基于mnist的P-R曲线(准确率,召回率)
一.准确率,召回率
- TP(True Positive):正确的正例,一个实例是正类并且也被判定成正类
- FN(False Negative):错误的反例,漏报,本为正类但判定为假类
- FP(False Positive):错误的正例,误报,本为假类但判定为正类
- TN(True Negative):正确的反例,一个实例是假类并且也被判定成假类
准确率
所有的预测正确(正类负类)的占总的比重。
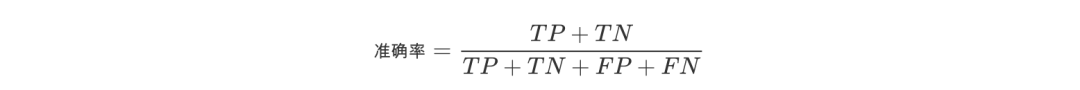
召回率
即正确预测为正的占全部实际为正的比例。
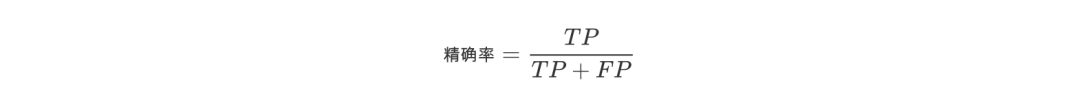
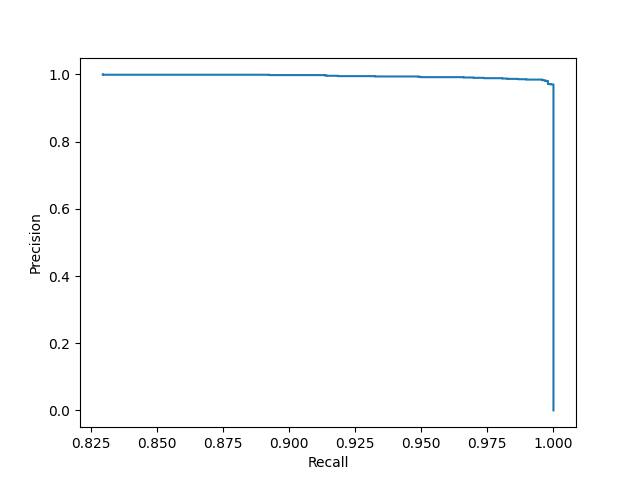
PR-曲线
PR曲线是以召回率作为横坐标轴,精确率作为纵坐标轴,遍历所有的阈值,绘制出的曲线。
二. 代码
1.train
import torch
import torch.nn as nn
import torchvision.transforms
import os device=torch.device('cuda:0')
num_epoch=5
num_classes=2
batch_size=32
learning_rate=0.001
chack_number=8 train_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=True, #train(bool,可选)–如果为True,则从training.pt创建数据集,否则从test.pt创建数据集。
download=True,
transform=torchvision.transforms.ToTensor() #接受PIL图像并返回已转换版本的函数/转换。E、 g,变换。随机裁剪
)
test_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=False,
transform=torchvision.transforms.ToTensor()) #Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=False) class ConvNet(nn.Module):
def __init__(self, num_classes=2):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * 32, num_classes) def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out model=ConvNet(num_classes).to(device) checkpoint_save_path='../mnist_checkpoint_two/model.ckpt'
if os.path.exists(checkpoint_save_path):
print("---------------load the model---------------")
model.load_state_dict(torch.load(checkpoint_save_path)['model_state_dict'])
else :
os.makedirs(os.path.dirname(checkpoint_save_path),exist_ok=True) # Loss and optimizer
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate) #Train and model
total_step=len(train_loader) loss_plt = []
for epoch in range(num_epoch):
for i,(images,labels) in enumerate(train_loader):
images=images.to(device)
labels=labels.to(device)
labels = torch.tensor([1 if i == chack_number else 0 for i in labels]).to(device) #forward
output=model(images)
loss=criterion(output,labels) #backward
optimizer.zero_grad()
loss.backward()
optimizer.step() if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epoch, i+1, total_step, loss.item()))
loss_plt.append(loss.sum().mean().item()) torch.save({'model_state_dict':model.state_dict(),
},
checkpoint_save_path)
2.predict
import torch
import torch.nn as nn
import numpy as np
import torchvision
import matplotlib.pyplot as plt
import os
from sklearn.metrics import precision_recall_curve device=torch.device('cuda:0')
num_epoch=1
num_classes=10
batch_size=1 train_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=True, #train(bool,可选)–如果为True,则从training.pt创建数据集,否则从test.pt创建数据集。
download=True,
transform=torchvision.transforms.ToTensor() #接受PIL图像并返回已转换版本的函数/转换。E、 g,变换。随机裁剪
)
test_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=False,
transform=torchvision.transforms.ToTensor()) #显示图片
# image=test_dataset[0][0].view(28,28)
# plt.gray()
# plt.axis('off')
# plt.imshow(image)
# plt.show()
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False) class ConvNet(nn.Module):
def __init__(self, num_classes=2):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * 32, num_classes) def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out checkpoint_save_path='../mnist_checkpoint_two/model.ckpt'
