十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装
1、首先,终端执行命令升级pip: python -m pip install --upgrade pip
2、安装,wheel(建议网络安装) pip install wheel
3、安装,lxml(建议下载安装)
4、安装,Twisted(建议下载安装)
5、安装,Scrapy(建议网络安装) pip install Scrapy
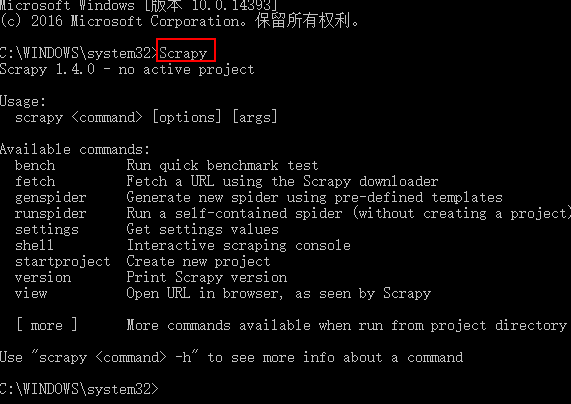
测试Scrapy是否安装成功
Scrapy框架指令
scrapy -h 查看帮助信息
Available commands:
bench Run quick benchmark test (scrapy bench 硬件测试指令,可以测试当前服务器每分钟最多能爬多少个页面)
fetch Fetch a URL using the Scrapy downloader (scrapy fetch http://www.iqiyi.com/ 获取一个网页html源码)
genspider Generate new spider using pre-defined templates ()
runspider Run a self-contained spider (without creating a project) ()
settings Get settings values ()
shell Interactive scraping console ()
startproject Create new project (cd 进入要创建项目的目录,scrapy startproject 项目名称 ,创建scrapy项目)
version Print Scrapy version ()
view Open URL in browser, as seen by Scrapy ()
创建项目以及项目说明
scrapy startproject adc 创建项目
项目说明
目录结构如下:
├── firstCrawler
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
scrapy.cfg: 项目的配置文件tems.py: 项目中的item文件,用来定义解析对象对应的属性或字段。pipelines.py: 负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库)settings.py: 项目的设置文件.- spiders:实现自定义爬虫的目录
- middlewares.py:Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。

项目指令
项目指令是需要cd进入项目目录执行的指令
scrapy -h 项目指令帮助
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version (scrapy version 查看scrapy版本信息)
view Open URL in browser, as seen by Scrapy (scrapy view http://www.zhimaruanjian.com/ 下载一个网页并打开)
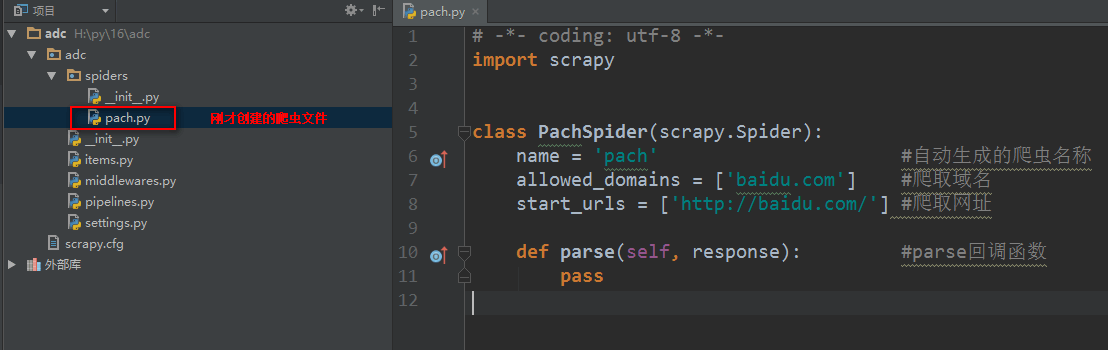
创建爬虫文件
创建爬虫文件是根据scrapy的母版来创建爬虫文件的
scrapy genspider -l 查看scrapy创建爬虫文件可用的母版
Available templates:母版说明
basic 创建基础爬虫文件
crawl 创建自动爬虫文件
csvfeed 创建爬取csv数据爬虫文件
xmlfeed 创建爬取xml数据爬虫文件
创建一个基础母版爬虫,其他同理
scrapy genspider -t 母版名称 爬虫文件名称 要爬取的域名 创建一个基础母版爬虫,其他同理
如:scrapy genspider -t basic pach baidu.com
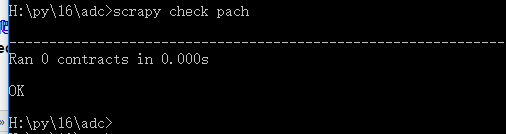
scrapy check 爬虫文件名称 测试一个爬虫文件是否合规
如:scrapy check pach
scrapy crawl 爬虫名称 执行爬虫文件,显示日志 【重点】
scrapy crawl 爬虫名称 --nolog 执行爬虫文件,不显示日志【重点】
十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令的更多相关文章
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- Scrapy框架爬虫
一.sprapy爬虫框架 pip install pypiwin32 1) 创建爬虫框架 scrapy startproject Project # 创建爬虫项目 You can start your ...
随机推荐
- Android studio 如何快速收起代码?
windows下 ctrl+shift+(小键盘上的减号 -) mac下 commang+shift+减号,搞定
- 对数值数据的格式化处理(保留小数点后N位)
项目中有时会遇到对数值部分进行保留操作,列如保留小数点后2位,所有的数据都按这种格式处理, //保留小数点后2位,都按这种格式处理,没有补0 DecimalFormat df = new Decima ...
- (转)RTP-H264封包分析
rtp(H264)第一个包(单一NAL单元模式)————-sps 80 {V=10,p=0,x=0,cc=0000} 60 {m=0,pt=110 0000} 53 70{sequence numbe ...
- mapreduce数据不平衡时的处理方法
用mr处理大数据经常遇到数据不平衡的情况,这里的数据不平衡指的是,数据中有少部分key集中了大量的数据,导致其它的reduce都运行完了,只剩几个reduce在跑.这种情况一般有如下三种解决方法(原理 ...
- 中文Appium API 文档
该文档是Testerhome官方翻译的源地址:https://github.com/appium/appium/tree/master/docs/cn官方网站上的:http://appium.io/s ...
- iOS导入高德地图出现缺失armv7--"Undefined symbols for architecture armv7"
在已有项目中使用pod导入高德地图,报了以下错误: ld: warning: directory not found for option '-L/Users/paul/iOS/yun-hui-yi/ ...
- netty2---服务端和客户端
客户端: package com.client; import java.net.InetSocketAddress; import java.util.Scanner; import java.ut ...
- shiro的Realm
public class UserRealm extends AuthorizingRealm { private UserService userService = new UserServiceI ...
- Asp.Net中OnClientClick与OnClick的区别
当我们当击这个按钮时,自动先执行的客户端,再执行服务器端的.如果客户端返回的是false,那么服务器端对应的方法永远不会执行.这样就达到检测,只有通过才去执行服务器端的方法.
- Kali更新源,亲测目前可用的源
kali更新的时候老是无法定位软件包,网络上大部分中科大.阿里云kali源都不可用,都千篇一律,最后找了这个,网易的,还不错,贴出来大家看看: # 源 deb http://mirrors.163.c ...