Keras + LSTM 做回归demo
学习神经网络
想拿lstm 做回归, 网上找demo 基本三种: sin拟合cos 那个, 比特币价格预测(我用相同的代码和数据没有跑成功, 我太菜了)和keras 的一个例子
我基于keras 那个实现了一个, 这里贴一下我的代码.
import numpy as np
np.random.seed(1337)
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers import Activation
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import Dense
# 数据的数量
datan = 400
X = np.linspace(-1, 2, datan)
np.random.shuffle(X)
# 构造y y=3*x + 2 并加上一个0-0.5 的随机数
Y = 3.3 * X + 2 + np.random.normal(0, 0.5, (datan, ))
# 展示一下数据
plt.scatter(X, Y)
plt.show()
# 训练集测试集划分 2:1
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=42)
# 一些参数
neurons = 128
activation_function = 'tanh' # 激活函数
loss = 'mse' # 损失函数
optimizer="adam" # 优化函数
dropout = 0.01
model = Sequential() model.add(LSTM(neurons, return_sequences=True, input_shape=(1, 1), activation=activation_function))
model.add(Dropout(dropout))
model.add(LSTM(neurons, return_sequences=True, activation=activation_function))
model.add(Dropout(dropout))
model.add(LSTM(neurons, activation=activation_function))
model.add(Dropout(dropout))
model.add(Dense(output_dim=1, input_dim=1))
#
model.compile(loss=loss, optimizer=optimizer)
# training 训练
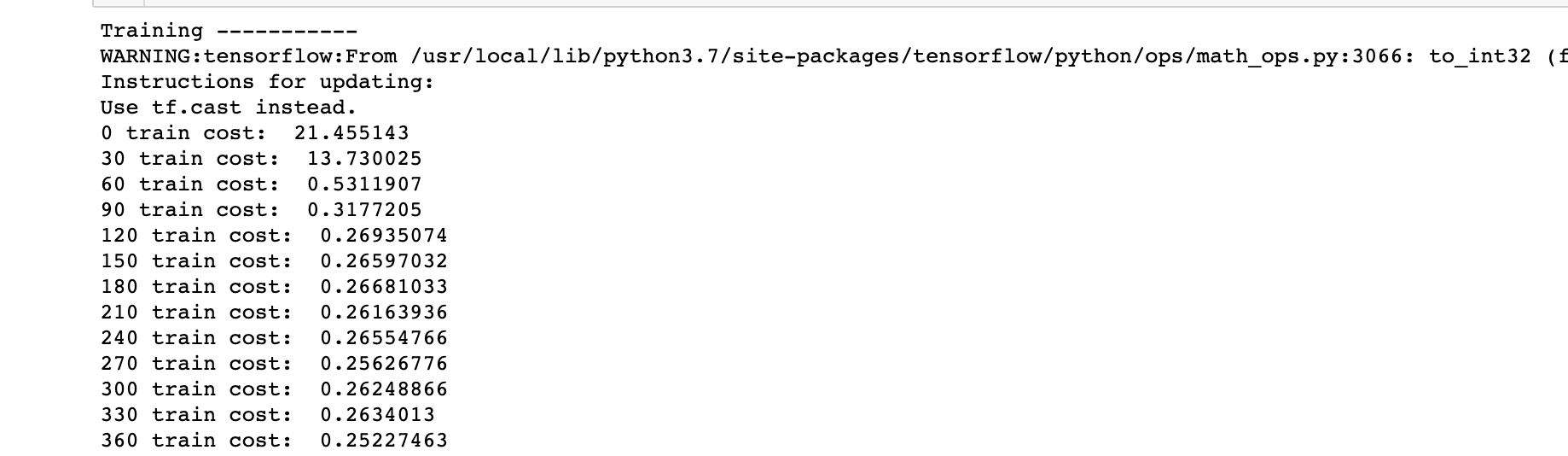
print('Training -----------')
epochs = 2001
for step in range(epochs):
cost = model.train_on_batch(X_train[:, np.newaxis, np.newaxis], Y_train)
if step % 30 == 0:
print(f'{step} train cost: ', cost)
# 测试
print('Testing ------------')
cost = model.evaluate(X_test[:, np.newaxis, np.newaxis], Y_test, batch_size=40)
print('test cost:', cost)

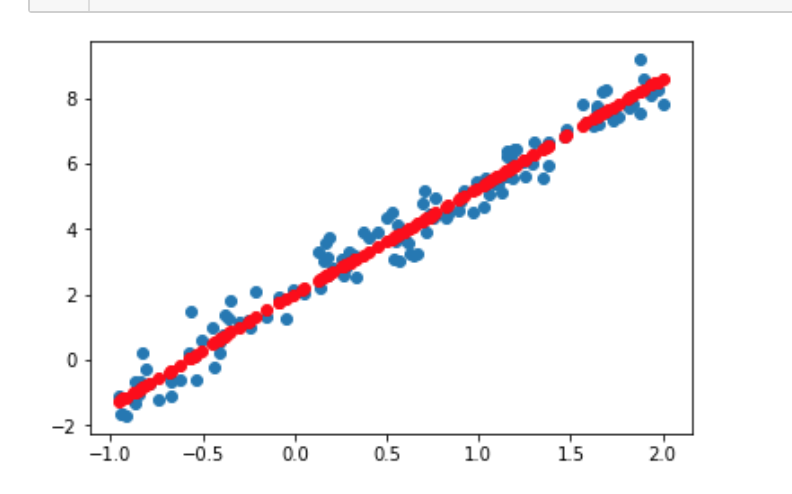
# 打印预测结果
Y_pred = model.predict(X_test[:, np.newaxis, np.newaxis])
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred, 'ro')
plt.show()
loss_history = {}
def run(X_train, Y_train, X_test, Y_test, epochs, activation_func='tanh', loss_func='mse', opt_func='sgd'):
"""
这里是对上面代码的封装, 我测试了一下各种优化函数的效率
可用的目标函数
mean_squared_error或mse
mean_absolute_error或mae
mean_absolute_percentage_error或mape
mean_squared_logarithmic_error或msle
squared_hinge
hinge
categorical_hinge
binary_crossentropy(亦称作对数损失,logloss)
logcosh
categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列
sparse_categorical_crossentrop:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:np.expand_dims(y,-1)
kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.
