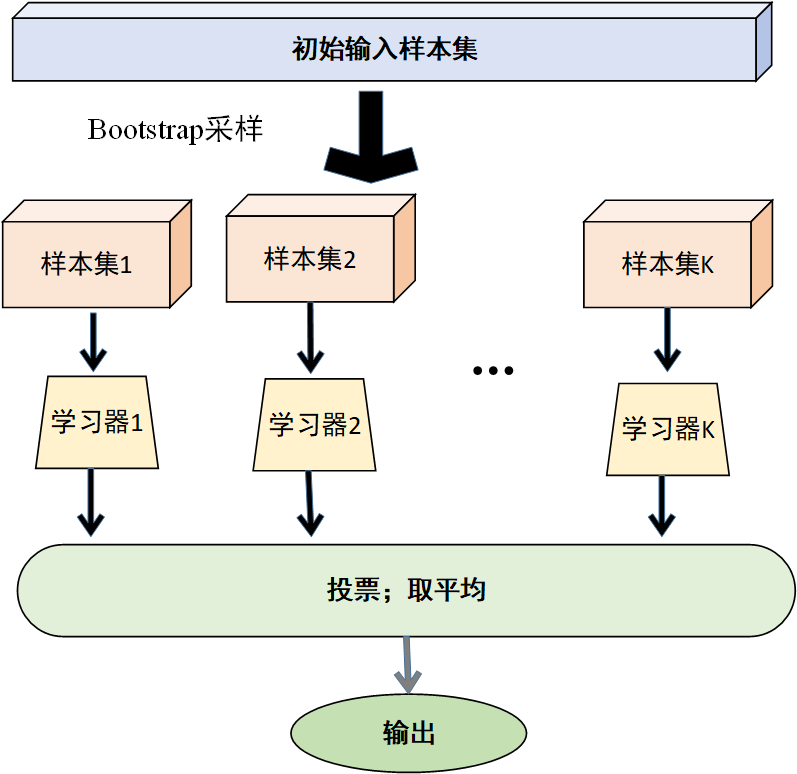
通过 Bagging 算法,可以将多个基模型进行集成,充分利用它们之间的差异,降低模型的方差,从而提高模型的稳定性和泛化能力。尤其是在处理高方差的基模型(如决策树)时,Bagging 算法通常能取得较好的效果。
二、Boosting
1.算法概述
Boosting是指逐层提升,其核心思想是“前人栽树,后人乘凉”,也就是使后一个学习器在前一个学习器的基础上进行增强,进而将多个弱学习器通过某种策略集成一个强学习器,以实现更好的预测效果。常见的提升算法如AdaBoost、XGBoost、CatBoost、LightGBM等。
示意图
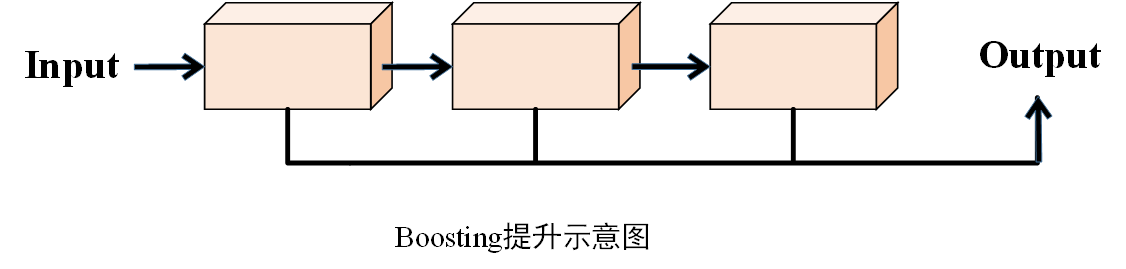
2.算法过程
(1)设置初始样本权重
在算法开始时,为训练数据集中的每一个样本设定一个相同的权重。如对于样本集\(D=\left\{ (x_1,y_1),(x_2,y_2),...,(x_n,y_n) \right\}\),初始权重为\(w^{(1)}=\left( w_{1}^{(1)} ,w_{2}^{(1)},...,w_{n}^{(1)} \right)\) ,其中\(w_{i}^{(1)}=\frac{1}{n}\),即在第一轮训练时,每个样本在模型训练中的重要度是相同的。
(2)训练弱学习器
基于当前的权重分布,训练一个弱学习器。基于当前的权重分布,训练一个弱学习器。弱学习器是指一个性能仅略优于随机猜测的学习算法,例如决策树桩(一种简单的决策树,通常只有一层)。在训练过程中,弱学习器会根据样本的权重来调整学习的重点,更关注那些权重较高的样本。
