Paper Read: Convolutional Image Captioning
Convolutional Image Captioning
2018-11-04 20:42:07
Code: https://github.com/aditya12agd5/convcap
Related Papers:
1. Convolutional Sequence to Sequence Learning Paper Code
常规的 image caption 的任务都是基于 CNN-LSTM 框架来实现的。因为其中有关于 language 的东西,一般采用 RNN 网络模型来处理句子。虽然在很多benchmark 上取得了惊人的效果,但是 LSTM 的训练是一个令人头大的问题。因为他的训练速度特别的慢。所以就有人考虑用 cnn 来处理句子编码的问题,首次提出这种思想的是 Facebook 组的工作。

本文将这种思路引入到 image caption 中,利用 卷积的思路来做这个 task,网络结构如下所示:

在次基础之上,提出了如下的 model:
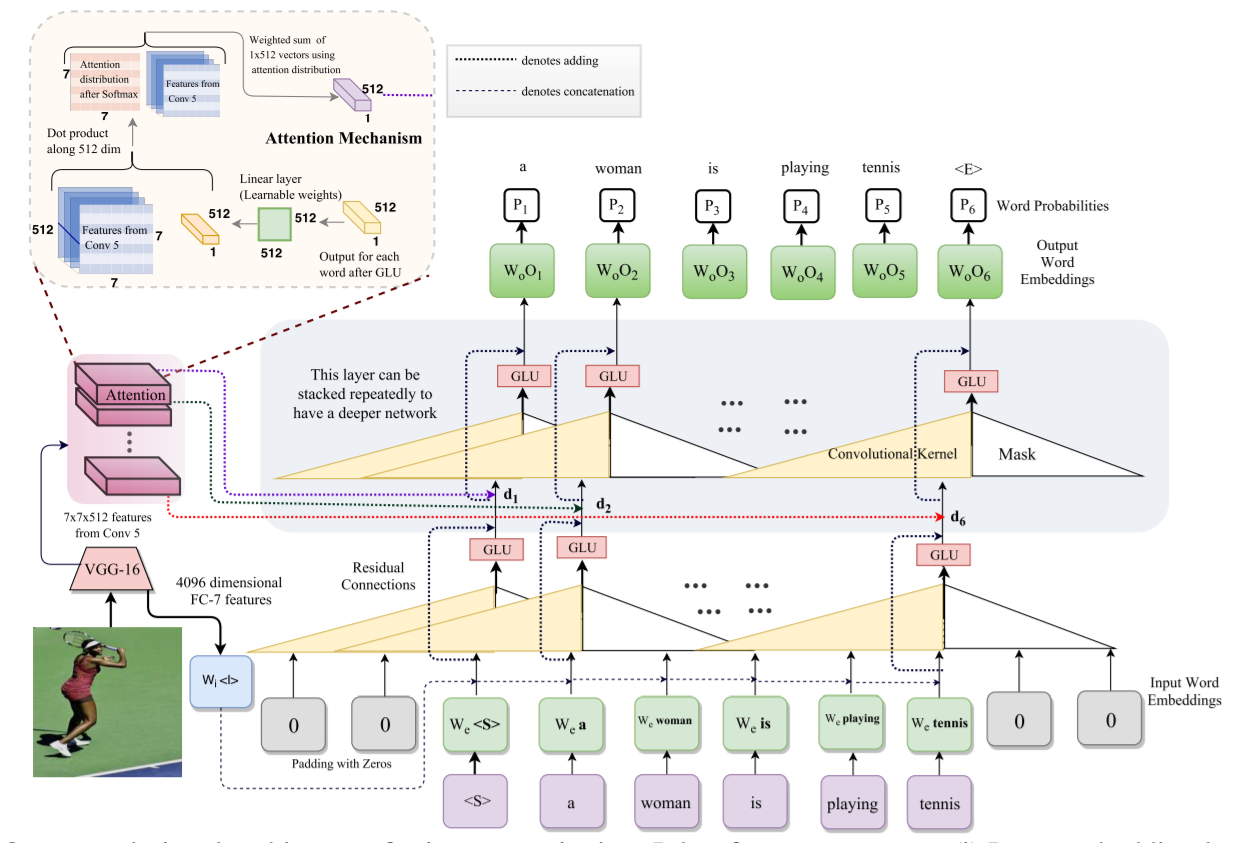
大致思路如下:
1. 首先对给定的句子进行填充(最大句子长度为 15,不足的就补 0),进行 embedding,得到对应的向量表示;
2. 然后用 1-D 的卷积,处理这些一维信号,得到 hidden state,然后输入到 GLU 激活函数当中,然后得到了 embedding 之后的向量;这里的 cnn layer 可以堆叠成多个 layer,以达到 deeper 的效果;
本文模型用了三层该网络;并且用了残差链接,以得到更好的效果;
3. 与此同时,作者用 CNN 提取图像的特征,将图像的特征与文本进行 attention 的计算,得到加权之后的 feature;以得到更好地效果;
4. 然后利用最大化后验概率的方式,给定当前输入,来预测下一个单词是什么。训练采用 Binary Cross-Entropy Loss 来进行。
其中的细节:

1. Attention 的计算(利用 Word embedding 对 visual feature map 进行 attention 计算):
作者提取 VGG 中 Conv-5 的特征,此时 feature map 的大小为:7*7*512,而 language 中 Word 进行 embedding 后,每一个单词的大小为:512-D。
于是,利用 show,attend and tell 那篇 image caption 文章的 soft-attention 思想,作者也将 text 和 visual feature 进行对齐操作,即:
首先将 512*1 的 vector 的转置,与可学习的权重 512*512 的 weight W,进行相乘,得到 512-D 的向量,然后将该向量与 feature map 上每一个位置上的 channel feature (1*512 D feature)进行点乘,得到一个 512-D 的 feature,于是,w*h 那么大的 feature map,就可以得到一个 w*h 的 权重分布图,即本文中的 7*7 的 attention distribution。用这个权重 和 每一个 channel 的 feature 进行点乘,相加,得到 512*1-D 的特征。
==
Paper Read: Convolutional Image Captioning的更多相关文章
- Paper Reading - Convolutional Image Captioning ( CVPR 2018 )
Link of the Paper: https://arxiv.org/abs/1711.09151 Motivation: LSTM units are complex and inherentl ...
- Paper Reading - Convolutional Sequence to Sequence Learning ( CoRR 2017 ) ★
Link of the Paper: https://arxiv.org/abs/1705.03122 Motivation: Compared to recurrent layers, convol ...
- Paper | U-Net: Convolutional Networks for Biomedical Image Segmentation
目录 故事背景 U-Net 具体结构 损失 数据扩充 发表在2015 MICCAI.原本是一篇医学图像分割的论文,但由于U-Net杰出的网络设计,得到了8k+的引用. 摘要 There is larg ...
- 读paper:Deep Convolutional Neural Network using Triplets of Faces, Deep Ensemble, andScore-level Fusion for Face Recognition
今天给大家带来一篇来自CVPR 2017关于人脸识别的文章. 文章题目:Deep Convolutional Neural Network using Triplets of Faces, Deep ...
- Paper | Toward Convolutional Blind Denoising of Real Photographs
目录 故事背景 建模现实噪声 CBDNet 非对称损失 数据库 实验 发表在2019 CVPR. 摘要 While deep convolutional neural networks (CNNs) ...
- Paper | Learning convolutional networks for content-weighted image compression
目录 摘要 故事要点 模型训练 发表在2018年CVPR. 以下对于一些专业术语的翻译可能有些问题. 摘要 有损压缩是一个优化问题,其优化目标是率失真,优化对象是编码器.量化器和解码器(同时优化). ...
- [ Continuously Update ] The Paper List of Image / Video Captioning
Papers Published in 2018 Convolutional Image Captioning - Jyoti Aneja et al., CVPR 2018 - [ Paper Re ...
- Image Captioning 经典论文合辑
Image Caption: Automatically describing the content of an image domain:CV+NLP Category:(by myself, y ...
- ( 转) Awesome Image Captioning
Awesome Image Captioning 2018-12-03 19:19:56 From: https://github.com/zhjohnchan/awesome-image-capti ...
随机推荐
- linux的基本操作(文件压缩与打包)
文件的压缩与打包 在windows下我们接触最多的压缩文件就是.rar格式的了.但在linux下这样的格式是不能识别的,它有自己所特有的压缩工具.但有一种文件在windows和linux下都能使用那就 ...
- java学习之路--继承(多态的动态绑定)
动态绑定过程中,对象调用对象方的执行过程 1:编译器查看对象的声明类型和方法名.有可能有多个方法名相同,但参数类型不一样的重载方法. 2:编译器查看调用方法时提供的参数类型.该过程叫重载解析,在相同的 ...
- selenium+python爬虫环境搭建
前言: 准备使用selenium爬取网站数据,先搭建selenium+python爬虫环境搭建 系统环境: 64位win10系统,同时装python2.7和python3.6两个版本,IDE为pych ...
- springboot+mybatis+druid数据库连接池
参考博客https://blog.csdn.net/liuxiao723846/article/details/80456025 1.先在pom.xml中引入druid依赖包 <!-- 连接池 ...
- MOT大连站 | 卓越研发之路:前沿技术落地实践
还在讨论究竟哪种编程语言更容易深度学习?哪种编程语言更具有价值?如果你是资深技术人员又或者是团队负责人,在机器学习.微服务.Spring 5反应式编程等方面遇到了问题,不妨参加一场由msup和微软联合 ...
- ffmpeg的编译和安装
1. 先到ffmpeg官网上下载ffmpeg源码,然后配置.编译 http://ffmpeg.org/download.html 可以如下进行配置: ./configure --prefix=/usr ...
- 【转载】MDK环境下让STM32用上FreeRTOS v8.1.2和FreeRTOS+Trace v2.6.0全过程
[转载]https://www.amobbs.com/thread-5601460-1-2.html?_dsign=6a59067b 本人选择使用FreeRTOS的最大原因就是想使用FreeRTO ...
- Cartographer源码阅读(9):图优化的前端——闭环检测
约束计算 闭环检测的策略:搜索闭环,通过匹配检测是否是闭环,采用了分支定界法. 前已经述及PoseGraph的内容,此处继续.位姿图类定义了pose_graph::ConstraintBuilder ...
- web状态管理机制
引入:b/s(浏览器/服务器模式)区别于winform的是winform中只加载一次页面构造函数,而b/s中只要点击按钮或者其他涉及后台的操作都会调用后台代码.一般情况下为了防止服务器过载,b/s不会 ...
- 10个有趣的Python教程,附视频讲解+练手项目。
从前的日色变得慢,车.马.邮件都慢 一生只够爱一门编程语言 从前的教程也好看,画面精美有样子 你看了,立马就懂了 Python最性感的地方,就在于它的趣味性和前沿性,学习Python,你总能像科技节的 ...