第四十九篇 入门机器学习——数据归一化(Feature Scaling)

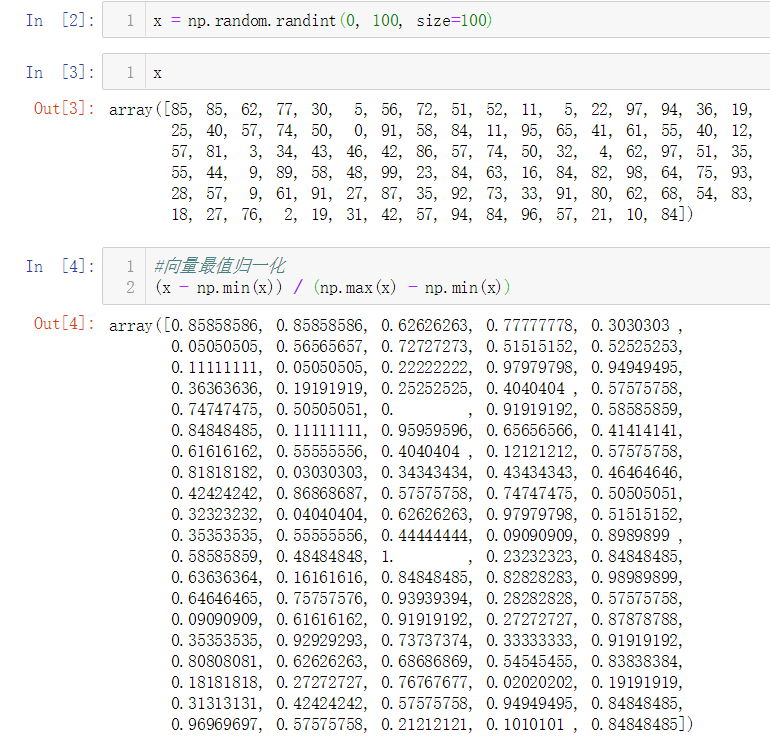
矩阵的最值归一化
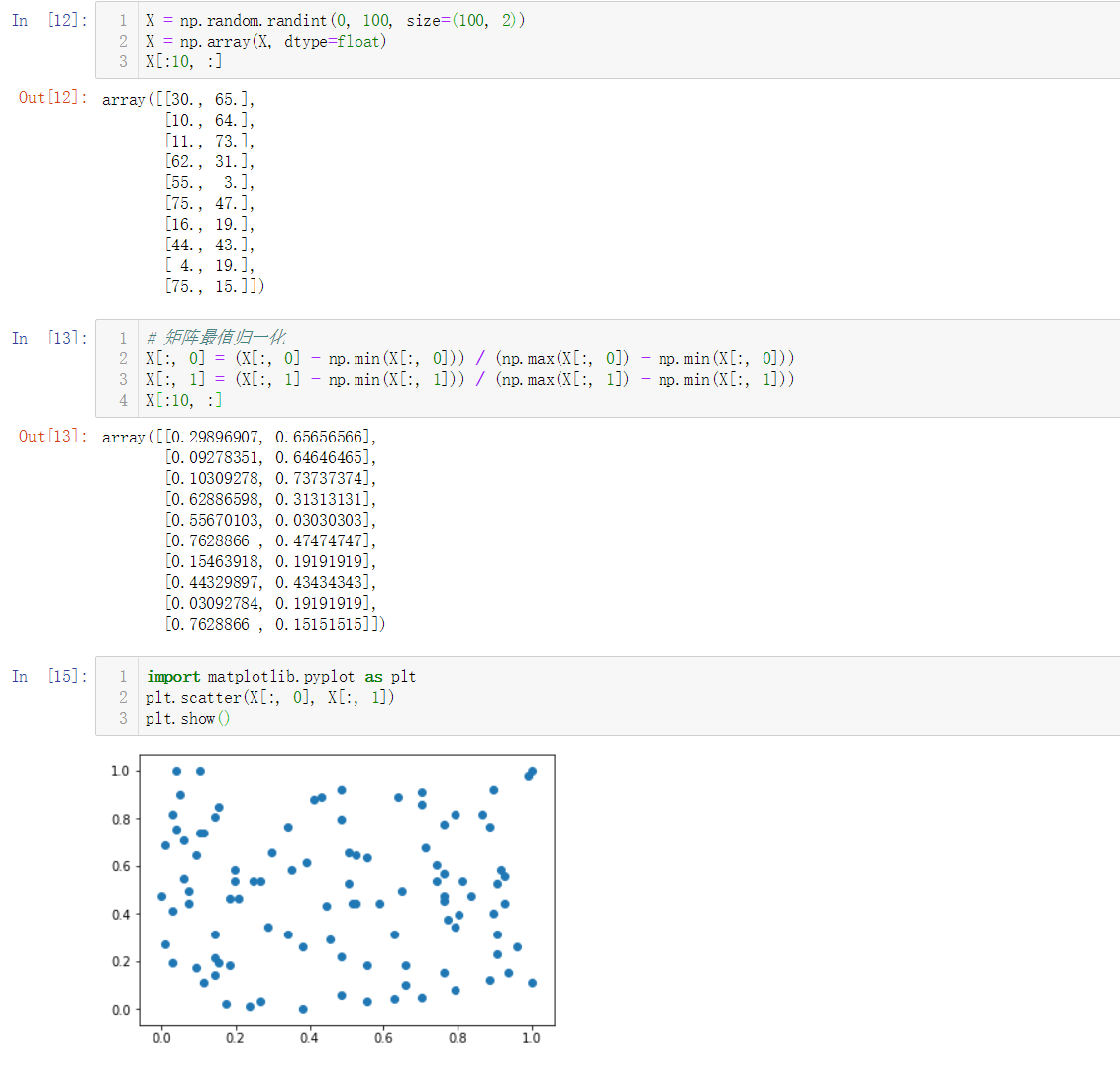
矩阵的均值方差归一化
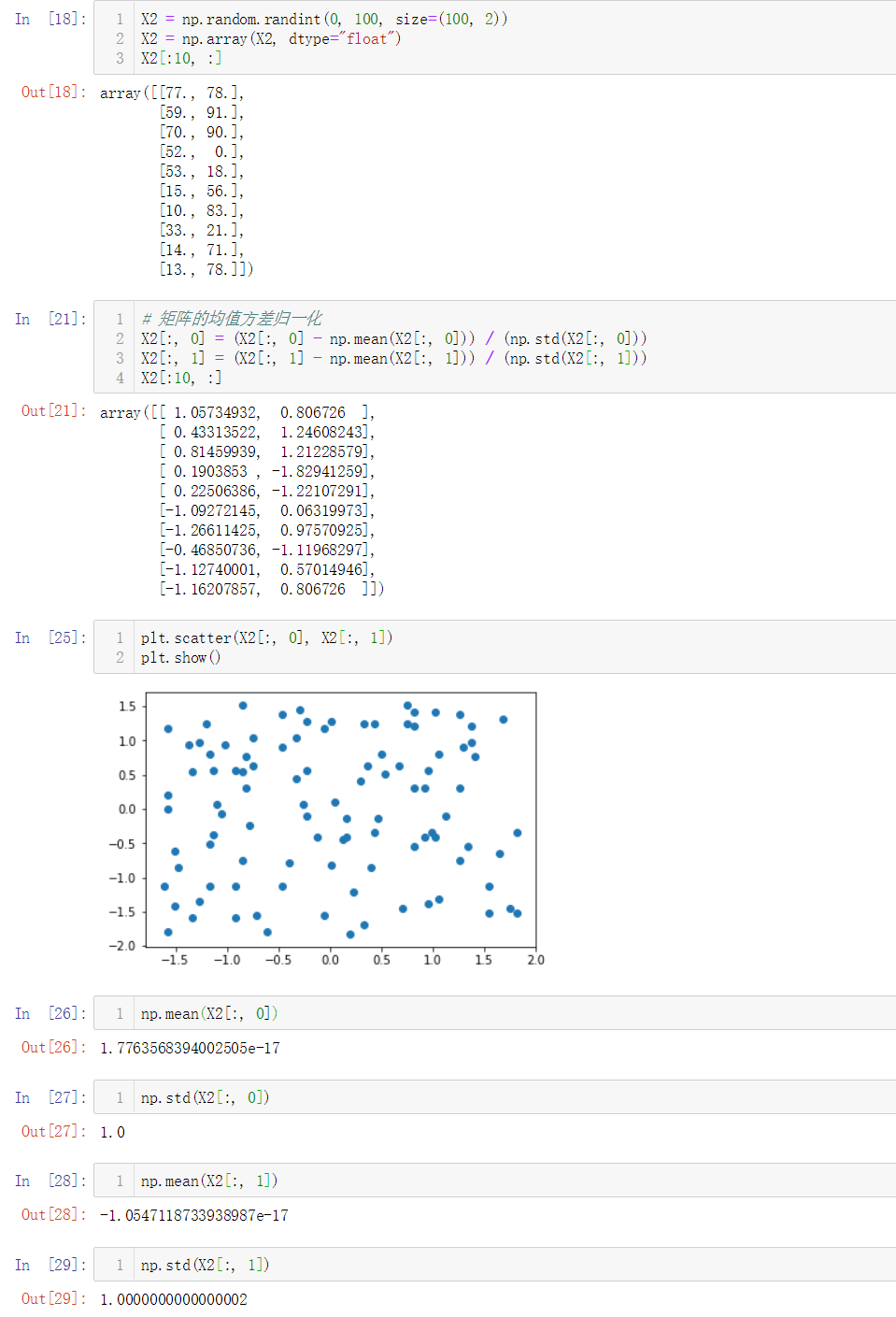