(3) 计算弱学习器的权重
根据弱学习器在训练集上的分类错误率,计算该弱学习器的权重。错误率越低,说明该弱学习器的性能越好,其权重也就越大;反之,错误率越高的弱学习器权重越小。通常使用的计算公式为
\]
其中\(\varepsilon\)是该弱学习器的错误率。
(4) 更新训练数据的权重分布
根据当前数据的权重和弱学习器的权重,更新训练数据的权重分布。具体的更新规则是,对于被正确分类的样本,降低其权重;对于被错误分类的样本,提高其权重。这样,在下一轮训练中,弱学习器会更加关注那些之前被错误分类的样本,从而有针对性地进行学习。公式为
\]
其中,\(w_{i}^{(t)}\)是第\(t\) 轮中第\(i\)个样本的权重,\(Z_t\)是归一化因子,确保更新后的样本权重之和为 1,\(h_t(x_i)\)是第\(t\)个弱学习器对第\(i\)个样本的预测结果。
(5) 重复以上步骤
不断重复训练弱学习器、计算弱学习器权重、更新数据权重分布的过程,直到达到预设的停止条件,如训练的弱学习器数量达到指定的上限,或者集成模型在验证集上的性能不再提升等。
(6)构建集成模型
将训练好的所有弱学习器按照其权重进行组合,得到最终的集成模型。如训练得到一系列弱学习器\(h_1,h_2,...,h_T\)及其对应的权重\(\alpha_1,\alpha_2,...,\alpha_T\),最终的强学习器\(H(X)\)通过对这些弱学习器进行加权组合得到。对于分类问题,通常采用符号函数\(H\left( X \right)=sign\left( \sum_{t=1}^{T}{\alpha_th_t(X)} \right)\)输出;对于回归问题,则可采用加权平均的方式输出。
