Coursera《machine learning》--(14)数据降维
本笔记为Coursera在线课程《Machine Learning》中的数据降维章节的笔记。
十四、降维 (Dimensionality Reduction)
14.1 动机一:数据压缩
本小节主要介绍第二种无监督学习方法:dimensionality reduction,从而实现数据的压缩,这样不仅可以减少数据所占磁盘空间,还可以提高程序的运行速度。如下图所示的例子,假设有一个具有很多维特征的数据集(虽然下图只画出2个特征),可以看到x1以cm为单位,x2以inches为单位,它们都是测量长度的,所以,给出的数据是非常冗余的,应该把这两维数据降到一维(这种情况是常见的,例如,采用两种不同的仪器来测量一些物体的尺寸,其中一个仪器测量结果的单位是英寸,另一个仪器测量的结果是厘米;这种情况在工程中是经常会发生的,有时可能有几个不同的工程团队,第一个工程队给出二百个特征,第二个工程队给出另外三百个的特征,第三个工程队给出五百个特征,这些特征放在一起非常的多,并且可能会出现一些冗余)。
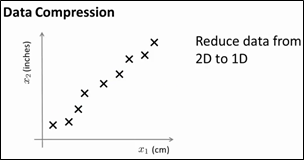
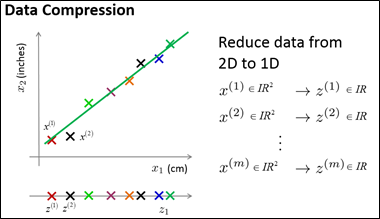
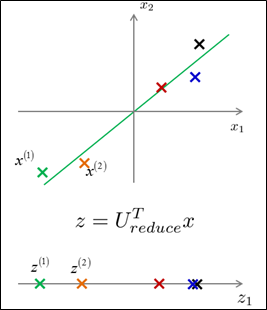
如何将2D数据降到1D?降维,就是希望找到如下图所示的直线,所有的点映射到这条直线上,这个新特征叫做z1,要确定点在这条直线上的位置,只需要一个数字即可。例如,表示原来的样本x(1)需要两个数字或者是一个二维向量,降维后,用z(1)就可以表示这个样本。总结一下,如果可以将原数据集中的所有数据都映射到一条直线上,用映射后的数据来近似原来的数据集,那么,只需要一个实数来确定某个点在直线上的位置。所以,现在只需要为每个样本保留一个数字。
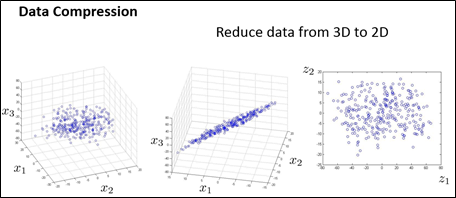
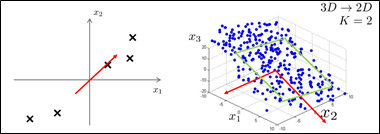
下面,给出一个将数据从三维降至二维的例子,如下图所示(在实际应用中,可能具有10000维的特征,需要降到100维,这里仅以3D降到2D为例),给出了一个数据集,每个样本有三个特征,所有这些数据点可能都能差不多经过一个平面,所以,将所有这些数据点都投影到这个二维平面上,为了表示某个点在平面上的位置,需要两个数,降维后,利用z1、z2表示每个样本。下图中分别给出了3D数据、降维后的2D数据和降维后的2D数据的俯视图。
14.2 动机二:数据可视化
本小节将主要讲解降维的第二种应用,即数据的可视化,许多机器学习算法可以帮助我们开发高效的学习算法,但前提是我们能够更好地理解数据,数据降维是能够将数据可视化的一种有用的工具。假如我们已经搜集了大量的数据,具有许多的特征,如x∈R50,那么,如何能够将这些数据可视化呢?绘制一幅50维的图是不可能的。那么,有没有能够观察数据的好方法呢?可以使用降维方法,例如,可以利用两个数总结50个特征。
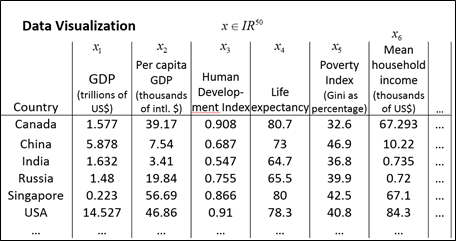
假使我们有关于许多不同国家的数据,每一个特征向量由50个特征构成(如,GDP,人均 GDP,平均寿命等)。如果要将这个50维的数据可视化是不可能的。如果能够使用降维的方法将其降至2维,便可以将其可视化了。这样做的问题在于,降维算法只负责减少维数,而新产生的特征的意义就必须由我们自己去发现了。
14.3 主成分分析问题
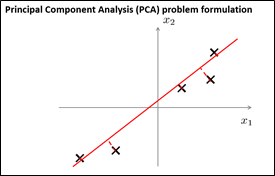
对于降维问题来说,目前最流行、最实用的方法是主成分分析法(Principal Componet Analysis, PAC),本小节主要介绍PCA的公式描述。假设有下图所示的数据集,该数据集中含有二维实数空间内的样本x,现在,需要对数据进行降维,由2D降到1D,想找到一条直线,把所有数据点都投影到该直线上,那么,怎么能够找到这样一条直线呢?如下图所示,其实就是想找到一条直线,使得所有数据点到它们在这条直线上的投影点之间的距离的平方和最小,这些距离被称为投影误差,所以,PCA的目的就是为了寻找到一个投影平面,使得投影误差平方和达到最小。在进行PCA之前,需要先进行数据归一化和特征规范化,使得x1、x2的特征均值为0。仍回到刚刚的问题,现在,如果选择另外一条投影直线,会发现结果非常的差,因为投影误差很大,每个样本都需要移动很大的距离才能被投影到这条投影直线上。这也就是为什么PCA会选择第一条直线作为投影直线。
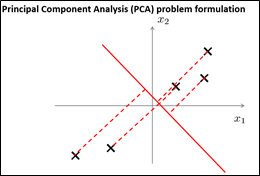
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,使得投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投影误差是从特征向量向该方向向量作垂线的长度,并且,与方向向量的方向无关。主成分分析问题的描述:问题是要将n维数据降至k维,目标是找到向量u(1), u(2),..., u(k)使得总的投影误差最小。