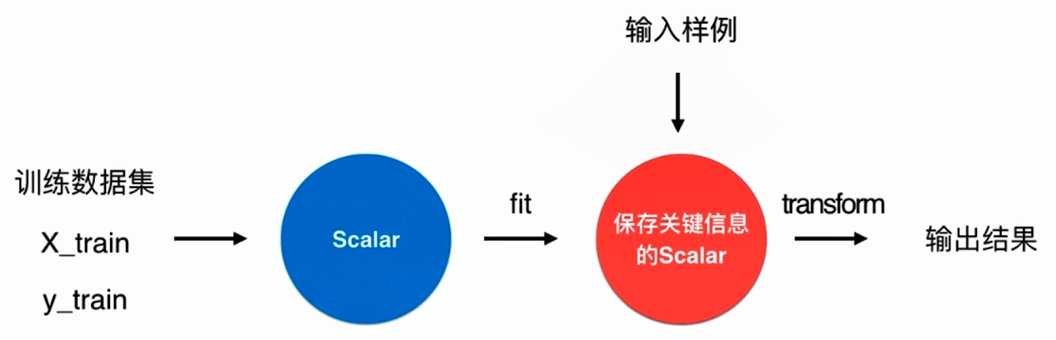
No.6. 使用鸢尾花数据集进行数据归一化
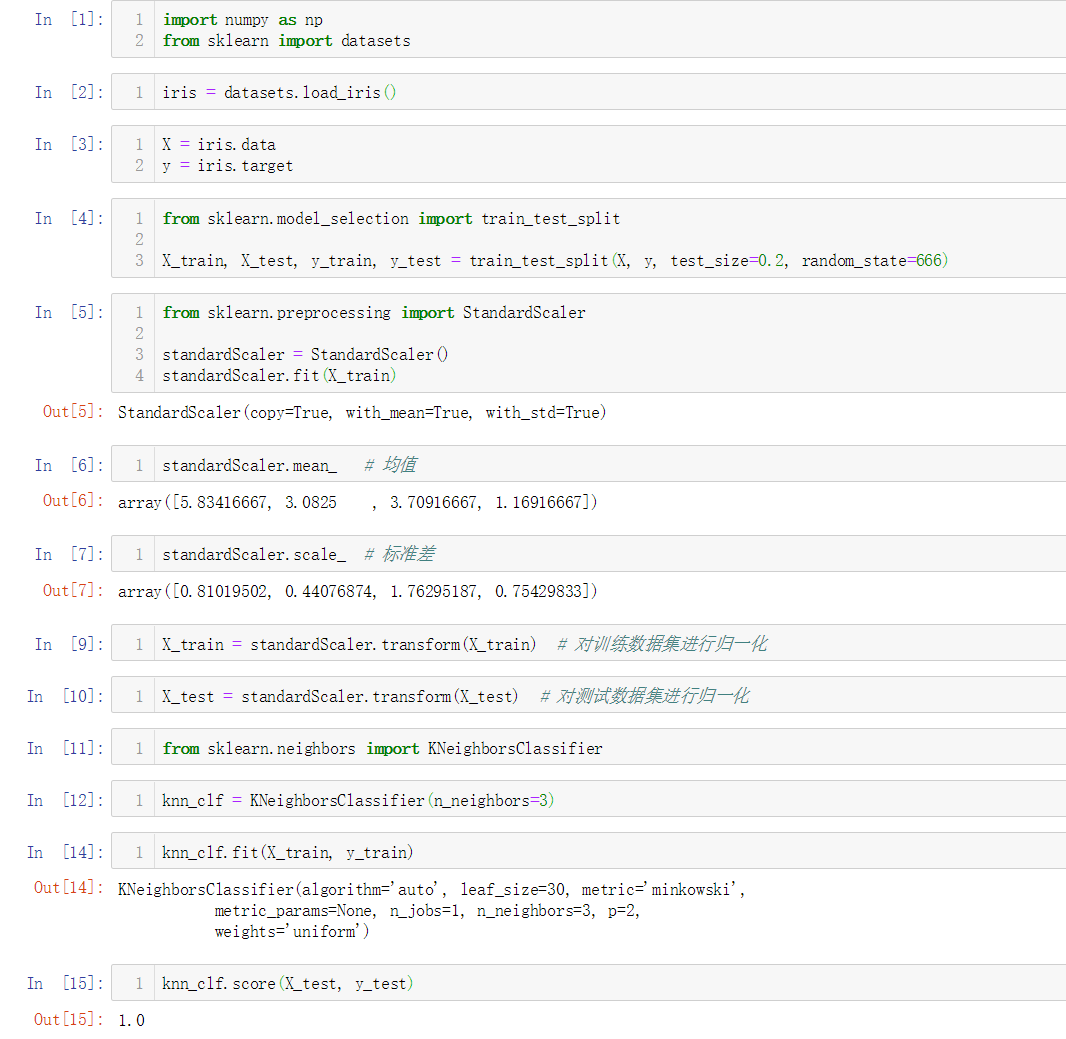
No.7. 简单实现一个自己的StandardScaler类

第四十九篇 入门机器学习——数据归一化(Feature Scaling)的更多相关文章
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 第四十二篇 入门机器学习——Numpy的基本操作——索引相关
No.1. 使用np.argmin和np.argmax来获取向量元素中最小值和最大值的索引 No.2. 使用np.random.shuffle将向量中的元素顺序打乱,操作后,原向量发生改变:使用np. ...
- 第三十九篇 入门机器学习——Numpy.array的基础操作——合并与分割向量和矩阵
No.1. 初始化状态 No.2. 合并多个向量为一个向量 No.3. 合并多个矩阵为一个矩阵 No.4. 借助vstack和hstack实现矩阵与向量的快速合并.或多个矩阵快速合并 No.5. 分割 ...
