使用TensorFlow实现分类
这一节使用TF搭建一个简单的神经网络用于分类任务,首先把需要的包引入,另外为了防止在多次运行中一些图中的tensor在内存中影响实验,采取重置操作:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
reset_graph()
plt.figure(1,figsize=(8,6))
为了方便观察随机生成一组两维数据
x0 = np.random.normal(1,1,size=(100,2)) #[(x1,x2),()]
y0 = np.zeros(100)
x1 = np.random.normal(-1,1,size=(100,2))
y1 = np.ones(100)
x = np.concatenate((x0,x1),axis = 0)
y = np.concatenate((y0,y1),axis = 0)
plt.scatter(x[:,0],x[:,1],c=y,cmap='RdYlGn')
plt.show()
上面生成的两个类别的数据,均值分别为1和-1方差都为1

接下来就是训练模型
#模型
tf_x = tf.placeholder(tf.float32,x.shape)
tf_y = tf.placeholder(tf.int32,y.shape)
output = tf.layers.dense(tf_x,10,tf.nn.relu,name="hidden")
output = tf.layers.dense(output,2,name="output")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf_y,logits=output)
loss = tf.reduce_mean(xentropy,name="loss")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
training_op = optimizer.minimize(loss)
#evaluate
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(output,y,1)
accuracy = tf.reduce_mean(tf.cast(correct,tf.float32))
init = tf.global_variables_initializer()
plt.ion()
plt.figure(figsize=(8,6))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
for step in range(100):
_,acc,pred = sess.run([training_op,accuracy,output],feed_dict={tf_x:x,tf_y:y})
plt.cla()
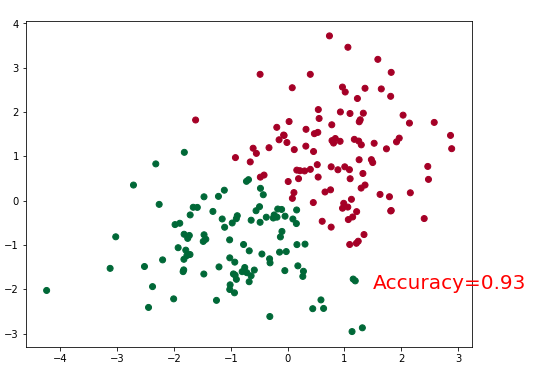
plt.scatter(x[:,0],x[:,1],c=pred.argmax(1),cmap='RdYlGn')
plt.text(1.5, -2, 'Accuracy=%.2f' % acc, fontdict={'size': 20, 'color': 'red'})
saver.save(sess, './model', write_meta_graph=False) #保存模型
plt.ioff()
plt.show()
上面创建了一个隐含层的网络,使用的是elu,也可以尝试使用其他的激活函数。需要注意的是tf.layers.dense的作用是outputs = activation(inputs.kernel + bias),可以看出在输出层是没有使用激活函数的,如果activation=None就表示使用的是线性映射。模型训练完毕后,我们将其持久化,方便以后的使用。我们来看下最终的结果:
使用TensorFlow实现分类的更多相关文章
- Tensorflow二分类处理dense或者sparse(文本分类)的输入数据
这里做了一些小的修改,感谢谷歌rd的帮助,使得能够统一处理dense的数据,或者类似文本分类这样sparse的输入数据.后续会做进一步学习优化,比如如何多线程处理. 具体如何处理sparse 主要是使 ...
- 『TensorFlow』分类问题与两种交叉熵
关于categorical cross entropy 和 binary cross entropy的比较,差异一般体现在不同的分类(二分类.多分类等)任务目标,可以参考文章keras中两种交叉熵损失 ...
- tensorflow之分类学习
写在前面的话 MNIST教程是tensorflow中文社区的第一课,例程即训练一个 手写数字识别 模型:http://www.tensorfly.cn/tfdoc/tutorials/mnist_be ...
- 机器学习框架ML.NET学习笔记【6】TensorFlow图片分类
一.概述 通过之前两篇文章的学习,我们应该已经了解了多元分类的工作原理,图片的分类其流程和之前完全一致,其中最核心的问题就是特征的提取,只要完成特征提取,分类算法就很好处理了,具体流程如下: 之前介绍 ...
- tensorflow文本分类实战——卷积神经网络CNN
首先说明使用的工具和环境:python3.6.8 tensorflow1.14.0 centos7.0(最好用Ubuntu) 关于环境的搭建只做简单说明,我这边是使用pip搭建了python的 ...
- TensorFlow 实现分类操作的函数学习
函数:tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None) 说明:此函数是计算logits经过sigmod函数后的交叉 ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(2)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- adb报错问题解决方法
1,报错信息:adb server version (31) doesn't match this client (40); killing 解决方法: 一: 主要是前面的31或者其他,比如32/31 ...
- Linux系统学习之网络管理
网络接口配置 使用ifconfig检查和配置网卡 lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ...
- JavaScript高级程序设计学习(一)之介绍
作为一名web开发人员,日常用的最多的就是js,也就是大名鼎鼎的ECMAScript,又称javascript.再次声明js与java除了语法上相似,没有半毛钱关系.据说之所以叫javascript, ...
- Python将数据渲染到docx文档指定位置
超简单Python将指定数据插入到docx模板渲染并生成 最近有一个需求,制作劳动合同表,要从excel表格中将每个人的数据导入到docx劳动合同中,重复量很大,因此可以使用python高效解决.为了 ...
- highcharts为X轴标签添加链接
$(function () { var categoryLinks = { 'Foo': 'http://www.google.com/search?q=foo', 'Bar': 'http://ww ...
- 每个大主播都是满屏弹幕,怎么做到的?Python实战无限刷弹幕!
anmu 是一个开源的直播平台弹幕接口,使用他没什么基础的你也可以轻松的操作各平台弹幕.使用不到三十行代码,你就可以使用Python基于弹幕进一步开发.支持斗鱼.熊猫.战旗.全民.Bilibili多平 ...
- ASP.NET Core StaticFiles中间件修改wwwroot(转载)
ASP.NET Core 开发,中间件(StaticFiles)的使用,我们开发一款简易的静态文件服务器.告别需要使用文件,又需要安装一个web服务器.现在随时随地打开程序即可使用,跨平台,方便快捷. ...
- Codeforces round 1098
Div1 530 感受到被Div1支配的恐惧了.jpg 真·一个题都不会.jpg(虽然T1是我智障 感受到被构造题支配的恐惧了.jpg A 直接树上贪心就行,是我写错了.jpg B 这个构造超级神仙有 ...
- 【LeetCode232】 Implement Queue using Stacks★
1.题目描述 2.思路 思路简单,这里用一个图来举例说明: 3.java代码 public class MyQueue { Stack<Integer> stack1=new Stack& ...
- 学习Key与Value的集合hashtable
你可以创建一个hashtable: 你可以使用foreach方法,把hashtable的key与value循环写出来: 在控制台屏幕输出: 如果只需把key输出: 如果只想把值循环输出: 测试输出结果 ...