Kafka入门实战教程(2)基于Docker搭建Kafka环境
1 准备工作
这里我们使用一台Linux CentOS系统的服务器来模拟三个Kafka Broker的伪集群(即一台server上开三个不同端口)环境用于学习测试,大概的准备工作有两个:
安装Docker
# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O
/etc/yum.repos.d/docker-ce.repo
# yum -y install docker
# systemctl enable docker && systemctl start docker
# docker --version
安装Docker Compose
# sudo curl -L "https://github.com/docker/compose/releases/download/1.28.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# sudo chmod +x /usr/local/bin/docker-compose
# docker-compose --version
2 部署Kafka环境
准备docker-compose.yml文件
这里我的宿主机IP是172.16.16.4,你需要改为你自己的。
具体的 docker-compose.yml 文件内容如下:
version: '3.8'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
restart: always
kafka1:
image: wurstmeister/kafka
depends_on: [ zookeeper ]
container_name: kafka1
ports:
- "9091:9091"
environment:
HOSTNAME: kafka1
KAFKA_BROKER_ID: 0
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka1:9091
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9091
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181/kafka
extra_hosts:
kafka1: 172.16.16.4
kafka2:
image: wurstmeister/kafka
depends_on: [ zookeeper ]
container_name: kafka2
ports:
- "9092:9092"
environment:
HOSTNAME: kafka2
KAFKA_BROKER_ID: 1
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka2:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181/kafka
extra_hosts:
kafka2: 172.16.16.4
kafka3:
image: wurstmeister/kafka
depends_on: [ zookeeper ]
container_name: kafka3
ports:
- "9093:9093"
environment:
HOSTNAME: kafka3
KAFKA_BROKER_ID: 2
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka3:9093
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181/kafka
extra_hosts:
kafka3: 172.16.16.4
部署Zookeeper和Kafka
将docker-compose.yml文件拷贝到服务器,紧接着在该文件目录下执行:docker-compose up -d 即可快速完成部署。
# docker-compose up -d
Building with native build. Learn about native build in Compose here: https://docs.docker.com/go/compose-native-build/
Creating network "kafka_default" with the default driver
Creating zookeeper ... done
Creating kafka1 ... done
Creating kafka3 ... done
Creating kafka2 ... done
部署完成后,通过执行:docker-compose ps 来验证一下。
# docker-compose ps
Name Command State Ports
-------------------------------------------------------------------------------------------------------------------------
kafka1 start-kafka.sh Up 0.0.0.0:9091->9091/tcp,:::9091->9091/tcp