对于3D降到2D的目的就是:找到两个方向向量,它们可以确定一个2D平面,所有3D数据点到该2D平面投影误差平方和最小。
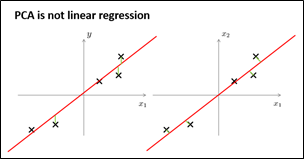
主成分分析与线性回归之间有什么关系呢?主成分分析与线性回归是两种不同的算法,它们只是看起来有点相似。主成分分析最小化的是投影误差(Projected Error),而线性回归尝试的是最小化预测误差。如下图所示,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。线性回归的目的是预测结果,而主成分分析不作任何预测。
PCA是在寻找一个低维的平面,使得数据在其上的投影具有最小化的投影误差平方和。
14.4 主成分分析算法
本小节开始介绍主成分分析算法,即它的实现过程。在进行PCA之前,需要先进行一个数据预处理过程,拿到一组具有m个无标签样本训练集,一般先进行归一化处理,然后,由于不同特征的取值范围不同,需要进行特征缩放。

PCA的主要目的就是求解k个方向向量和所有数据点在投影后的低维面的投影点。
下面给出PCA的步骤:
(1)数据归一化和特征尺度缩放。
我们需要计算出所有特征的均值(即所有样本每一维特征的均值),然后令xj= xj -μj(每一个样本的特征向量-特征均值向量)。如果特征是在不同的数量级上,需要将其除以标准差σ。
(2)计算所有数据点的协方差矩阵Σ(covariance matrix):

(3)计算协方差矩阵Σ的特征向量(eigenvectors):
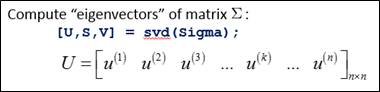
(4)对于一个 n×n维度的矩阵,上式中的矩阵U的各列是使得已知数据具有最小投影误差的方向向量。如果我们希望将数据从n维降至k维,只需要从U中选取前k个向量,获得一个n×k维度的矩阵,用Ureduce 表示,然后通过下式获得要求的新特征向量 z(i):
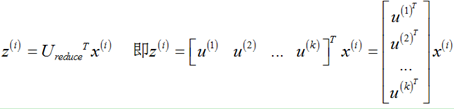
其中x(i)是n×1维的,因此结果z(i)为k×1维度。注: PCA不考虑x0=1。
14.5 选择主成分的数量
在PCA算法中,将n维特征变量变换为k维特征变量,这里的参数k是一个重要的参数,被称为主成分的数量,本小节主要讲述如何选择这个参数k。首先,给出几个概念。
(1)投影误差平方和均值(average squared projection error):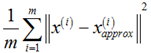 ,其中,
,其中,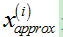 是
是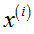 在降维平面上的投影点,
在降维平面上的投影点,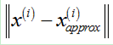 是
是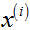 和
和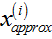 之间的距离;
之间的距离;
(2)数据总变差(Total variation in the data):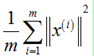 ,即数据集中所有样本长度的平方和的均值,也就是,平均来看,样本距离原点有多远;
,即数据集中所有样本长度的平方和的均值,也就是,平均来看,样本距离原点有多远;
选择k值时,一个经验法则是:选择使以上两个数据(投影误差平方和均值、数据总变差)之间的比例≤0.01的最小k值,所以,在选择k值时,重要的是选择0.01这个数还是其他的数字。如果选择0.01,则表示保留了99%的差异性(这是PCA的语言)。如果选择0.05,则表示保留了95%的差异性;选择0.1,表示保留了90%的差异性,这些都是比较典型的数值。这样,在保证降维的基础上,还能保留大部分的差异性。
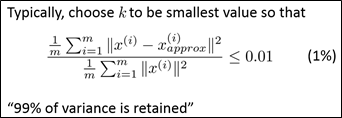
那么,如果实现这个过程呢?首先,令k=1,进行PCA,然后,计算样本投影误差平方和均值与数据总变差之间的比值,如果满足范围要求,则停止,k=1就是比较好的选择,否则,接下来尝试k=2,知道满足要求为止。但这个过程效率比较底下,要一个个去尝试,实际上,在进行PCA时,在对协方差矩阵进行svd时,还会得到一个矩阵S,它是一个维数为n的正方阵,可以证明,给定一个k值,样本投影误差平方和均值与数据总变差之间的比值可以由下式计算得到:
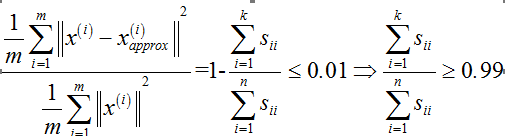
所以,在对k值进行尝试时,只需要计算上式即可,从而逐渐找到能够确保99%差异性被保留的最小k值。这样做,只需要调用一次svd,而不是一遍一遍调用svd。

