python爬虫学习笔记(1)
一、请求一个网页内容打印
爬取某个网页:
from urllib import request
# 需要爬取的网页
url = "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9085796282359478067%22%7D&n_type=0&p_from=1"
# 打开网页,并返回
rsp = request.urlopen(url)
# 读取返回的结果
html = rsp.read()
# 由于rsp返回的是流文件需要解码
html = html.decode()
printf(html)
爬取一个网页的基本流程:
1、获取所需网页request.urlopen("网页链接")
2、读取返回页面 rsp.read()
3、解码:html.decode()
二、自动识别网页编码
from urllib import request
import chardet
url = "https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9085796282359478067%22%7D&n_type=0&p_from=1"
res = request.urlopen(url)
html = res.read()
# 检查编码
cs = chardet.detect(html)
# 编码设置
html = html.decode(cs.get("encoding", "utf-8"))
print(html)
第7行返回一个类似{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}的字典 encoding是编码格式,confidence是前面编码格式的概率。第九行进行解码设置,如果有匹配的编码按照获取的方式进行解码,否则按照“utf-8”的方式解码。
三、到百度页面爬取指定内容
from urllib import request, parse
if __name__ =='__main__':
url = "http://www.baidu.com/s?"
# 输入关键词
wd = input("Input keyword:")
# 把关键字以字典保存
qs = {
"wd":wd
}
# 把关键字进行编码
qs = parse.urlencode(qs)
# 拼凑成完整的url
fullurl = url + qs
res = request.urlopen(fullurl)
html = res.read().decode()
print(html)
四、进行百度翻译:
解析:
1、打开F12
2、尝试输入单词,发现每输入一个字母都有请求
3、找到请求的地址:https://fanyi.baidu.com/sug
4、在NetWork-All-Headers中查看,发现FormData的关键字是 kw:单词
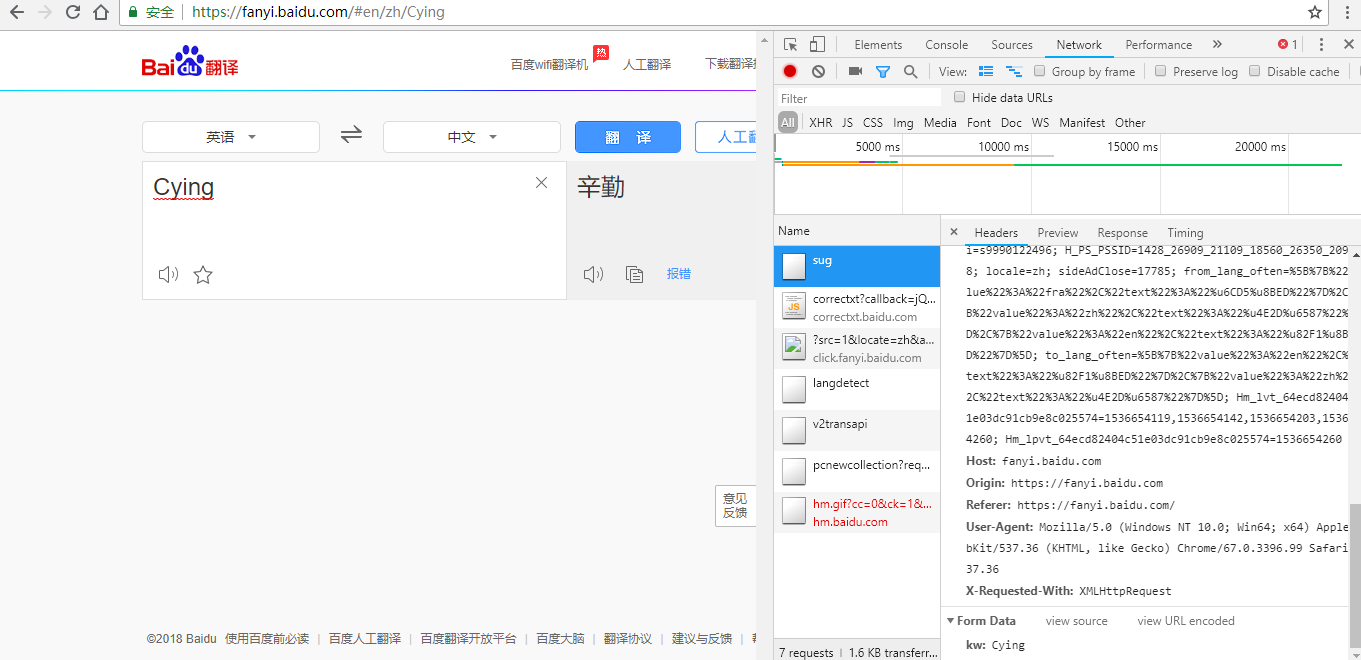
5、打开sug文件发现数据时json格式
方式一:
from urllib import request, parse
import json
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入单词: ")
data = {
"kw":word
}
# 对单词进行编码
data = parse.urlencode(data).encode()
# 构建请求头
rsp = request.urlopen(baseurl, data = data)
json_data = rsp.read().decode()
# 由于返回的是json数据,转换成字典
json_data = json.loads(json_data)
for item in json_data['data']:
print(item['k'], item['v'])
翻译流程:
1、利用data构造内容,然后用URLopen打开
2、返回一个json格式
3、转换成字典,输出
方式二:
from urllib import request, parse
import json
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入单词:")
data = {
"kw": word
}
data = parse.urlencode(data).encode('utf-8')
headers = {
'Content-Length':len(data)
}
req = request.Request(url = baseurl, data = data, headers = headers)
res = request.urlopen(req)
json_data = res.read().decode()
json_data = json.loads(json_data)
for item in json_data['data']:
print(item['k'], item['v])
五、urllib.error
在某些时候爬取网站出现问题,可以通过 URLError和HTTPError查找问题
1、URLError产生原因
- 没网
- 没有指定服务器
- 服务器连接失败
from urllib import request, error
if __name__ == '__main__':
url = "http://www.baidu.com"
try:
req = request.Request(url)
res = request.urlopen(req)
html = res.read().decode()
except error.URLError as e:
print("URLError: {0}".format(e.reason))
except Exception as e:
print(e)
2、HTTPError
HTTPError一般对应HTTP请求的返回码错误,如果返回的错误码是400以上引发HTTPError
与URLError的关系:
OSError -> URLError -> HTTPError
代码:
