python模块之HTMLParser简介
html.parser是一个非常简单和实用的库,它的核心是HTMLParser类。
工作的流程是:当你feed给它一个类似HTML格式的字符串时,它会调用goahead方法向前迭代各个标签,并调用对应的parse_xxxx方法提取start_tag, tag, attrs data comment和end_tag等等标签信息和数据,然后调用对应的方法对这些抽取出来的内容进行处理。整个HTMLParser的大致结构如下图所示:
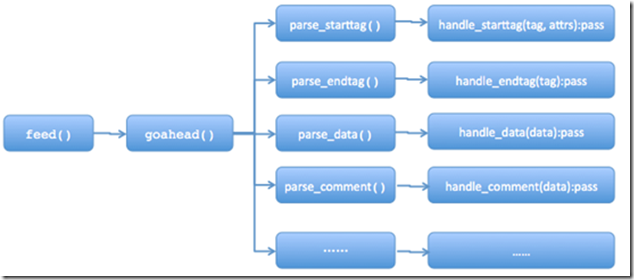
可以发现,处理开始标签(handle_starttag)、结束标签(handle_endtag)和处理数据(handle_data)等处理函数在HTMLParser里是没有实现的(pass),这需要我们继承HTMLParser这个类的并覆盖这些方法。详细可以参阅python文档,https://docs.python.org/3/library/html.parser.html?highlight=htmlparser
一、常用方法介绍
l feed(data):主要用于接受带html标签的str,当调用这个方法时并提供相应的data时,整个实例(instance)开始执行,结束执行close()。
l handle_starttag(tag, attrs): 这个方法接收Parse_starttag返回的tag和attrs,并进行处理,处理方式通常由使用者进行覆盖,本身为空。
例如,连接的start tag是<a>,那么对应的参数tag=’a’(小写)。attrs是start tag <>中的属性,以元组形式(name, value)返回(所有这些内容都是小写)。
例如,对于<A HREF="http://www.baidu.com“>,那么内部调用形式为:handle_starttag(’a’,[(‘href’,’http://www.baidu.com)]).
l handle_endtag(tag):跟上述一样,只是处理的是结束标签,也就是以</开头的标签。
l handle_data(data):处理的是网页的数据,也就是开始标签和结束标签之间的内容。例如:<script>...</script>的省略号内容
l handle_comment(data) ,处理注释,<!-- -->之间的文本
l reset():将实例重置,包括作为参数输入的数据进行清空。
二、基本使用
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
"""
recognize start tag, like <div>
:param tag:
:param attrs:
:return:
"""
print("Encountered a start tag:", tag)
def handle_endtag(self, tag):
"""
recognize end tag, like </div>
:param tag:
:return:
"""
print("Encountered an end tag :", tag)
def handle_data(self, data):
"""
recognize data, html content string
:param data:
:return:
"""
print("Encountered some data :", data)
def handle_startendtag(self, tag, attrs):
"""
recognize tag that without endtag, like <img />
:param tag:
:param attrs:
:return:
"""
print("Encountered startendtag :", tag)
def handle_comment(self,data):
"""
:param data:
:return:
"""
print("Encountered comment :", data)
parser = MyHTMLParser()
parser.feed('<html><head><title>Test</title></head>'
'<body><h1>Parse me!</h1><img src = "" />'
'<!-- comment --></body></html>')
以上是根据python手册写的基本使用,解析了一个简单的html。可以运行看看,主要用于了解各个函数负责解析的部分,以及解析顺序
Encountered a start tag: html
Encountered a start tag: head
Encountered a start tag: title
Encountered some data : Test
Encountered an end tag : title
Encountered an end tag : head
Encountered a start tag: body
Encountered a start tag: h1
Encountered some data : Parse me!