总结一下,在利用PCA进行数据压缩时,通常使用的方法是:对协方差矩阵进行一次svd,然后找到使得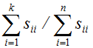 满足要求的最小k值。(在解释PCA获得比较好性能的这个数字时,应该说"有百分之多少的差异性能被保留下来了",表明了这些近似数据对原始数据的近似有多好)
满足要求的最小k值。(在解释PCA获得比较好性能的这个数字时,应该说"有百分之多少的差异性能被保留下来了",表明了这些近似数据对原始数据的近似有多好)

14.6 重建的压缩表示
PCA作为数据压缩算法,它可以把1000维的数据压缩100维特征,或将3D数据压缩到2D。有这样一个数据压缩方法,那么相应地也应该有一个算法可以将压缩过的数据近似地变回到原始的高维度数据。假设有一个已经被压缩过的z(i),它有100个维度,怎样将它变回到原始的1000维的x(i)呢?
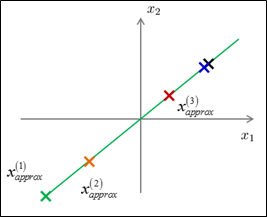
如下左图所示,给定一组2D样本,将它们降维到1D;现在,如果利用这些1D数据恢复出原来的2D数据呢?由于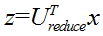 ,那么,可以
,那么,可以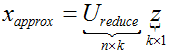 ,根据PCA,投影误差平方和不会很大,所以,
,根据PCA,投影误差平方和不会很大,所以, 会比较接近于x,如下右图所示。
会比较接近于x,如下右图所示。
14.7 主成分分析法的应用建议
如前面所述,PCA可以提高机器学习算法的速度,本小节主要讲述在实际应用中如何实现PCA。如何通过PCA提高学习算法的效率呢?现在有一个监督学习问题,训练样本为输入的x和标签y,如果样本x(i)的维度非常高,例如,x(i)∈IR10,000,在计算机视觉问题中,有一张100×100的图像,如果以所有像素点的强度值作为特征,则会得到一个特征维数为10,000的特征向量,这种维度很高的特征向量,运行速度非常慢,需要进行降维,具体方法如下:
从训练集中提取出x(暂时不考虑y,相当于得到一组无标签的训练集),利用PCA从中得到一组降维的数据,这样,得到一组新的训练集,同时,将原有的标签加入;然后,将已经降维的数据集输入到学习算法中。如果有一个新的样本x,对它的类别进行预测,那么,需要利用PCA对其进行降维,然后利用学习算法得到的分类器对其进行分类。

PCA的主要应用为:数据压缩(Compression)、数据可视化(Visualization)。
下面,介绍PCA常见的错误。有人用它来进行过拟合的控制,这不是一个好的应用,因为,PCA并不需要标签,它把某些特征舍弃掉了。

还有一个关于PCA的误用。例如,在设计机器学习算法时,有人会进行如下操作,在项目的初期使用PCA,但这不是很恰当。在使用PCA之前,应该先用原始数据进行学习,在确定原始数据确实不是很好的时候,再去考虑PCA,而不应该在没有对原始数据进行学习时,就直接使用PCA。

