Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一、Zookeeper集群搭建
为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。
1.1 下载 & 解压
下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/
# 下载
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
# 解压
tar -zxvf zookeeper-3.4.14.tar.gz1.2 修改配置
拷贝三份 zookeeper 安装包。分别进入安装目录的 conf 目录,拷贝配置样本 zoo_sample.cfg 为 zoo.cfg 并进行修改,修改后三份配置文件内容分别如下:
zookeeper01 配置:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/01
dataLogDir=/usr/local/zookeeper-cluster/log/01
clientPort=2181
# server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里
# 指名集群间通讯端口和选举端口
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389如果是多台服务器,则集群中每个节点通讯端口和选举端口可相同,IP 地址修改为每个节点所在主机 IP 即可。
zookeeper02 配置,与 zookeeper01 相比,只有 dataLogDir 和 dataLogDir 不同:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/02
dataLogDir=/usr/local/zookeeper-cluster/log/02
clientPort=2182
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389zookeeper03 配置,与 zookeeper01,02 相比,也只有 dataLogDir 和 dataLogDir 不同:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/03
dataLogDir=/usr/local/zookeeper-cluster/log/03
clientPort=2183
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389配置参数说明:
- tickTime:用于计算的基础时间单元。比如 session 超时:N*tickTime;
- initLimit:用于集群,允许从节点连接并同步到 master 节点的初始化连接时间,以 tickTime 的倍数来表示;
- syncLimit:用于集群, master 主节点与从节点之间发送消息,请求和应答时间长度(心跳机制);
- dataDir:数据存储位置;
- dataLogDir:日志目录;
- clientPort:用于客户端连接的端口,默认 2181
1.3 标识节点
分别在三个节点的数据存储目录下新建 myid 文件,并写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 leader 节点。
创建存储目录:
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/01
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/02
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/03创建并写入节点标识到 myid 文件:
#server1
echo "1" > /usr/local/zookeeper-cluster/data/01/myid
#server2
echo "2" > /usr/local/zookeeper-cluster/data/02/myid
#server3
echo "3" > /usr/local/zookeeper-cluster/data/03/myid1.4 启动集群
分别启动三个节点:
# 启动节点1
/usr/app/zookeeper-cluster/zookeeper01/bin/zkServer.sh start
# 启动节点2
/usr/app/zookeeper-cluster/zookeeper02/bin/zkServer.sh start
# 启动节点3
/usr/app/zookeeper-cluster/zookeeper03/bin/zkServer.sh start1.5 集群验证
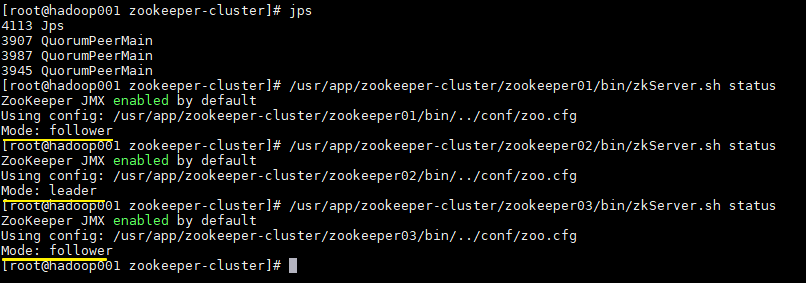
使用 jps 查看进程,并且使用 zkServer.sh status 查看集群各个节点状态。如图三个节点进程均启动成功,并且两个节点为 follower 节点,一个节点为 leader 节点。
二、Kafka集群搭建
2.1 下载解压
Kafka 安装包官方下载地址:http://kafka.apache.org/downloads ,本用例下载的版本为 2.2.0,下载命令:
# 下载
wget https://www-eu.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
# 解压
tar -xzf kafka_2.12-2.2.0.tgz这里 j 解释一下 kafka 安装包的命名规则:以
kafka_2.12-2.2.0.tgz为例,前面的 2.12 代表 Scala 的版本号(Kafka 采用 Scala 语言进行开发),后面的 2.2.0 则代表 Kafka 的版本号。
2.2 拷贝配置文件
进入解压目录的 config 目录下 ,拷贝三份配置文件:
# cp server.properties server-1.properties
# cp server.properties server-2.properties
# cp server.properties server-3.properties2.3 修改配置
分别修改三份配置文件中的部分配置,如下:
server-1.properties:
# The id of the broker. 集群中每个节点的唯一标识
broker.id=0
# 监听地址
listeners=PLAINTEXT://hadoop001:9092
# 数据的存储位置
log.dirs=/usr/local/kafka-logs/00
