Paper | Toward Convolutional Blind Denoising of Real Photographs
发表在2019 CVPR。
摘要
While deep convolutional neural networks (CNNs) have achieved impressive success in image denoising with additive white Gaussian noise (AWGN), their performance remains limited on real-world noisy photographs. The main reason is that their learned models are easy to overfit on the simplified AWGN model which deviates severely from the complicated real-world noise model. In order to improve the generalization ability of deep CNN denoisers, we suggest training a convolutional blind denoising network (CBDNet) with more realistic noise model and real-world noisy-clean image pairs. On the one hand, both signal-dependent noise and in-camera signal processing pipeline is considered to synthesize realistic noisy images. On the other hand, real-world noisy photographs and their nearly noise-free counterparts are also included to train our CBDNet. To further provide an interactive strategy to rectify denoising result conveniently, a noise estimation subnetwork with asymmetric learning to suppress under-estimation of noise level is embedded into CBDNet. Extensive experimental results on three datasets of real-world noisy photographs clearly demonstrate the superior performance of CBDNet over state-of-the-arts in terms ofquantitative metrics and visual quality. The code has been made available at https://github.com/GuoShi28/CBDNet.
结论
We presented a CBDNet for blind denoising of realworld noisy photographs. The main findings of this work are two-fold. First, realistic noise model, including heterogenous Gaussian and ISP pipeline, is critical in making the learned model from synthetic images be applicable to real-world noisy photographs. Second, the denoising performance of a network can be boosted by incorporating both synthetic and real noisy images in training. Moreover, by introducing a noise estimation subnetwork into CBDNet, we were able to utilize asymmetric loss to improve its generalization ability to real-world noise, and perform interactive denoising conveniently.
要点:
现有的方法大多建立在AWGN上,在实际样本上效果不好。作者认为是AWGN模型太简单,过拟合了。
Existing CNN denoisers tend to be over-fitted to Gaussian noise and generalize poorly to real-world noisy images with more sophisticated noise.
作者对现实噪声尝试了建模,并且在训练集中加入了很多生成样本。包括:signal-dependent noise和in-camera signal processing pipeline。
CBDNet中包括了一个预测噪声的子网络。其训练采用的是非对称的loss,着重惩罚对噪声的低估(在FFDNet中我们看到,宁可高估噪声,不可低估噪声)。
贡献:
提出了一个盲去噪网络CBDNet,其中一个子网络用于预测噪声水平、输出噪声水平图,第二个子网络即完成非盲去噪。两个子网络的损失项合并起来,end-to-end训练。
在训练时混合了生成噪声和真实噪声。
局限:
- 能否有效地剥离噪声预测和盲去噪模块?作者通过真实噪声图(只有生成噪声才有)监督,以及TV平滑规范,强迫输出为平滑的噪声水平图。但真实效果(能否很好地独立)未知。
故事背景
在真实的相机系统(real camera system)中,图像噪声的来源多种多样,例如暗电流噪声(dark current noise)、短噪声(short noise)和热噪声(thermal noise)。进一步,图像还会在相机内部的处理流程(in-camera processing, ISP)中进一步加噪,例如去马赛克(demosaicing)、伽马校正(Gamma correction)和压缩(compression)。显然,这些噪声与简单的AWGN截然不同。
建模现实噪声
根据[14,45],泊松高斯分布(可近似为heteroscedastic Gaussian of a signal-dependent and a stationary noise components)更适用于建模真实噪声。此外还有相机内部的处理,使得噪声与空域位置和色彩有关(makes the noise spatially and chromatically correlated)。
具体而言,光成像(photon sensing)导致的噪声由泊松分布刻画,而其余的静态干扰由高斯分布刻画。
再进一步,我们可以用异方差的高斯分布近似:
Practically, the noise produced by photon sensing can be modeled as Poisson, while the remaining stationary disturbances can be modeled as Gaussian. Poisson-Gaussian thus provides a reasonable noise model for the raw data of imaging sensors [14], and can be further approximated with a heteroscedastic Gaussian.

