单向LSTM笔记, LSTM做minist数据集分类
单向LSTM笔记, LSTM做minist数据集分类
先介绍下torch.nn.LSTM()这个API
1.input_size: 每一个时步(time_step)输入到lstm单元的维度.(实际输入的数据size为[batch_size, input_size])
2. hidden_size: 确定了隐含状态hidden_state的维度. 可以简单的看成: 构造了一个权重, 隐含状态
3 . num_layers: 叠加的层数。如图所示num_layers为 3
4. batch_first: 输入数据的size为[batch_size, time_step, input_size]还是[time_step, batch_size, input_size]
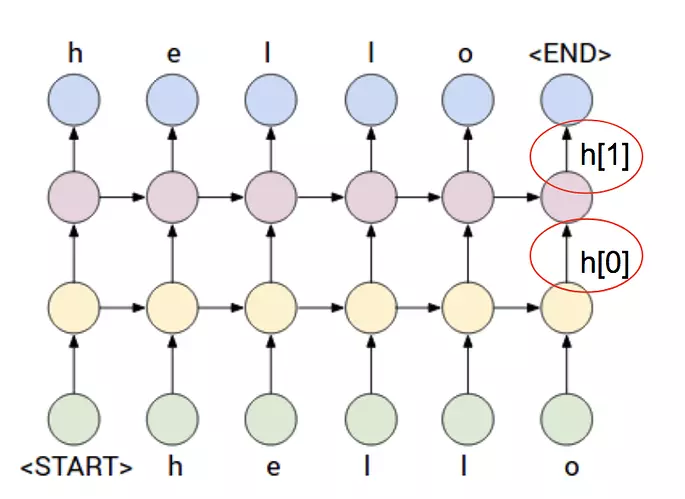
使用单向LSTM对MNIST进行分类,我是在pytorch0.4.1坂本上运行的。
########################## pytorch 用LSTM做minist数据分类 ##################
##########################################################################
import torch
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
import numpy as np BATCH_SIZE = 50 class RNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.rnn = torch.nn.LSTM(
input_size=28,
hidden_size=64,
num_layers=1,
batch_first=True
)
self.out = torch.nn.Linear(in_features=64, out_features=10) def forward(self, x):
# 一下关于shape的注释只针对单向
# output: [batch_size, time_step, hidden_size]
# h_n: [num_layers,batch_size, hidden_size] # 虽然LSTM的batch_first为True,但是h_n/c_n的第一维还是num_layers
# c_n: 同h_n
output, (h_n, c_n) = self.rnn(x)
#print(output.size())
# output_in_last_timestep=output[:,-1,:] # 也是可以的
output_in_last_timestep = h_n[-1, :, :]
# print(output_in_last_timestep.equal(output[:,-1,:])) # ture
x = self.out(output_in_last_timestep)
return x if __name__ == "__main__":
# 1. 加载数据
training_dataset = torchvision.datasets.MNIST("./mnist", train=True,
transform=torchvision.transforms.ToTensor(), download=True)
dataloader = Data.DataLoader(dataset=training_dataset,
batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
# showSample(dataloader)
test_data = torchvision.datasets.MNIST(root="./mnist", train=False,
transform=torchvision.transforms.ToTensor(), download=False)
test_dataloader = Data.DataLoader(
dataset=test_data, batch_size=1000, shuffle=False, num_workers=2)
testdata_iter = iter(test_dataloader)
test_x, test_y = testdata_iter.next()
test_x = test_x.view(-1, 28, 28)
# 2. 网络搭建
net = RNN()
# 3. 训练
# 3. 网络的训练(和之前CNN训练的代码基本一样)
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
loss_F = torch.nn.CrossEntropyLoss()
for epoch in range(3): # 数据集只迭代一次
for step, input_data in enumerate(dataloader):
x, y = input_data
pred = net(x.view(-1, 28, 28))
loss = loss_F(pred,y) # 计算loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 49: # 每50步,计算精度
with torch.no_grad():
test_pred = net(test_x)
prob = torch.nn.functional.softmax(test_pred, dim=1)