Encountered an end tag : h1
Encountered startendtag : img
Encountered comment : comment
Encountered an end tag : body
Encountered an end tag : html
三、实用案例
以下的实用案例均在上面的代码中修改对应函数,每个实例都是单独的。
解析的html如下
<html>
<head>
<title>Test</title>
</head>
<body>
<h1>Parse me!</h1>
<img src = "" />
<p class='123'>A paragraph.</p>
<p class = "p_font">A paragraph with class.</p>
<!-- comment -->
<div>
<p>A paragraph in div.</p>
</div>
</body>
</html>
1.获取所有p标签的文本,最简单方法只修改handle_data
def handle_data(self, data):
if self.lasttag == 'p':
print("Encountered p data :", data)
2.获取css样式(class)为p_font的p标签的文本,使用了案例1,增加一个实例属性作为标志,选取需要的标签
def __init__(self):
HTMLParser.__init__(self)
self.flag = False def handle_starttag(self, tag, attrs):
for attr in attrs:
if tag == 'p' and attr[1]=='"p_font":
self.flag = True def handle_data(self, data):
if self.flag == True:
print("Encountered p data :", data)
3.获取p标签的属性列表
def handle_starttag(self, tag, attrs):
if tag == 'p':
print("Encountered p attrs :", attrs)
4.获取p标签的class属性
def handle_starttag(self, tag, attrs):
for attr in attrs:
If tag == 'p' and attr[0]= 'class'):
print("Encountered p class :", attr[1])
5.获取div下的p标签的文本
def __init__(self):
HTMLParser.__init__(self)
self.in_div = False def handle_starttag(self, tag, attrs):
if tag == 'div':
self.in_div = True def handle_data(self, data):
if self.in_div == True and self.lasttag == 'p':
print("Encountered p data :", data)
self.in_div = False
6.处理注释中的标签,若需要的数据在注释中,使用一般函数解析不到
处理方法为,写两个类,继承HTMLParser。在其中一个类的handle_comment里实例化解析类,和其他标签一样解析
def __init__(self):
HTMLParser.__init__(self) def handle_comment(self,data):
print(("Encountered comment:",data)
完整实例
例如:我们有以下一堆带HTML标签的数据
html = '''<h3 class="tb-main-title" data-title="Xiaomi/小米">
【金冠现货/全色/顶配版】Xiaomi/小米 小米note移动联通4G手机
</h3>
<p class="tb-subtitle">
【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】
</p>
<div id="J_TEditItem" class="tb-editor-menu"></div>
</div>
<h3 class="tb-main-title" data-title="MIUI/小米">
【现货增强/标准】MIUI/小米 红米手机2红米2移动联通电信4G双卡
</h3>
<p class="tb-subtitle">
[红米手机2代颜色版本较多,请亲们阅读购买说明按需选购---感谢光临]
<div id="J_TEditItem" class="tb-editor-menu"></div>
</div>'''
很明显,这里面包含了两台手机,我们的目标是提取两个手机的名字出来。
由于当我们feed这个html到HTMLParser中后,他们所有的标签都迭代,如果需要它只提取我们需要的数据时,我们需要设置当handle_starttag遇到那个标签和属性时,才调用handle_data并print出我们的结果,这个时候我们可以使用一个flag作为判定,代码如下:
#定义一个MyParser继承自HTMLParser
class MyParser(HTMLParser):
re=[]#放置结果
flag=0#标志,用以标记是否找到我们需要的标签
def handle_starttag(self, tag, attrs):
if tag=='p':#目标标签
for attr in attrs:
if attr[0]=='class' and attr[1]=='tb-subtitle':#目标标签具有的属性
self.flag=1#符合条件则将标志设置为1
break
else:
pass def handle_data(self, data):
if self.flag==1:
self.re.append(data.strip())#如果标志为我们设置的,则将数据添加到列表中
self.flag=0#重置标志,进行下次迭代
else:
pass my=MyParser()
my.feed(html)
my.re
运行结果如下,达到了我们的预期:
['【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】',
'[红米手机2代颜色版本较多,请亲们阅读购买说明按需选购---感谢光临]']
python模块之HTMLParser简介的更多相关文章
- python模块介绍- HTMLParser 简单的HTML和XHTML解析器
python模块介绍- HTMLParser 简单的HTML和XHTML解析器 2013-09-11 磁针石 #承接软件自动化实施与培训等gtalk:ouyangchongwu#gmail.comqq ...