poisson:即(predictions - targets * log(predictions))的均值
cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
优化函数
sgd
RMSprop
Adagrad
Adadelta
Adam
Adamax
Nadam
"""
mdl = Sequential()
mdl.add(LSTM(neurons, return_sequences=True, input_shape=(1, 1), activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(LSTM(neurons, return_sequences=True, activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(LSTM(neurons, activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(Dense(output_dim=1, input_dim=1))
#
mdl.compile(optimizer=opt_func, loss=loss_func)
#
print('Training -----------')
loss_history[opt_func] = []
for step in range(epochs):
cost = mdl.train_on_batch(X_train[:, np.newaxis, np.newaxis], Y_train)
if step % 30 == 0:
print(f'{step} train cost: ', cost)
loss_history[opt_func].append(cost)
# test
print('Testing ------------')
cost = mdl.evaluate(X_test[:, np.newaxis, np.newaxis], Y_test, batch_size=40)
print('test cost:', cost)
#
Y_pred = mdl.predict(X_test[:, np.newaxis, np.newaxis])
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred, 'ro')
return plt
run(X_train, Y_train, X_test, Y_test, 2000)
run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adagrad')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Nadam')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adadelta')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func='RMSprop')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adam')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func='Adamax') #
arr = [i*30 for i in range(len(loss_history['sgd']))]
plt.plot(arr, loss_history['sgd'], 'b--')
plt.plot(arr, loss_history['RMSprop'], 'r--')
plt.plot(arr, loss_history['Adagrad'], color='orange', linestyle='--')
plt.plot(arr, loss_history['Adadelta'], 'g--')
plt.plot(arr, loss_history['Adam'], color='coral', linestyle='--')
plt.plot(arr, loss_history['Adamax'], color='tomato', linestyle='--')
plt.plot(arr, loss_history['Nadam'], color='darkkhaki', linestyle='--')
plt
最快的是 adadelta, 最慢的sgd. 其他差不多.
Keras + LSTM 做回归demo的更多相关文章
- Keras + LSTM 做回归demo 2
接上回, 这次做了一个多元回归 这里贴一下代码 import numpy as np np.random.seed(1337) from sklearn.model_selection import ...
- 循环神经网络LSTM RNN回归:sin曲线预测
摘要:本篇文章将分享循环神经网络LSTM RNN如何实现回归预测. 本文分享自华为云社区<[Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测 丨[百变AI秀]& ...