pred_cls = torch.argmax(prob, dim=1)
acc = (pred_cls == test_y).sum().numpy() / pred_cls.size()[0]
print(f"{epoch}-{step}: accuracy:{acc}")
由上面代码可以看到输出为:output,(h_n,c_n)=self.rnn(x),解释下代码中的第28行。
output: 如果num_layer为3,则output只记录最后一层 --------- 第三层的输出。
- 对应图中向上的h_t
- 其size根据
batch_first而不同。可能是[batch_size, time_step, hidden_size]或[time_step, batch_size, hidden_size]
h_n: 各个层的最后一个时步的隐含状态
h.- size为
[num_layers,batch_size, hidden_size] - 对应图中向右的h_t. 可以看出对于单层单向的LSTM, 其
h_n最后一层输出h_n[-1,:,:],和output最后一个时步的输出output[:,-1,:]相等。在示例代码中print(h_n[-1,:,:].equal(output[:,-1,:]))会打印True
- size为
c_n: 各个层的最后一个时步的隐含状态
C- c_n可以看成另一个隐含状态,size和
h_n相同
- c_n可以看成另一个隐含状态,size和
我运行了3个epoch效果如下:
0-49: accuracy:0.3
0-99: accuracy:0.596
0-149: accuracy:0.697
0-199: accuracy:0.734
0-249: accuracy:0.769
0-299: accuracy:0.782
0-349: accuracy:0.751
0-399: accuracy:0.843
0-449: accuracy:0.859
0-499: accuracy:0.87
0-549: accuracy:0.857
0-599: accuracy:0.89
0-649: accuracy:0.88
0-699: accuracy:0.883
0-749: accuracy:0.905
0-799: accuracy:0.905
0-849: accuracy:0.902
0-899: accuracy:0.901
0-949: accuracy:0.908
0-999: accuracy:0.921
0-1049: accuracy:0.917
0-1099: accuracy:0.906
0-1149: accuracy:0.941
0-1199: accuracy:0.935
1-49: accuracy:0.935
1-99: accuracy:0.936
1-149: accuracy:0.941
1-199: accuracy:0.923
1-249: accuracy:0.94
1-299: accuracy:0.936
1-349: accuracy:0.941
1-399: accuracy:0.948
1-449: accuracy:0.937
1-499: accuracy:0.939
1-549: accuracy:0.949
1-599: accuracy:0.949
1-649: accuracy:0.953
1-699: accuracy:0.947
1-749: accuracy:0.918
1-799: accuracy:0.944
1-849: accuracy:0.957
1-899: accuracy:0.959
1-949: accuracy:0.947
1-999: accuracy:0.944
1-1049: accuracy:0.961
1-1099: accuracy:0.964
1-1149: accuracy:0.961
1-1199: accuracy:0.952
2-49: accuracy:0.95
2-99: accuracy:0.952
2-149: accuracy:0.957
2-199: accuracy:0.945
2-249: accuracy:0.957
2-299: accuracy:0.953
2-349: accuracy:0.956
2-399: accuracy:0.942
2-449: accuracy:0.946
2-499: accuracy:0.962
2-549: accuracy:0.956
2-599: accuracy:0.957
2-649: accuracy:0.953
2-699: accuracy:0.958
2-749: accuracy:0.963
2-799: accuracy:0.959
2-849: accuracy:0.954
2-899: accuracy:0.961
2-949: accuracy:0.959
2-999: accuracy:0.961
2-1049: accuracy:0.962
2-1099: accuracy:0.958
2-1149: accuracy:0.955
2-1199: accuracy:0.964
主要参考:https://www.jianshu.com/p/043083d114d4
单向LSTM笔记, LSTM做minist数据集分类的更多相关文章
- TensorFlow笔记三:从Minist数据集出发 两种经典训练方法
Minist数据集:MNIST_data 包含四个数据文件 一.方法一:经典方法 tf.matmul(X,w)+b import tensorflow as tf import numpy as np ...