# Zookeeper连接地址
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183server-2.properties:
broker.id=1
listeners=PLAINTEXT://hadoop001:9093
log.dirs=/usr/local/kafka-logs/01
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183server-3.properties:
broker.id=2
listeners=PLAINTEXT://hadoop001:9094
log.dirs=/usr/local/kafka-logs/02
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183这里需要说明的是 log.dirs 指的是数据日志的存储位置,确切的说,就是分区数据的存储位置,而不是程序运行日志的位置。程序运行日志的位置是通过同一目录下的 log4j.properties 进行配置的。
2.4 启动集群
分别指定不同配置文件,启动三个 Kafka 节点。启动后可以使用 jps 查看进程,此时应该有三个 zookeeper 进程和三个 kafka 进程。
bin/kafka-server-start.sh config/server-1.properties
bin/kafka-server-start.sh config/server-2.properties
bin/kafka-server-start.sh config/server-3.properties2.5 创建测试主题
创建测试主题:
bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 \
--replication-factor 3 \
--partitions 1 --topic my-replicated-topic创建后可以使用以下命令查看创建的主题信息:
bin/kafka-topics.sh --describe --bootstrap-server hadoop001:9092 --topic my-replicated-topic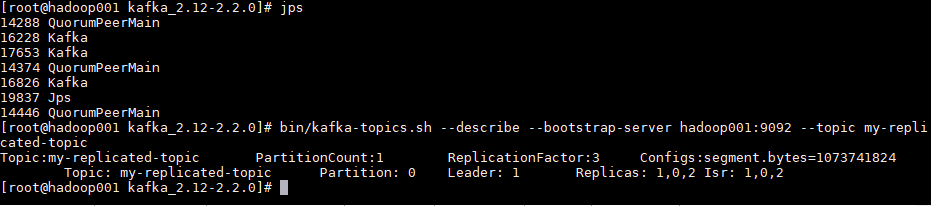
可以看到分区 0 的有 0,1,2 三个副本,且三个副本都是可用副本,都在 ISR(in-sync Replica 同步副本) 列表中,其中 1 为首领副本,此时代表集群已经搭建成功。
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群的更多相关文章
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 二.前置条件 三.Spark集群搭建 3.1 下载解压 3.2 配置环境变量 3.3 集群配置 3.4 安装包分发 四.启 ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于Docker-compose搭建Redis高可用集群-哨兵模式(Redis-Sentinel)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_110 我们知道,Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3) ...
- 基于docker实现redis高可用集群
基于docker实现redis高可用集群 yls 2019-9-20 简介 基于docker和docker-compose 使用redis集群和sentinel集群,达到redis高可用,为缓存做铺垫 ...
随机推荐
- Bean property 'transactionManagerBeanName' is not writable or has an invalid set
[2017-02-07 11:38:48,458]-[localhost-startStop-1]-[org.springframework.beans.factory.support.Default ...
- ElementUI 简要源码解析——Basic篇
Layout 布局 row 布局组件中的父组件,用于控制子组件.很简单的一个布局标签,主要通过 justify 和 align 控制子元素的对齐方式,使用 render 函数通过传入的 tag 属性控 ...
- [Noi2002]Savage 题解
[Noi2002]Savage 时间限制: 5 Sec 内存限制: 64 MB 题目描述 输入 第1行为一个整数N(1<=N<=15),即野人的数目. 第2行到第N+1每行为三个整数Ci ...
- re模块:模式匹配与正则表达式
一.用正则表达式查找文本模式 正则表达式,简称regex,是文本模式的描述方法.比如\d是一个正则表达式,用于表示一位0~9的数字.在一个模式后面加上花括号包围的数字n(如{n}),表示匹配这个模式n ...
- 6.1.初识Flutter应用之实现一个计数器
用Android Studio和VS Code创建的Flutter应用模板是一个简单的计数器示例,本节先仔细讲解一下这个计数器Demo的源码,让读者对Flutter应用程序结构有个基本了解,在随后小节 ...
- Android基础知识复习之打开照相机拍照并获取照片
对于我来说,做一件事情: 首先要理清我的思路,我要打开照相机,我能想到的是:在Android中我要打开系统应用,肯定需要一个隐式意图,那就要查询Android照相机的源码,查看并找到意图过滤器的书写方 ...
- TP框架基础(一)
[使用框架] 官网:thinkphp.cn. 目前建议使用thinkPHP3.2版本 一.结构目录>Thinkphp文件夹,是thinkPHP的核心文件,里面的内容是不允许我们修改的 > ...
- 详述Spring对数据校验支持的核心API:SmartValidator
每篇一句 要致富,先修路.要使用,先...基础是需要垒砌的,做技术切勿空中楼阁 相关阅读 [小家Java]深入了解数据校验:Java Bean Validation 2.0(JSR303.JSR349 ...
- jsp的简介(2)
JSP(JavaServer Pages )是什么? JavaServer Pages(JSP)是一种支持动态内容开发的网页技术它可以帮助开发人员通过利用特殊的JSP标签,其中大部分以<%开始并 ...
- http状态码 500-599
类比: 客户端:客人 服务器:便利店 http报文:中文语言+钱 500:服务器内部错误,无法完成请求 客户端:给我一瓶可乐 服务器:对不起,不能给你服务,本店昨天起火烧了 501:服务器不支持请求的 ...