过程图示如下
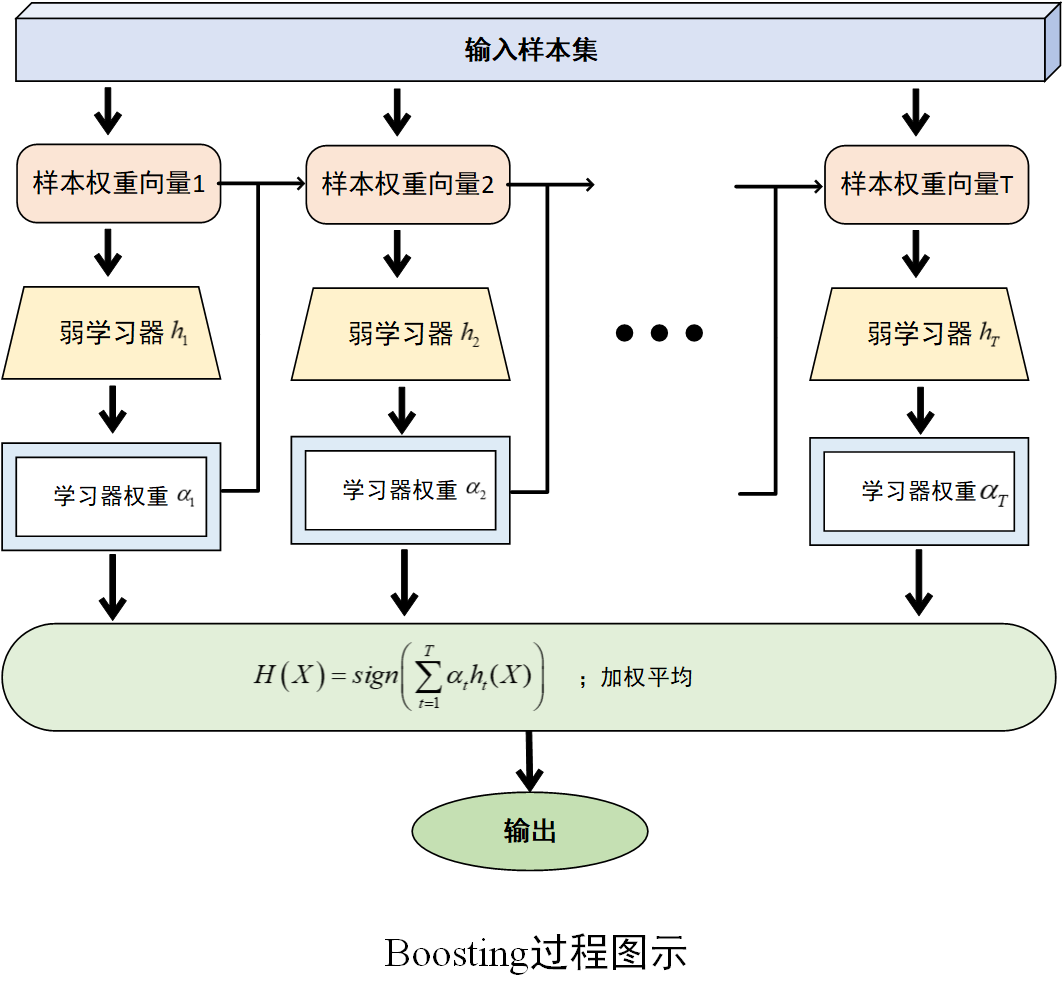
通过以上过程,Boosting 算法能够不断调整样本权重,让后续的弱学习器更加关注之前被错误分类的样本,从而逐步提升模型的性能,将多个弱学习器集成起来形成一个性能较强的学习器。
三、Stacking
1.算法概述
Stacking(堆叠集成)算法也是一种集成学习方法,它通过组合多个基学习器的预测结果,训练一个更高层次的模型(元学习器),从而获得比单个模型更好的预测性能。其核心思想在于利用不同算法在处理数据时的互补性,通过多层学习,挖掘数据的特征和规律,以实现更准确的预测。
示意图
2.算法过程
(1)训练多个基学习器
选择若干个不同的学习算法(如决策树、支持向量机、神经网络等)训练多个基学习器,记为\(h_1,h_2,...,h_K\)。
(2)构建新训练集
将各基学习器在训练集上的预测值作为一个新的特征矩阵,与原始训练集的标签相组合,构成一个新的训练集。
(3)训练元学习器
选择一个学习算法(如逻辑回归、决策树等)在新训练集上训练学习器,即元学习器。表达式为$$H\left( X \right)=F\left( h_1(X),h_2(X),...,h_K(X) \right)$$
过程图示如下
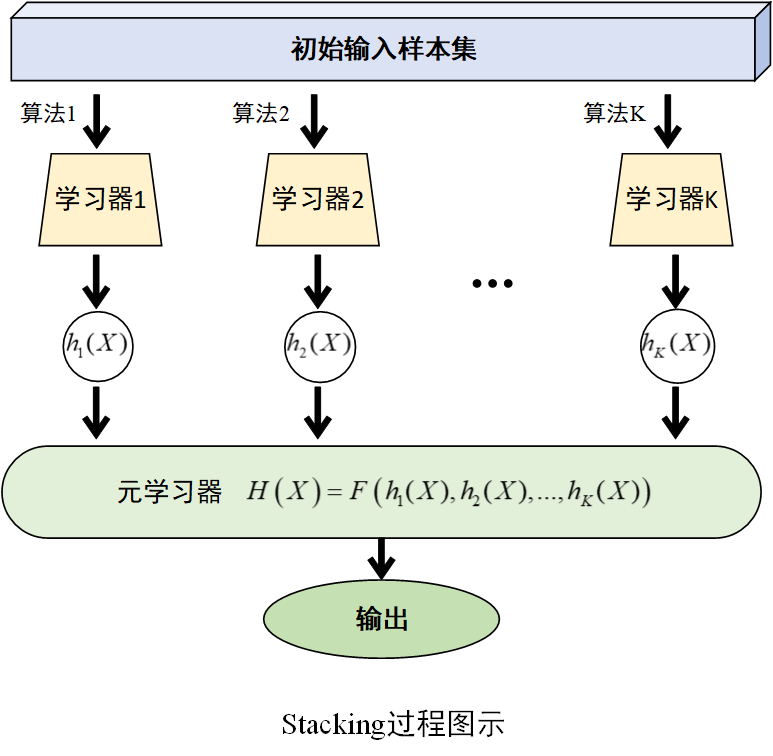
Stacking方法将基学习器对数据的预测结果作为元学习器的输入特征,元学习器输出最终的预测结果。这种分层训练和预测的方式,能够充分利用不同算法的优势,捕捉数据中更复杂的关系。
End.