model=ConvNet()
model=model.to(device)
if os.path.exists(checkpoint_save_path):
print("---------------load the model---------------")
model.load_state_dict(torch.load(checkpoint_save_path)['model_state_dict'])
#pred
model.eval()
with torch.no_grad():
check_number=8
y_pred=[]#预测得分
y_true=[]
for i,(images,labels) in enumerate(test_loader):
images=images.to(device)
labels=labels.to(device)
labels = torch.tensor([1 if i == check_number else 0 for i in labels]).to(device) #将多分类转为2分类
outputs=model(images)
pred=torch.sigmoid(outputs)[0][1]
y_true.append(labels.to('cpu')[0])
y_pred.append(pred.to('cpu'))
# _, pred = torch.max(outputs.data, 1)
# if i ==10000:
# break y_pred=np.array(y_pred)
y_true=np.array(y_true)
precision, recall, thresholds = precision_recall_curve(y_true, y_pred)
#plt画图
plt.ylabel('Recall')
plt.xlabel('Precision')
plt.plot(precision,recall)
plt.show()
3.P-R曲线
基于mnist的P-R曲线(准确率,召回率)的更多相关文章
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- 准确率P 召回率R
Evaluation metricsa binary classifier accuracy,specificity,sensitivety.(整个分类器的准确性,正确率,错误率)表示分类正确:Tru ...
- 机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 : 准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同. 大多时候 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
原文地址:http://blog.csdn.net/pkueecser/article/details/8229166 在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常 ...
- fashion_mnist 计算准确率、召回率、F1值
本文发布于 2020-12-27,很可能已经过时 fashion_mnist 计算准确率.召回率.F1值 1.定义 首先需要明确几个概念: 假设某次预测结果统计为下图: 那么各个指标的计算方法为: A ...
- 机器学习classification_report方法及precision精确率和recall召回率 说明
classification_report简介 sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息. 主要 ...
- ROC 曲线/准确率、覆盖率(召回)、命中率、Specificity(负例的覆盖率)
欢迎关注博主主页,学习python视频资源 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程) https://study.163.com/course/introduction.ht ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
随机推荐
- DBPack 限流熔断功能发布说明
上周我们发布了 v0.4.0 版本,增加了限流熔断功能,现对这两个功能做如下说明. 限流 DBPack 限流熔断功能通过 filter 实现.要设置限流规则,首先要定义 RateLimitFilter ...
- Neo4j在linux上的安装与Springboot的集成
Neo4j在linux上的安装与Springboot的集成 在linux安装: 前提:安装配置好java环境 1.下载neo4j 官方社区版下载地址:https://neo4j.com/downloa ...
- KingbaseES 数据库参数优化
一.数据库应用类型 针对不同的应用模型,需要对数据库配置进行优化: 1.网络应用程序(WEB) 通常受 CPU 限制 DB比RAM小得多 90% 或更多的简单查询 2.在线事务处理 (OLTP) ...
- C/C++内存泄漏检测方法
1. 内存泄漏 内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果. 2. 检测代码 使用链 ...
- jumpserver堡垒机版本升级,从2.14.2升级到2.16.3
官方文档:https://docs.jumpserver.org/zh/master/install/upgrade/upgrade/ 前提说明 1.堡垒机是单节点 2.使用外置MySQL和Redis ...
- Elasticsearch:跨集群复制 Cross-cluster replication(CCR)
- 记一次TIME_WAIT网络故障
文章转载自:https://blog.51cto.com/dngood/988968
- Grafana配置Alert监控告警
1.添加告警途径 这里以slack为例 测试是否可用 在slack上收到告警通知了 安装插件 # grafana-cli plugins install grafana-image-renderer ...
- 3_肯德基餐厅信息查询_动态加载_post请求
肯德基餐厅信息查询网址:http://www.kfc.com.cn/kfccda/storelist/index.aspx import requests url = 'http://www.kfc. ...
- a += 20 和 a = a+20前者不报错,后者报错的原因
我们在使用a += 20 和 a = a+20两种不同方式的赋值运算是发现尽然前者不报错,后者报错 代码示例: shot s = 5; s += 5; s = s+5; 很明显我们可以看出s = s+ ...