- 数据归一化Feature Scaling
数据归一化Feature Scaling 当我们有如上样本时,若采用常规算欧拉距离的方法sqrt((5-1)2+(200-100)2), 样本间的距离被‘发现时间’所主导.尽管5是1的5倍,200只是 ...
- Jmeter(四十九) - 从入门到精通高级篇 - jmeter使用监视器结果监控tomcat性能(详解教程)
1.简介 上一篇宏哥讲解了利用jmeter的插件来监控服务器资源,这一篇讲解分享如何使用jmeter的监视器结果监控tomcat性能. 2.准备工作 文章标题中提到jmeter和tomcat,那么只需 ...
- 第三十八篇 入门机器学习——Numpy.array的基本操作——查看向量或矩阵
No.1. 初始化状态 No.2. 通过ndim来查看数组维数,向量是一维数组,矩阵是二维数组 No.3. 通过shape来查看向量中元素的个数或矩阵中的行列数 No.4. 通过size来查看数组中的 ...
- 第四十九篇 -- 添加联系人信息Addcontact
往通讯录里添加联系人 首先,在清单文件里添加读写权限 <uses-permission android:name="android.permission.READ_CONTACTS&q ...
- 第三十六篇 入门机器学习——Jupyter Notebook中的魔法命令
No.1.魔法命令的基本形式是:%命令 No.2.运行脚本文件的命令:%run %run 脚本文件的地址 %run C:\Users\Jie\Desktop\hello.py # 脚本一旦 ...
- 第三十五篇 入门机器学习——Juptyer Notebook中的常用快捷键
1.运行当前Cell:Ctrl + Enter 2.运行当前Cell并在其下方插入一个新的Cell:Alt + Enter 3.运行当前Cell并选中其下方的Cell:Shift + ...
随机推荐
- .NET Core MVC 静态文件应用
一.静态文件应用方面 ASP.NET Core 静态文件应用,主要分为两方面:网站访问和静态文件整合 二.案例 1.访问静态文件 我们都知道,在 ASP.NET 项目中,我们的静态文件一般要放在 ww ...
- redis中key键操作
keys */查看所有的key remoteSelf:1>select 0 "OK" remoteSelf:0>keys * 1) "SUBCRIBEMAP& ...
- Ubuntu安装C#语言开发环境
使用Bash自动化安装 先下载Bash脚本(Linux/macOS),运行脚本 ./dotnet-install.sh -c Current 或者使用包管理器安装 wget -q https://pa ...
- 你为什么不来了解一下Python?
一.什么是Python Python [1](英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum发明. ...
- Kong 系列【六】添加插件---ip-restriction之黑白名单
写在前边 本地postMan请求http://192.168.130.131:8000/test-route,可以正常访问,本地IP:192.168.130.1同样在虚拟机环境192.168.130. ...
- Node中使用MongoDB
简介 MongoDB 中文文档 MongoDB是一个介于关系数据库和非关系数据库(nosql)之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的. Mongoose 在Node中可以使用 Mo ...
- MySQL基础(6) | check约束
MySQL基础(6) | check约束 前言 在一些情况下,我们需要字段在指定范围的输入, 例如:性别只能输入 '男'或者'女',余额只能大于0等条件, 我们除了在程序上控制以外,我们还能使用 CH ...
- 安装vue-devools
https://blog.csdn.net/weixin_38654336/article/details/80790698
- Wannafly Winter Camp 2020 Day 5C Self-Adjusting Segment Tree - 区间dp,线段树
给定 \(m\) 个询问,每个询问是一个区间 \([l,r]\),你需要通过自由地设定每个节点的 \(mid\),设计一种"自适应线段树",使得在这个线段树上跑这 \(m\) 个区 ...
- Redis入门-02-CentOS7环境搭建
CentOS7下redis安装过程,安装后需要开启端口号6379 #下载 wget http://download.redis.io/releases/redis-3.2.4.tar.gz #解压 t ...