from urllib import request, error
if __name__ == '__main__':
url = "http://www.baidu.com"
try
req = request.Request(url)
res = request.urlopen(req)
html = res.read().decode()
except error.HTTPError as e:
print ("URLError: {0}".format(e.reason))
print ("HTTPError: {0}".format(e))
except error.URLError as e:
print ("URLError: {0}".format(e.reason))
print ("HTTPError: {0}".format(e))
except Exception as e:
print(e)
python爬虫学习笔记(1)的更多相关文章
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- python爬虫学习笔记
爬虫的分类 1.通用爬虫:通用爬虫是搜索引擎(Baidu.Google.Yahoo等)“抓取系统”的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 简单来讲就是尽可 ...
- Python、pip和scrapy的安装——Python爬虫学习笔记1
Python作为爬虫语言非常受欢迎,近期项目需要,很是学习了一番Python,在此记录学习过程:首先因为是初学,而且当时要求很快速的出demo,所以首先想到的是框架,一番查找选用了Python界大名鼎 ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- Python爬虫学习笔记——豆瓣登陆(一)
#-*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import html5lib import re import ...
- Python爬虫学习笔记-1.Urllib库
urllib 是python内置的基本库,提供了一系列用于操作URL的功能,我们可以通过它来做一个简单的爬虫. 0X01 基本使用 简单的爬取一个页面: import urllib2 request ...
- 【Python爬虫学习笔记(3)】Beautiful Soup库相关知识点总结
1. Beautiful Soup简介 Beautiful Soup是将数据从HTML和XML文件中解析出来的一个python库,它能够提供一种符合习惯的方法去遍历搜索和修改解析树,这将大大减 ...
- 【Python爬虫学习笔记(1)】urllib2库相关知识点总结
1. urllib2的opener和handler概念 1.1 Openers: 当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例).正常情况下,我们使 ...
- Python爬虫学习笔记(一)
概念: 使用代码模拟用户,批量发送网络请求,批量获取数据. 分类: 通用爬虫: 通用爬虫是搜索引擎(Baidu.Google.Yahoo等)"抓取系统"的重要组成部分. 主要目的是 ...
随机推荐
- qt 拷贝文件设置进度条
/** * @brief FuncModuleWin::copyFile * @param fromFIleName 优盘里面的文件 * @param toFileName 拷贝到/bin里面的启动文 ...
- 安装和测试Kafka
本文主要介绍如何在单节点上安装 Kafka 并测试 broker.producer 和 consumer 功能. 下载 进入下载页面:http://kafka.apache.org/downloads ...
- Linux下SVN安装配置及应用
一.安装篇 centos下yum安装 yum install subversion 查看安装是否成功: svnserve --version 二.配置篇 创建svn版本库目录 mkdir /home/ ...
- html5shiv.js和respond.js引入不起作用解决
当项目需求需要兼容ie7,8这些奇葩浏览器时,考虑到h5的便捷性及响应式,我们往往引入html5shiv.js和respond.js来让ie7,8兼容h5及一些响应式变化,引入时就需要用到条件注释,原 ...
- <!--注释-->和<%--注释--%>有什么区别
转载:版权所有:基础软件.作者邮箱:s.j.l.studio@hotmail.com,sun.j.l.studio@gmail.com.本文首发于 http://www.cnblogs.com/Fou ...
- 安装ale_python_interface时遇到make错误
1. 首先按照https://pypi.org/project/ale-python-interface/0.0.1/来安装,直接python3 -m pip 但提示缺少一个头文件ale_c_wrap ...
- C#图解教程读书笔记(第5章 方法)
类型推断和var关键字 从C#3.0开始,可以在变量声明的开始部分的的位置使用新的关键字var. Var关键字并不是某种特别类型的符号.它只是句法上的速记,表示任何可以从初始化的右边推断出的类型. V ...
- 自动生成气泡对话框的jQuery插件CreateBubble.js
之前在写一个界面,想要用到气泡,然而一直找不到现成的有效地办法,是在没有办法了我只好自己写一个,于是就有了现在的CreateBubble.js.很简单的一个函数,但是非常实用. 使用方法: 1.HTM ...
- UVa 10384 - The Wall Pushers
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- 【[USACO13NOV]没有找零No Change】
其实我是点单调队列的标签进来的,之后看着题就懵逼了 于是就去题解里一翻,发现楼上楼下的题解说的都好有道理, f[j]表示一个再使用一个硬币就能到达i的某个之前状态,b[now]表示使用那个能使状态j变 ...