kafka2 start-kafka.sh Up 0.0.0.0:9092->9092/tcp,:::9092->9092/tcp
kafka3 start-kafka.sh Up 0.0.0.0:9093->9093/tcp,:::9093->9093/tcp
zookeeper /bin/sh -c /usr/sbin/sshd ... Up 0.0.0.0:2181->2181/tcp,:::2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
其中,docker-compose.yml中HOSTNAME和extra_hosts的结合使用,会在容器中的/etc/hosts中增加一条记录,通过执行:docker exec -it kafka1 cat /etc/hosts 来验证一下。
# docker exec -it kafka1 cat /etc/hosts
.....
172.16.16.4 kafka1
.....
3 容器内验证与测试
安装部署完成后,首先,我们进入容器内部,来验证和测试一下。
docker exec -it kafka1 bash
创建测试Topic
创建一个测试用的topic:testtopic,此topic配置了2个分区,无额外的副本。
kafka-topics.sh --create --zookeeper 172.16.16.4:2181/kafka --replication-factor 1 --partitions 2 --topic testtopic
模拟Producer
重新打开一个窗口,进入容器内部,模拟一个producer,在控制台随意发送一些字符串消息。
kafka-console-producer.sh --topic=testtopic --broker-list kafka1:9091,kafka2:9092,kafka3:9093
>tests
>haha
模拟Consumer
重新打开一个窗口,进入容器内部,模拟一个consumer,设置从头开始消费,会收到producer发来的字符串消息。
kafka-console-consumer.sh --bootstrap-server kafka1:9091,kafka2:9092,kafka3:9093 --from-beginning --topic testtopic
tests
haha
可以看到,consumer成功接收到了producer发来的两个string类型的message。
4 使用GUI工具:Kafka Tool
Kafka Tool是一个用于管理和使用Apache Kafka集群的GUI应用程序。Kafka Tool提供了一个较为直观的UI可让用户快速查看Kafka集群中的对象以及存储在topic中的消息,提供了一些专门面向开发人员和管理员的功能。
NOTE:目前Kafka Tool已改名为Offset Explorer,不过我还是倾向于叫它 Kafka Tool。
下载地址:https://www.kafkatool.com/download.html
使用方式比较简单,首先创建一个Connection,需要填写的配置如下:
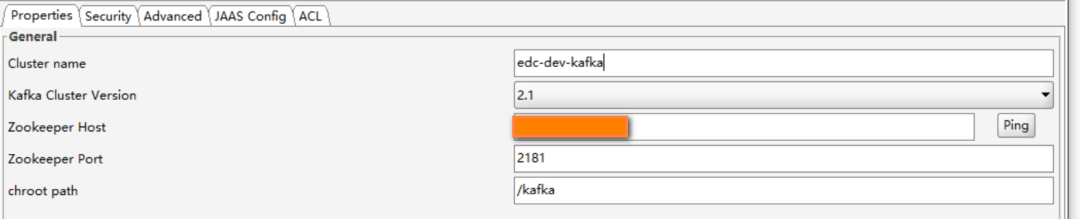
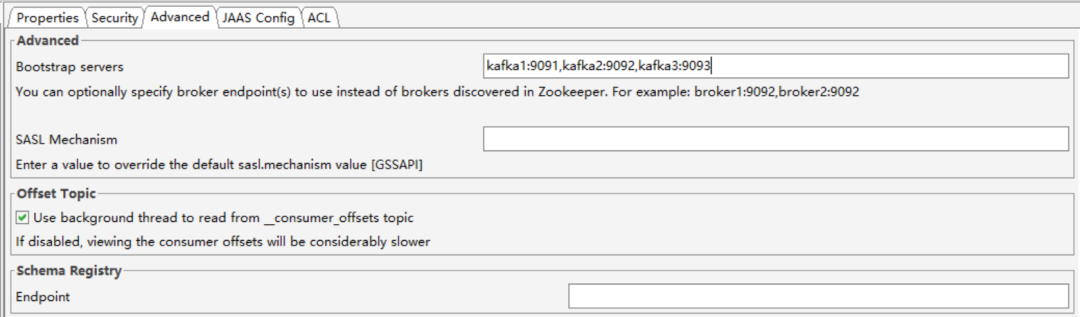
NOTE:这里bootstrap-servers参数列表填写的是主机名,你可以先在自己电脑上的hosts文件中添加这个映射
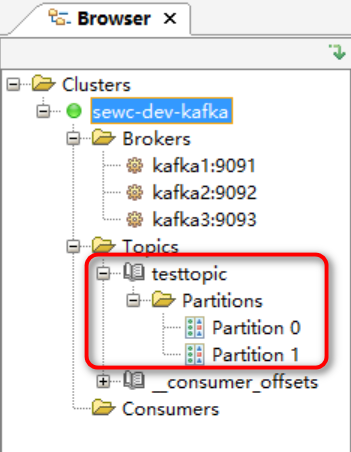
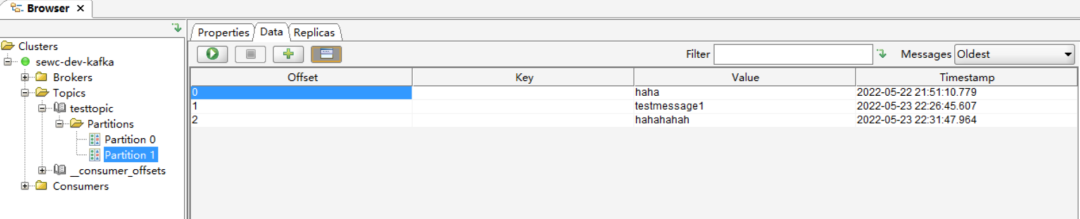
然后点击Test测试无误就进入了以下界面,可以看到我们刚刚创建的topic有两个分区已经可以显示出来了。
然后更改一下显示内容的类型:从Byte Array改为String,方便查看。
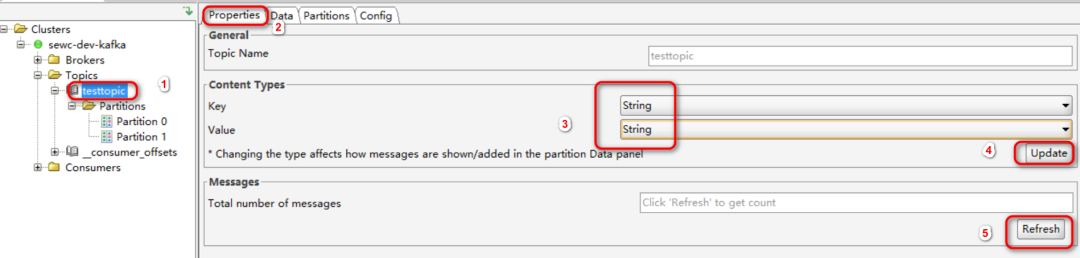
通过上面的producer.sh再发送一些消息,然后通过kafka tool来查看一下消息:
5 总结
本文总结了Kafka的测试环境搭建过程,本文选择的是基于Docker来搭建非宿主机直接搭建,加之官方并没有推出官方的Docker镜像,因此建议生产环境还是不要通过Docker来搭建,开发/测试环境是可以的,快速且高效。
注意:目前Kafka的Docker镜像最新版是Apache Kafka的2.8版本,而Apache Kafka最新已经3.x版本了。
参考资料
极客时间,胡夕《Kafka核心技术与实战》
B站,尚硅谷《Kafka 3.x入门到精通教程》

Kafka入门实战教程(2)基于Docker搭建Kafka环境的更多相关文章
- Kafka入门实战教程(7):Kafka Streams
1 关于流处理 流处理平台(Streaming Systems)是处理无限数据集(Unbounded Dataset)的数据处理引擎,而流处理是与批处理(Batch Processing)相对应的.所 ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于Docker搭建LNMP环境(转)
关于什么是docker,建议大家先上网查查有关的用法.如果您不了解,在这篇文章中,您可以简单的理解为他是一个轻量级的虚拟机. 一.docker安装mysql 首先,我们从仓库拉取一个MySql的镜像 ...
