python学习:python文件中空格和换行符的捕获和文本文件的转存
0. 背景
之前公司的项目中,需要在嵌入式系统中实现一个http的网页端内容,由于项目历史遗留问题,公司是采用的将html文件转成c语言头文件的方式,每次修改页面端都需要从新编译一下程序,非常的繁琐。
虽然繁琐,但是因为历史遗留问题,历史遗留项目都采用这种方式做后面的升级维护。
入乡随俗嘛,用python写了一个html和h文件互转的小程序,程序编写的过程和原理很简单,以后有时间再另外发帖。(TODO)在此不做深入讨论。
程序也很好用,但是最近将公司自己写的程序使用gitblit本地仓库的形式进行版本管理后,发现一个致命的问题。就是每次转换成的h文件和公司历史遗留的文件进行git diff 时候,满屏都是不一样的地方。这咋利于版本控制和验证呢?
1. 问题分析
究竟是哪里不同呢?后来发现原来我写的转换脚本,和公司惯用的html to c脚本有着严重不同的地方在于:
公司旧版本程序是:
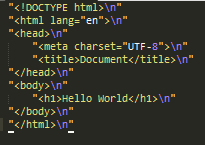
我转换的程序是:

git diff 比对文件的时候是会比对空格的,而且是引号的位置不同,所以就是大段的内容是不一样的。
这怎么办呢?
这时候正则匹配就派上用场了。
2. 寻找方法
上述问题其实总结起来就是:“引号位置放错了”。那么怎么知道应该在哪里放置引号呢?博主想到的笨办法就是在把每行的内容单独拎出来,然后分成三个部分,空格+内容+空格的方式,然后在组合成 空格+引号 +内容+引号+空格的方式。然后实际上就是提取出来了内容两边的东西。
talk is cheap , show codes.
假设我们有一个 test.html 文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<h1>Hello World</h1>
</body>
</html>
我们读取它的时候,要注意,每行实际在末尾有一个换行符\n
现在我们编写一个 r.py 脚本
import re
with open('test.html') as f:
lines = f.readlines() # 获取行列表信息
print(lines) # 打印行信息
我们在ipython中执行是这样的:
In []: %run r.py
['<!DOCTYPE html>\n', '<html lang="en">\n', '<head>\n', '\t<meta charset="UTF-8"
>\n', '\t<title>Document</title>\n', '</head>\n', '<body>\n', '\t<h1>Hello Wor
ld</h1>\n', '</body>\n', '</html>']
2,3,4 表示的是每行的信息,和我们上面的 test.html 文件是一致的。
将上面的列表整理一下:
# 整理列表
[
'<!DOCTYPE html>\n',
'<html lang="en">\n',
'<head>\n',
'\t<meta charset="UTF-8">\n',
'\t<title>Document</title>\n',
'</head>\n', '<body>\n',
'\t<h1>Hello World</h1>\n',
'</body>\n', '</html>'
]
可以看出,我们就是逐行打印了文件内容而已:
拿第6行举例,我们需要匹配到\t 和 \n 并在合适的地方加上引号,程序就over了。
查阅正则内容(菜鸟教程Python正则表达式章节),可知道 \s 可以匹配任意空白字符。

于是,我们用行6字符串测试一下我们的处理代码对不对:
In []: s = re.search(r'^(\s*)(.*)(\s*)$','\t"<title>Document</title>"\n') In []: s.group()
Out[]: '\t"<title>Document</title>"\n' In []: s.group()
Out[]: '\t"<title>Document</title>"\n' In []: s.group()
Out[]: '\t' In []: s.group()
Out[]: '"<title>Document</title>"' In []: s.group()
Out[]: '\n'
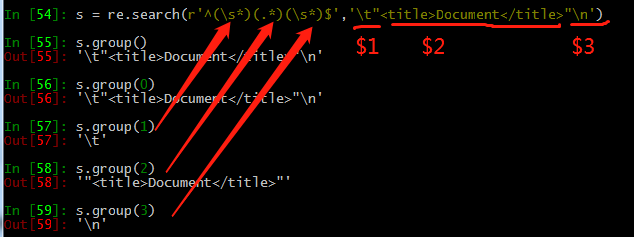
测试和之前的想法是一致的。括弧括起来的内容被捕获出来。
3. 解决问题
由此,上述问题基本已经找到解决的头绪,那么定下代码编写的流程:
- 读取读文件
- 行列表信息行处理
- 读取写文件
- 写入处理后的行列表信息
于是编写代码:
import re # 引入正则库
with open('test.html') as f: # 读取读文件
lines = f.readlines() # 读取行信息
r = r'^(\s*)(.*)(\s*)$' # 正则
lines = [re.search(r,l).group() +'"'+ re.search(r,l).group()+'\\n"'+re.search(r,l).group() for l in lines] # 处理行信息
with open('test.h','w+') as f2: # 读取写文件
f2.writelines(lines) # 写入行信息
其中第4行就是我们处理行信息的过程,这里用了一个列表推导式
所谓列表推导式,就是一种for循环的简写形式,可以从一个列表,经过一定的变换,快速生成一个列表。例如:
In[] : a = [,,,]
In[] : print(a)
Out[] : [,,,] In[] : print([i for i in a])
Out[] : [,,,] In[] : print([i*+ for i in a])
Out[] : [,,,]
也就是,前面第4行的程序实际上就是将lines的数据单个处理,在捕获内容中加入一些我们需要的字符,比如是双引号,然后组成了新的列表。写入到文件中。
问题解决。
4. 总结
这个测试脚本的重点就在于正则的捕获,正则捕获在文本文件、字符串处理中使用广泛,需要不断积累和总结,方能领悟其中的妙用。
python学习:python文件中空格和换行符的捕获和文本文件的转存的更多相关文章
- sqlserver数据库 去除字段中空格,换行符,回车符(使用replace语句)
SQL中可以使用Replace函数来对某个字段里的某些字符进行替换操作,语法如下: 语法 REPLACE ( original-string, search-string, replace-strin ...