- 做一个logitic分类之鸢尾花数据集的分类
做一个logitic分类之鸢尾花数据集的分类 Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例.数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都 ...
- UFLDL深度学习笔记 (四)用于分类的深度网络
UFLDL深度学习笔记 (四)用于分类的深度网络 1. 主要思路 本文要讨论的"UFLDL 建立分类用深度网络"基本原理基于前2节的softmax回归和 无监督特征学习,区别在于使 ...
- 用CNN及MLP等方法识别minist数据集
用CNN及MLP等方法识别minist数据集 2017年02月13日 21:13:09 hnsywangxin 阅读数:1124更多 个人分类: 深度学习.keras.tensorflow.cnn ...
- Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes
Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = ...
- Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression
Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression 一. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题, ...
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
- 机器学习与Tensorflow(3)—— 机器学习及MNIST数据集分类优化
一.二次代价函数 1. 形式: 其中,C为代价函数,X表示样本,Y表示实际值,a表示输出值,n为样本总数 2. 利用梯度下降法调整权值参数大小,推导过程如下图所示: 根据结果可得,权重w和偏置b的梯度 ...
- BP算法在minist数据集上的简单实现
BP算法在minist上的简单实现 数据:http://yann.lecun.com/exdb/mnist/ 参考:blog,blog2,blog3,tensorflow 推导:http://www. ...
随机推荐
- ubuntu下的“用vim打开中文乱码,用cat打开正常显示”的解决方法
转载 系统环境:ubuntu10.04 vim gvim完全安装 问题:终端下vim中的汉字为乱码,网上搜索了一些解决方案.但是奇怪的是,这些方法都不能实现gvim的菜单和文中汉字,终端vim下的文中 ...
- vue生命周期探究(一)
前言 在使用vue开发的过程中,我们经常会接触到生命周期的问题.那么你知道,一个标准的工程项目中,会有多少个生命周期勾子吗?让我们来一起来盘点一下: 根组件实例:8个 (beforeCreate.cr ...
- Windows 7 64bit VS2015 配置CUDA
1. 更新驱动 下载系统显卡驱动,首先在设备管理器中查看自己的显卡型号,我的是GeForce GTX 960,然后在官网下载对应的驱动程序并安装. 官网网址:NVIDIA 驱动程序下载 2. 安装 ...
- 【bzoj3589】动态树 树链剖分+树链的并
题解: 树链剖分是显然的 问题在于求树链的并 比较简单的方法是 用线段树打标记覆盖,查询标记区间大小 Qlog^2n 代码: #include <bits/stdc++.h> using ...
- pycharm创建python模板文件
1.新建一个项目: 2.右键单击项目名称-->选择新建-->编辑模板文件 3.编辑模板文件保存 4.新建文件测试 至此不再重复添加头部信息了
- Loadrunner和JMeter并发对比
今天在项目中测试发现,其实LR才是实际意义上的并发测试,JMeter不算并发 记录用户登录日志: LR脚本: 1.登录操作放在init初始化中,用5个虚拟用户并发测试:
- Python学习(十九) —— 前端基础之HTML
转载自:http://www.cnblogs.com/liwenzhou/p/7988087.html 一.HTML介绍 1.Web服务本质 import socket sk = socket.soc ...
- VM VirtualBox – Cannot register the hard disk
第一打开VirtualBox 文件夹,在地址栏输入cmd 第二, 仔细读下面 VBoxManage.exe internalcommands sethduuid "F:\Virtual ...
- P1330 封锁阳光大学 DFS
题目描述 曹是一只爱刷街的老曹,暑假期间,他每天都欢快地在阳光大学的校园里刷街.河蟹看到欢快的曹,感到不爽.河蟹决定封锁阳光大学,不让曹刷街. 阳光大学的校园是一张由N个点构成的无向图,N个点之间由M ...
- Linux 文件夹相关常用命令
Linux 文件夹相关常用命令 查看 ls -la -l 列出详细信息 -a 列出全部,包括.和.. 删除 rm <folder> -rf -r 就是向下递归,不管有多少级目录,一并删 ...