- docker搭建lnmp环境(问题,资料,命令)
入门参考 http://www.runoob.com/docker/docker-install-nginx.html 十大常用命令玩转docker 1. #从官网拉取镜像 docker pull & ...
- Docker搭建disconf环境,三部曲之一:极速搭建disconf
Docker下的disconf实战全文链接 <Docker搭建disconf环境,三部曲之一:极速搭建disconf>: <Docker搭建disconf环境,三部曲之二:本地快速构 ...
- Docker搭建disconf环境,三部曲之二:本地快速构建disconf镜像
Docker下的disconf实战全文链接 <Docker搭建disconf环境,三部曲之一:极速搭建disconf>: <Docker搭建disconf环境,三部曲之二:本地快速构 ...
- Docker搭建disconf环境,三部曲之三:细说搭建过程
Docker下的disconf实战全文链接 <Docker搭建disconf环境,三部曲之一:极速搭建disconf>: <Docker搭建disconf环境,三部曲之二:本地快速构 ...
- 基于Docker搭建分布式消息队列Kafka
本文基于Docker搭建一套单节点的Kafka消息队列,Kafka依赖Zookeeper为其管理集群信息,虽然本例不涉及集群,但是该有的组件都还是会有,典型的kafka分布式架构如下图所示.本例搭建的 ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
- 深入浅出Docker(五):基于Fig搭建开发环境
概述 在搭建开发环境时,我们都希望搭建过程能够简单,并且一劳永逸,其他的同事可以复用已经搭建好的开发环境以节省开发时间.而在搭建开发环境时,我们经常会被复杂的配置以及重复的下载安装所困扰.在Docke ...
随机推荐
- Efficient Scalable Multi-Party Private Set Intersection
论文学习:Efficient Scalable Multi-Party Private Set Intersection 这篇论文提出了一种基于双中心零共享(Bicentric Zero-Sharin ...
- 【前端JSP思考】JSP中#{},${}和%{}的区别
JSP中#{},${}和%{}的区别: #{} #{}:对语句进行预编译,此语句解析的是占位符?,可以防止SQL注入, 比如打印出来的语句 select * from table where id=? ...
- Let’s Encrypt & Certbot 浅谈
前言 当我们想给网站启用HTTPS, 通常需要从证书颁发机构购买证书, 并配置到现有的HTTP服务上来实现HTTPS. 这里暗藏的痛点是: 我们需要花钱(买证书) 证书颁发机构(质量参差不齐, 不一定 ...
- 为Avalonia应用添加图标
前言 为了让自己开发的应用更加好看,开发者往往需要增加一些图标. 本文分享在开发Avalonia应用时如何为应用增加图标,希望可以帮助到正在学习使用Avalonia并有此需求的开发者. 实践 经过搜索 ...
- 一文速通Python并行计算:06 Python多线程编程-基于队列进行通信
一文速通 Python 并行计算:06 Python 多线程编程-基于队列进行通信 摘要: 队列是一种线性数据结构,支持先进先出(FIFO)操作,常用于解耦生产者和消费者.慢速生产-快速消费场景中,队 ...
- 想靠RAG提升模型回答质量,那是不可能的
提供AI咨询+AI项目陪跑服务,有需要回复1 上周写了一篇AI知识库的文章:聊聊与一体机同等级的智商税:AI知识库 事实上,文章对于AI知识库是稍带了点否定的色彩,因为单独的知识库毫无意义,但企业本身 ...
- python多个数列(列表)合并,合并后取值的方法
有时候需要从一个excel或者多个excel读取多列数据,然后传到后面的步骤内去执行操作 这里就涉及到把数据合并再分割的问题,比如下图excel数据,取出两列手机号和余额 思路,先从目标excel内逐 ...
- jmeter跨线程组传参的方法
Jmeter线程组下脚本,当设置好线程数后,该组下所有脚本均会执行对应的次数 测试场景: 1,后台登录新建拼团活动 2,获取拼团ID 3,多个会员前端登录,传入拼团ID参加拼团活动 要实现上面的测试场 ...
- [Ubuntu 20.04] 修复‘systemd-shutdown[1]: waiting for process: crond’需等待1分半钟的问题
由于在2020-2021年期间下载过Linux版本的Free Download Manager(简称FDM,一款免费但不开源的跨平台下载工具),而该软件的官网被挂了木马,因此在此期间下载安装过FDM的 ...
- Advanced pandas
Advanced pandas import numpy as np import pandas as pd Categorical Data This section introduces the ...