- linux下使用vim替换文件中的^M换行符
在linux下打开windows编辑过的文本,会出现由于换行符不一致而导致的内容格式错乱的问题.最常见的就是出现^M . 我出现的问题是:在windows编辑过的文件,传到linux上后再用vim打开 ...
- python操作txt文件中数据教程[4]-python去掉txt文件行尾换行
python操作txt文件中数据教程[4]-python去掉txt文件行尾换行 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文章 python操作txt文件中数据教程[1]-使用pyt ...
- python操作txt文件中数据教程[1]-使用python读写txt文件
python操作txt文件中数据教程[1]-使用python读写txt文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果 程序实现 filename = '. ...
- python学习9—文件基本操作与高级操作
python学习9—文件基本操作与高级操作 1. 文件基本操作 打开文件,获得文件句柄:f = open('filename',encoding='utf-8'),open会查询操作系统的编码方式,并 ...
- python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 python操作txt文件中 ...
- python操作txt文件中数据教程[2]-python提取txt文件
python操作txt文件中数据教程[2]-python提取txt文件中的行列元素 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果-将txt中元素提取并保存在c ...
- python学习之文件读写,序列化(json,pickle,shelve)
python基础 文件读写 凡是读写文件,所有格式类型都是字符串形式传输 只读模式(默认) r f=open('a.txt','r')#文件不存在会报错 print(f.read())#获取到文件所 ...
- 使用Python从PDF文件中提取数据
前言 数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据.然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了 ...
随机推荐
- [转]怎么学习前端,尤其是 JavaScript 这块
1. 先看看 w3school ,了解什么是 js,再找几本写 js 小效果的书看看,知道 js 干什么: 2. 然后再去通读 API,推荐 <Javascript权威指南>,第四版吧,第 ...
- c#循环语句 for 循环嵌套的练习。还有跳转语句,异常语句,迭代穷举介绍
先说一下循环嵌套:循环嵌套就是再一个循环里面再放一个循环,也就是说如果没一个循环都循环10次,那么第一个循环是1的时候,嵌套的循环会循环十次.也就是10*10的效果. for 循环语句 主要还是逻辑思 ...
- easyUI datagrid 分页参数page和rows
Struts2获取easyUI datagrid 分页参数page和rows 用pageHelper分页时,只要是能够获取前台传来的两个参数page和rows基本就完成了很大一部分. 获取方法:定义两 ...
- Elasticsearch suggester搜索建议初步
环境 Elasticsearch 2.3.5 Elasticsearch-ik-plugin 实现 搜索建议的对象 假设有以下两个json对象,需要对其中tags字段进行搜索建议: //对象Produ ...
- APP 市场需求网址
http://mi.talkingdata.com/terminals.html?terminalType=4
- 网站下载器WebZip、Httrack及AWWWB.COM网站克隆器
动机 闲扯节点,可略读. 下载并试用这些软件并非是为了一己之私,模仿他人网站以图利.鉴于国内网络环境之艰苦,我等屌丝级半罐水程序员,纵有百度如诸葛大神万般协力相助,也似后主般无能不能解决工作和娱乐中 ...
- ipmitool查询服务器功耗
通过ipmitool查看服务器功耗 ipmitool -H $ip -I lanplus -U $user -P $password sdr elist | grep "Pwr Consum ...
- .NET 实体转换辅助类
/// <summary> /// 实体转换辅助类 /// </summary> public class ModelConvertHelper<T> where ...
- AU3获取系统激活信息
If IsActivated() = False Then ;InstallProductKey($OSkey) ; installs a product key and also activates ...
- 【转】Linux将composer的bin目录放到PATH环境变量中
将composer的bin目录放到PATH环境变量中 使用composer global config bin-dir --absolute查看composer的bin目录 输出类似 Changed ...