Bagging、Boosting、Stacking的原理的更多相关文章
- 机器学习 - 算法 - 集成算法 - 分类 ( Bagging , Boosting , Stacking) 原理概述
Ensemble learning - 集成算法 ▒ 目的 让机器学习的效果更好, 量变引起质变 继承算法是竞赛与论文的神器, 注重结果的时候较为适用 集成算法 - 分类 ▒ Bagging - bo ...
- 机器学习入门-集成算法(bagging, boosting, stacking)
目的:为了让训练效果更好 bagging:是一种并行的算法,训练多个分类器,取最终结果的平均值 f(x) = 1/M∑fm(x) boosting: 是一种串行的算法,根据前一次的结果,进行加权来提高 ...
- Bagging, Boosting, Bootstrap
Bagging 和 Boosting 都属于机器学习中的元算法(meta-algorithms).所谓元算法,简单来讲,就是将几个较弱的机器学习算法综合起来,构成一个更强的机器学习模型.这种「三个臭皮 ...
- Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting的区别
引自http://blog.csdn.net/xianlingmao/article/details/7712217 Jackknife,Bootstraping, bagging, boosting ...
- stacking算法原理及代码
stacking算法原理 1:对于Model1,将训练集D分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果 2:重复上面步骤,直到每一份都预测出来.得到次级模型的训练集 3:得到k份 ...
- 【机器学习】Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting
Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting 这些术语,我经常搞混淆, ...
- Ensemble Learning: Bootstrap aggregating (Bagging) & Boosting & Stacked generalization (Stacking)
Booststrap aggregating (有些地方译作:引导聚集),也就是通常为大家所熟知的bagging.在维基上被定义为一种提升机器学习算法稳定性和准确性的元算法,常用于统计分类和回归中. ...
- 快速理解bootstrap,bagging,boosting,gradient boost-三个概念
1 booststraping:意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法. 其核心思想和基本步骤如下: (1 ...
- Jackknife,Bootstrap, Bagging, Boosting, AdaBoost, RandomForest 和 Gradient Boosting的区别
Bootstraping: 名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统 ...
- 集成算法(Bagging & Boosting)
用多种分类器一起完成同一份任务 Bagging策略(有放回的,随机的,子集大小一样的,m个训练集用同一个模型) Boosting-提升策略(串联) AdaBoost算法
随机推荐
- changeServer.sh一键切换服务器脚本
直接看改进版2.0 切换服务器,免密登录vi changeServer.sh #!/bin/bash #authe by wangxp export IFCFG=/etc/sysconfig/netw ...
- 深入剖析Base64加解密中遇到的坑点
前言 最近开发过程中遇到了关于使用base64加密传输遇到的神奇问题.需求就是用户的id在链接上露出时需要加密处理,于是后端把下发的用户id改成了base64加密处理后下发了,前端只需要把加密后的用户 ...
- 单机麒麟kylin安装
https://archive.apache.org/dist/kylin/ 2.5.0版本 首先启动hadoop.hive.hbase 并记得设置环境变量 #JDK export JAVA_HOME ...
- DevExpress MVVM Framework. Interaction of ViewModels. Messenger
学习记录: 学习地址:https://community.devexpress.com/blogs/wpf/archive/2013/12/13/devexpress-mvvm-framework-i ...
- JSONObject String、实体类 list 转换
JSONObject获取java list JSONObject -->> JSONArray jsonObject .getJSONArray("list") J ...
- Thymeleaf select 反显 默认选中
后台代码 List<ExamTestPaperDO> list = examTestPaperService.list(map); model.addAttribute("tes ...
- 收集 Spring Boot 相关的学习资料
收集 Spring Boot 相关的学习资料,Spring Cloud点这里 重点推荐:Spring Boot 中文索引 推荐博客 纯洁的微笑-Spring Boot系列文章 林祥纤-从零开始学Spr ...
- 【Unity】URP中的UGUIShader实现
[Unity]URP 中的 UGUIShader 实现 参考官方 Shader 代码实现: https://github.com/TwoTailsGames/Unity-Built-in-Shader ...
- AI图像翻译
在当今互联互通的世界中,快速准确地翻译图像中的文本的能力非常宝贵.无论您是商务人士.教育工作者.设计师还是内容创作者,Visual Paradigm Online 的 AI 图像翻译器都能提供强大的解 ...
- 飞牛 fnos 使用docker部署NapCat-QQ对接autman教程
NapCatQQ介绍 无需图形环境,在Linux上表现出色,与现有Hook框架有本质区别,性能与内存占用优于基于Hook的框架. 配置简单,支持浏览器远程配置. NTQQ功能适配快速,持续跟进QQ最新 ...