ISP没看懂,见1714页。其考虑了相机响应函数CRF、RGB到拜耳图像的转换M、去马赛克函数DF、生成辐照图像的L以及JPEG压缩,但没有考虑量化噪声。JPEG量化系数QF和图像方差(泊松和高斯)都在一定范围内变化。
因此在本文中,我们同时考虑泊松-高斯模型和ISP(实验证明ISP很重要)。
具体而言,我们将生成噪声图像和真实噪声图像一起用于训练CBDNet。
CBDNet
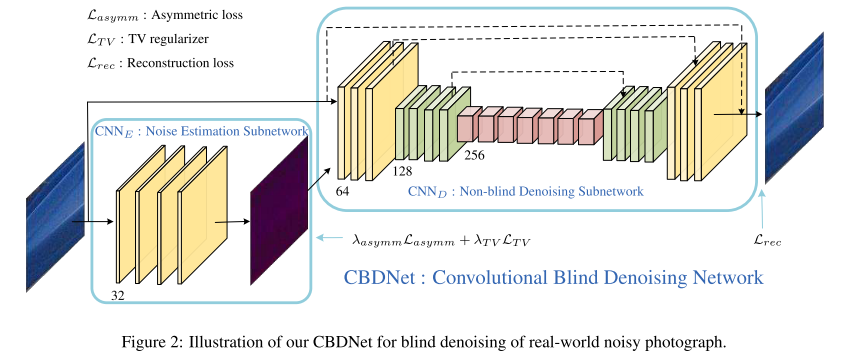
CBDNet分为两个子网络:噪声预测网络CNN_E和非盲去噪网络CNN_D。
理想状况下,CNN_E将会输出噪声水平图,其大小与输入图像大小一样。噪声水平图和原输入一起,输入CNN_D,实现去噪。
噪声水平图在输入CNN_D之前,可以被人为地适当修改。作者设了一个乘子\(\gamma\),对噪声水平图进行点乘。
CNN_E是一个五层CNN,没有BN和池化。每一层都有32个通道,都是\(3 \times 3\)卷积。
CNN_D采用的是16层的U-Net结构。并且整体学习的是残差(头尾引入了短连接)。其中有大量的短连接、跨步卷积和转置卷积,可以捕捉多尺度信息,同时扩大感受野。所有滤波器都是\(3 \times 3\)的。除了最后一层,其余都使用ReLU非线性激活。
实验发现,BN对真实噪声的去除帮助微乎其微。可能的原因是真实噪声非高斯分布。
作者引入CNN_E的原因有两个:
可以通过调节噪声水平图,来调整去噪程度。
在FFDNet等工作中发现,引入噪声水平图可以达到更好的性能,特别是当噪声程度较大时。
非对称损失
比起低估噪声损失,我们更倾向于高估噪声损失。原因:
Both CNN and traditional non-blind denoisers perform robustly when the input noise SD. is higher than the ground-truth one (i.e., over-estimation error), which encourages us to adopt asymmetric loss for improving generalization ability of CBDNet.
并且在FFDNet中,作者也发现高估噪声几乎不会影响效果,但低估影响很严重。因此,作者在损失函数的设计上,更着重惩罚低估噪声。
此外,作者还引入了TV正则化项,保证预测噪声水平图的平滑性。
数据库
通过我们的建模,我们可以获得大量生成数据。具体而言,作者从多个数据集中获取了很多RGB图像,然后通过ISP的反变换,得到“干净、无损”的图像。然后再加噪甚至压缩。
但对于真实有噪图像,我们很难获得其无损图像。文献[43,45,1]说可以通过对同一场景的多张有噪图像取平均,但这样做很难:要保证静态,同时要有多张图像。因此作者也采取了上述方式?(作者没说清楚)数据库来源于[4]。
但当输入batch为真实有噪图像时,由于噪声标准差不可知,因此loss只衡量去噪保真项,不衡量噪声估计损失和正则项。
实验
有点可惜的是,作者没有探究decorrelation的程度,以及噪声预测的效率。作者通过这个实验,探究了互动性:

可见,随着噪声水平预测图放大系数的不断提高,去噪强度也在增强。
Paper | Toward Convolutional Blind Denoising of Real Photographs的更多相关文章
- Toward Convolutional Blind Denoising of Real Photographs
本文提出了一个针对真实图像的盲卷积去噪网络,增强了深度去噪模型的鲁棒性和实用性. 摘要 作者提出了一个 CBD-Net,由噪声估计子网络和去噪子网络两部分组成. 作者设计了一个更加真实的噪声模型,同时 ...
- Paper Read: Convolutional Image Captioning
Convolutional Image Captioning 2018-11-04 20:42:07 Paper: http://openaccess.thecvf.com/content_cvpr_ ...
- Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1705.03122 Motivation: Compared to recurrent layers, convol ...
- Paper Reading - Convolutional Image Captioning ( CVPR 2018 )
Link of the Paper: https://arxiv.org/abs/1711.09151 Motivation: LSTM units are complex and inherentl ...
- Paper | U-Net: Convolutional Networks for Biomedical Image Segmentation
目录 故事背景 U-Net 具体结构 损失 数据扩充 发表在2015 MICCAI.原本是一篇医学图像分割的论文,但由于U-Net杰出的网络设计,得到了8k+的引用. 摘要 There is larg ...
- 读paper:Deep Convolutional Neural Network using Triplets of Faces, Deep Ensemble, andScore-level Fusion for Face Recognition
今天给大家带来一篇来自CVPR 2017关于人脸识别的文章. 文章题目:Deep Convolutional Neural Network using Triplets of Faces, Deep ...
- Paper | Learning convolutional networks for content-weighted image compression
目录 摘要 故事要点 模型训练 发表在2018年CVPR. 以下对于一些专业术语的翻译可能有些问题. 摘要 有损压缩是一个优化问题,其优化目标是率失真,优化对象是编码器.量化器和解码器(同时优化). ...
- CV code references
转:http://www.sigvc.org/bbs/thread-72-1-1.html 一.特征提取Feature Extraction: SIFT [1] [Demo program][SI ...
- CV codes代码分类整理合集 《转》
from:http://www.sigvc.org/bbs/thread-72-1-1.html 一.特征提取Feature Extraction: SIFT [1] [Demo program] ...
随机推荐
- Noip2018Day1T3 赛道修建
题目链接 problem 给出一棵有边权的树.一条链的权值定义为该链所经过的边的边权值和.需要选出\(m\)条链,求\(m\)条链中权值最小的链的权值最大是多少. solution 首先显然二分. 然 ...
- 趣谈Linux操作系统学习笔记:第二十九讲
一.引子 在这之前,有一点你需要注意.解析系统调用是了解内核架构最有力力的一把钥匙,这里我们只要重点关注这几个最重要的系统调用就可以了 1.mount 系统调用用于挂载文件系统:2.open 系统调用 ...
- CSharpGL(54)用基于图像的光照(IBL)来计算PBR的Specular部分
CSharpGL(54)用基于图像的光照(IBL)来计算PBR的Specular部分 接下来本系列将通过翻译(https://learnopengl.com)这个网站上关于PBR的内容来学习PBR(P ...
- Java开发桌面程序学习(12)——Javafx 悬浮窗提示 tooptip
Javafx 悬浮窗提示 tooptip 鼠标悬浮在某个控件,弹出提示,效果如下: 代码: //control是某个控件 Tooltip.install(control, new Tooltip(&q ...
- 死磕 java同步系列之AQS终篇(面试)
问题 (1)AQS的定位? (2)AQS的重要组成部分? (3)AQS运用的设计模式? (4)AQS的总体流程? 简介 AQS的全称是AbstractQueuedSynchronizer,它的定位是为 ...
- SSM(七)在JavaWeb应用中使用Redis
前言 先来看一张效果图: 作用就是在每次查询接口的时候首先判断Redis中是否有缓存,有的话就读取,没有就查询数据库并保存到Redis中,下次再查询的话就会直接从缓存中读取了.Redis中的结果:之后 ...
- Linux网络——查看网络连接情况的命令
Linux网络——查看网络连接情况的命令 摘要:本文主要学习了Linux中用来查看网络连接情况的命令. hostname命令 hostname命令用于显示和设置系统的主机名称,设置只是临时生效,永久生 ...
- VS中怎样对C#项目进行单元测试
场景 SpringBoot+Junit在IDEA中实现查询数据库的单元测试: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/927 ...
- Qt Creator单步调试快捷键F10经常失灵问题
使用Qt Creator调试程序的时候经常会遇到F10单步调试快捷键不响应的问题. 打开调试菜单如下:有两个快捷键为F10的调试菜单项,于是快捷键冲突了! 解决办法:废话不说,直接上图 由于Start ...
- 微信跳转外部浏览器下载app原理
在我们使用微信营销的时候,很容易碰到推广连接在微信内无法打开或无法下载app的情况.通常这种情况微信会给个提示 “已停止访问该网址” ,那么导致这个情况的因素有哪些呢,主要有以下三点 1.网页链接被举 ...