- 利用Caffe做回归(regression)
Caffe应该是目前深度学习领域应用最广泛的几大框架之一了,尤其是视觉领域.绝大多数用Caffe的人,应该用的都是基于分类的网络,但有的时候也许会有基于回归的视觉应用的需要,查了一下Caffe官网,还 ...
- [翻译]用神经网络做回归(Using Neural Networks With Regression)
本文英文原文出自这里, 这个博客里面的内容是Java开源, 分布式深度学习项目deeplearning4j的介绍学习文档. 简介: 一般来说, 神经网络常被用来做无监督学习, 分类, 以及回归. 也就 ...
- 单向LSTM笔记, LSTM做minist数据集分类
单向LSTM笔记, LSTM做minist数据集分类 先介绍下torch.nn.LSTM()这个API 1.input_size: 每一个时步(time_step)输入到lstm单元的维度.(实际输入 ...
- 使用LSTM做电影评论负面检测——使用朴素贝叶斯才51%,但是使用LSTM可以达到99%准确度
基本思路: 每个评论取前200个单词.然后生成词汇表,利用词汇index标注评论(对 每条评论的前200个单词编号而已),然后使用LSTM做正负评论检测. 代码解读见[[[评论]]]!embeddin ...
- python 做回归
1 一元线性回归 线性回归是一种简单的模型,但受到广泛应用,比如预测商品价格,成本评估等,都可以用一元线性模型.y = f(x) 叫做一元函数,回归意思就是根据已知数据复原某些值,线性回归(regre ...
- keras神经网络做简单的回归问题
咸鱼了半个多月了,要干点正经事了. 最近在帮老师用神经网络做多变量非线性的回归问题,没有什么心得,但是也要写个博文当个日记. 该回归问题是四个输入,一个输出.自己并不清楚这几个变量有什么关系,因为是跟 ...
- 用 LSTM 做时间序列预测的一个小例子(转自简书)
问题:航班乘客预测 数据:1949 到 1960 一共 12 年,每年 12 个月的数据,一共 144 个数据,单位是 1000 下载地址 目标:预测国际航班未来 1 个月的乘客数 import nu ...
随机推荐
- MATLAB绘制函数图
序言 Matlab可以根据用户给出的数据绘制相应的函数图.对于单个2D函数图,需要给出一个行向量x作为函数图上离散点集的横坐标,以及一个与x列数一样的横坐标y作为函数图上点集的纵坐标. 向量x和y的取 ...
- (转) jmeter 获取cookie
转自 https://blog.csdn.net/five3/article/details/53842283 jmeter是测试过程中会被用到的一个测试工具,我们即可用来进行压力的压测,也可以用 ...
- GAITC 2019全球人工智能技术大会(南京)
2019年5月25日至26日,由中国人工智能学会主办,以“交叉.融合.相生.共赢”为主题的2019GAITC将在南京全新亮相. 2019 全球人工智能技术大会(2019 GAITC)以“前端引领.深度 ...
- python装饰器扩展之functools.wraps
我们知道函数被装饰器,装饰后,所有的属性,以及内置函数就失效了. 原因是函数类型变成了warpper类型 示例1:不带wraps装饰器示例 def warfunc(func): def warpper ...
- C# 合并只要有交集的所有集合
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- vim : 依赖: vim-common (= 2:7.3.429-2ubuntu2) 但是 2:7.3.429-2ubuntu2.1 正要被安装
sudo apt-get purge vim-common sudo apt-get update sudo apt-get upgrade sudo apt-get install vim Just ...
- linux下如何查看某软件是否已安装
因为linux安装软件的方式比较多,所以没有一个通用的办法能查到某些软件是否安装了.总结起来就是这样几类: 1.rpm包安装的,可以用rpm -qa看到,如果要查找某软件包是否安装,用 rpm - ...
- ForkJoinPool
fork():开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理. join():等待该任务的处理线程处理完毕,获得返回值. ForkJoinPool 的每个工作线程都维护着一个工作队 ...
- npm install --save 、--save-dev 、-D、-S 的区别
备注:<=> 意为等价于: 1.npm install <=> npm i --save <=> -S --save-dev <=> -D npm ...
- 8小时入门Git之团队合作学习记录
Git几个重要的区域 工作流程