- python模块之HTMLParser(原理很大程度上就是对类构造的熟练运用)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之HTMLParser(原理很大程度上就是对类构造的熟练运用) import HTMLPar ...
- python模块之HTMLParser之穆雪峰的案例(理解其用法原理)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之HTMLParser之穆雪峰的案例(理解其用法原理) #http://www.cnblog ...
- python模块之HTMLParser抓页面上的所有URL链接
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之HTMLParser抓页面上的所有URL链接 import urllib #MyParse ...
- python模块之HTMLParser解析出URL链接
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之HTMLParser解析出URL链接 #http://www.cnblogs.com/mf ...
- python模块之HTMLParser
HTMLParser是python用来解析html的模块.它可以分析出html里面的标签.数据等等,是一种处理html的简便途径. HTMLParser采用的是一种事件驱动的模式,当HTMLParse ...
- python模块学习---HTMLParser(解析HTML文档元素)
HTMLParser是Python自带的模块,使用简单,能够很容易的实现HTML文件的分析. 本文主要简单讲一下HTMLParser的用法. 使用时需要定义一个从类HTMLParser继承的类,重定义 ...
- python模块——PrettyTable
python模块——PrettyTable 一. 简介 Python通过prettytable模块将输出内容如表格方式整齐输出,可用来生成美观的ASCII格式的表格,十分实用. python本身并不内 ...
- 6.文件所有权和权限----免费设置匿名----Windows键盘记录器----简介和python模块
文件所有权和权限 touch --help cd Desktop mkdir Folder cd Folder clear touch Test1 Test2 Test3 Test4 ls ls -l ...
随机推荐
- Codeforces 1136F Cooperative Game (神仙题)
这种题就是难者不会,会者不难. 博客讲的很详细了 代码: #include <bits/stdc++.h> using namespace std; string s; int read( ...
- C++面向对象类的实例题目八
题目描述: 编写一个程序输入3个学生的英语和计算机成绩,并按照总分从高到低排序.要求设计一个学生类Student,其定义如下: 程序代码: #include<iostream> using ...
- Maven 导包后,在Maven Dependencies 里面却没有相应的包
1 问题描述 在1处显示成功,但是在2处却没有相应的包 2 问题原因 查看pom.xml的源码,看你的依赖是否和我的方框中标签是一样的,有的会多出一个 xxxupdate 的标签(我这里给出的是正确 ...
- C#多线程的简单例子
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- Python--面向对象编程--时钟实例开发
在学习python面向对象编程的时候,心血来潮,决定写一个时钟模型来玩玩,所以就有了现在这个小玩意,不过python这个东西确实是挺好玩的 方法:运用python的tkinter库开发图形化时钟程序 ...
- enumerate()函数
for index,value in enumerate(list): print index,value 等于for i in range(0,len(list)): print i,l ...
- AR# 30522:LogiCORE RapidIO - How do system_reset and link_reset work?
Description How do system_reset and link_rest work? Solution lnk_linkreset_n (input): In Xilinx SRIO ...
- JavaScript prototype原型链介绍
javascript 是一种基于原型的编程 (prototype based programming) 的语言, 而与我们通常的基于类编程 (class based programming) 有很大的 ...
- easyui 展开缩起
1.引用jquery-easyui-1.4.4/datagrid-detailview 2.增加属性 view: detailview, detailFormatter: function (rowI ...
- POST工具
#!/usr/bin/env python# Filename: post.py import sysdef send(host,port,request): import socket s = so ...