Coursera《machine learning》--(14)数据降维的更多相关文章
- machine learning(14) --Regularization:Regularized linear regression
machine learning(13) --Regularization:Regularized linear regression Gradient descent without regular ...
- Coursera, Machine Learning, notes
Basic theory (i) Supervised learning (parametric/non-parametric algorithms, support vector machine ...
- Coursera, Machine Learning, Anomoly Detection & Recommender system
Algorithm: When to select Anonaly detection or Supervised learning? 总的来说guideline是如果positive e ...
- Coursera machine learning 第二周 quiz 答案 Linear Regression with Multiple Variables
https://www.coursera.org/learn/machine-learning/exam/7pytE/linear-regression-with-multiple-variables ...
- Coursera Machine Learning : Regression 评估性能
评估性能 评估损失 1.Training Error 首先要通过数据来训练模型,选取数据中的一部分作为训练数据. 损失函数可以使用绝对值误差或者平方误差等方法来计算,这里使用平方误差的方法,即: (y ...
- Coursera Machine Learning : Regression 简单回归
简单回归 这里以房价预测作为例子来说明:这里有一批关于房屋销售记录的历史数据,知道房价和房子的大小.接下来就根据房子的大小来预测下房价. 简单线性回归,如下图所示,找到一条线,大体描述了历史数据的走势 ...
- 神经网络作业: NN LEARNING Coursera Machine Learning(Andrew Ng) WEEK 5
在WEEK 5中,作业要求完成通过神经网络(NN)实现多分类的逻辑回归(MULTI-CLASS LOGISTIC REGRESSION)的监督学习(SUOERVISED LEARNING)来识别阿拉伯 ...
- Coursera Machine Learning 学习笔记(十二)
- Normal equation 到眼下为止,线性回归问题中都在使用梯度下降算法,但对于某些线性回归问题,正规方程方法是更好的解决方式. 正规方程就是通过求解例如以下方程来解析的找出使得代价函数最小 ...
- 【Coursera - machine learning】 Linear regression with one variable-quiz
Question 1 Consider the problem of predicting how well a student does in her second year of college/ ...
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
随机推荐
- hdu 4634 Swipe Bo 搜索
典型的bfs模拟 (广度优先搜索) ,不过有好多细节要注意,比如图中如果是 R# 走到这个R的话就无限往右走了,这样就挂了~肯定到不了出口.还有一种容易造成死循环的,比如 #E## DLLL D. ...
- request对象方法详解
自己整理的 javax.servlet.http.HttpServletrequest 所有方法,欢迎收藏! 方法名 说明 isUserInRole 判断认证后的用户是否属于某一成员组 getAttr ...
- ubuntu 14.04 chromium,firefox 怎样正确安装Adobe flash player
一.firefox 正确安装Adobe flash player 有时候我们须要在Ubuntu下採用手动安装一些软件,比方Firefox的Flash插件.Adobe® Flash® Player 是一 ...
- Android 中 更新视图的函数ondraw() 和dispatchdraw()的区别
绘制VIew本身的内容,通过调用View.onDraw(canvas)函数实现 绘制自己的孩子通过dispatchDraw(canvas)实现 View组件的绘制会调用draw(Canvas canv ...
- netsh
NetSH (Network Shell) 是windows系统本身提供的功能强大的网络配置命令行工具. 导出配置脚本:netsh -c interface ip dump > c:\inter ...
- android智能天气闹钟应用开发经过
开发这个应用的初衷是这样产生滴,和我一块租房的同学每天早上都是骑单车上班,所以手机闹钟就会定一个刚好适合骑车的起床时间点.但是呢,有一天早上起床以后发现外面下挺大雨,肯定是不能骑车去上班了,于是就只好 ...
- 也谈android开发图像压缩
long long ago,给学院做的一个通讯录App需要有一个上传图像的功能,冥思苦想,绞尽脑汁后来还是没解决(学生时代的事),于是就直接上传原图了,一张图片2M到3M,这样我的应用发布之后,那绝对 ...
- C语言 打印圣诞树
再回首<C语言编程基础>,其中不少当年老师出的题,做完后稍微做了下修改,可以输入任意行数来打印圣诞树,行数越大,树越大,当然显示器也要越大,不然就折行了. 纯粹练手跟加强记忆的东西,做个记 ...
- Spring Framework jar官方直接下载路径
SPRING官方网站改版后,建议都是通过 Maven和Gradle下载,对不使用Maven和Gradle开发项目的,下载就非常麻烦,下给出Spring Framework jar官方直接下载路径: h ...
- sql存储过程通过ID删除两表中的数据。
CREATE OR REPLACE PROCEDURE del_p --建立名为del_p 的过程 IS CURSOR get_abid --简历名为get_abid的cursor 用来存放a表的id ...