【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
问题描述
通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接。
mechanicalsoup模块
MechanicalSoup无需图形界面环境下的浏览器开源项目,是一个基于极其流行而异常多能的 HTML 解析库 Beautiful Soup 建立的爬虫库。如果你的爬虫需要相当的简单,但是又要求检查一些选择框或者输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
安装
pip install MechanicalSoup
需要BeautifulSoup和requests库的依赖。
解析百度网页源码
分析百度网页源代码,找到用来接收搜索关键字的表单和输入框。
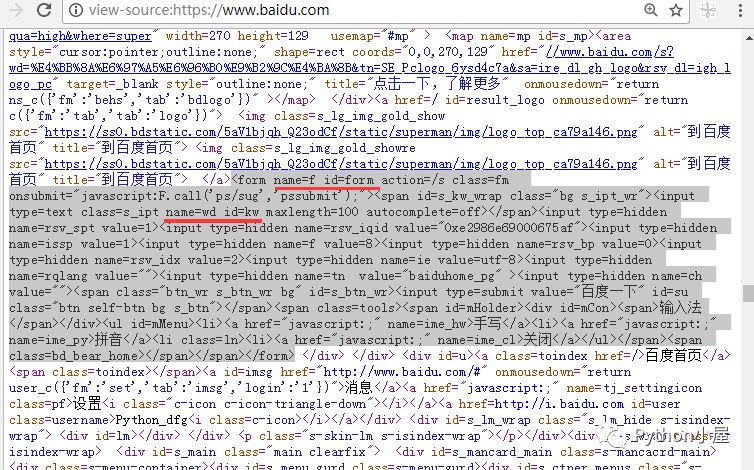
程序实现
map函数
map函数第一个参数为函数,但不需要'()',第二个参数是迭代器对象,作用是对迭代器对象遍历使用第一个函数。
- #!/usr/bin/env python
- #-*- coding:utf-8 -*-
- """
- @author:BanShaohuan
- @file: Python 3.6模拟输入并爬取百度前10页密切相关链接
- @time: 2018/06/09
- @contact: banshaohuan@163.com
- @software: PyCharm
- """
- import mechanicalsoup
- # python小屋文章清单
- with open('list.txt', encoding="utf8") as fp:
- articles = fp.readlines()
- #=> 使用map函数,去掉从文本当中读取时的字符,并放入元组中
- articles = tuple(map(str.strip, articles))
- # 模拟打开指定网址,模拟输入并提交输入的关键字
- browser = mechanicalsoup.StatefulBrowser() #=> 新建一个对象
- browser.open(r'http://www.baidu.com')#=> 模拟打开百度
- browser.select_form("#form")#=> 根据class指定一个表单
- browser['wd'] = 'Python小屋'#=> 根据表单的id指定表单中输入的内容
- browser.submit_selected()#=> 提交,模拟搜索
- # 获取百度前十页
- top10Urls = []
- #=> get_current_page得到本页网页,得到a标签对象
- for link in browser.get_current_page().select('a'):
- if link.text in tuple(map(str, range(2, 11))):
- #=> link.attrs['href] a标签中的属性得到值
- top10Urls.append(r'http://www.baidu.com'+ link.attrs['href'])
- # 与微信公众号里的文章标题进行比对,如果非常相似就返回True
- def check(text):
- for article in articles:
- # 使用切片,防止网站转发公众号文章时标题不完整
- if article[2:-2].lower() in text.lower():
- return True
- return False
- # 只输出密切相关的链接
- def getLinks():
- for link in browser.get_current_page().select('a'):
- text = link.text
- if 'Python小屋' in text or '董付国' in text or check(text):
- print(link.text, '-->', link.attrs['href'])
- # 输出第一页
- getLinks()
- # 处理后面的9页
- for url in top10Urls:
- browser.open(url)
- getLinks()
参考内容:Python 3.6模拟输入并爬取百度前10页密切相关链接

【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- Python 基础语法+简单地爬取百度贴吧内容
Python笔记 1.Python3和Pycharm2018的安装 2.Python3基础语法 2.1.1.数据类型 2.1.1.1.数据类型:数字(整数和浮点数) 整数:int类型 浮点数:floa ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- python简单爬虫 用beautifulsoup爬取百度百科词条
目标:爬取“湖南大学”百科词条并处理数据 需要获取的数据: 源代码: <div class="basic-info cmn-clearfix"> <dl clas ...
- Python爬虫之简单的爬取百度贴吧数据
首先要使用的第类库有 urllib下的request 以及urllib下的parse 以及 time包 random包 之后我们定义一个名叫BaiduSpider类用来爬取信息 属性有 url: ...
- python制作的翻译器基于爬取百度翻译【笔记思路】
#!/usr/bin/python # -*- coding: cp936 -*- ################################################### #基于百度翻 ...
- Python每日一练(3):爬取百度贴吧图片
import requests,re #先把要访问URL和头部准备好 url = 'http://tieba.baidu.com/p/2166231880' head = { 'Accept': '* ...
随机推荐
- spring bean属性及子元素使用总结
spring bean属性及子元素使用总结 2016-08-03 00:00 97人阅读 评论(0) 收藏 举报 分类: Spring&SpringMVC(17) 版权声明:本文为博主原创 ...
- 第二天:tomcat体系结构和第一个Servlet
1. 打war包 2. Tomcat体系再说明: 问题:如何去配置默认主机??? 3.tomcat和servlet在网络中的位置 4. servlet快速入门案例 1).开发s ...
- 新创建的maven项目,显示的jdk版本与使用的不一致
解决:是在安装的maven中的setting.xml配置文件中添加 在setting.xml配置文件中的<profiles></profiles>这个元素中加以下代码 如果加上 ...
- java线程的三种实现方式
线程实现的三种种方式: 一个是继承Thread类,实现run()方法: 一个是实现Runnable接口,实现run()方法: 一个是实现Callable接口,实现call()方法:该方式和实现Runn ...
- ubuntu16安装pylearn2 出现错误提示importerror:no module named six.moves
由于市面上的一些教程时间比较早,入门学习时跟随教程安装容易出现各种错误,这些错误基本都是版本不同导致的 所以,我们安装过程中一定要指出包的版本,如果你已经遇到no module named six.m ...
- The Apache Tomcat installation at this directory is version 8.5.24 Tomcat 8.0 installation is expect
在一台新电脑上搭建Java开发环境,JDK 是1.8,Tomcat下载了Tomcat 8.5.24,已经配置好了Java和Tomcat的环境变量,开发工具是Eclipse MARS,准备在Eclips ...
- ROS Learning-028 (提高篇-006 A Mobile Base-04) 控制移动平台 --- (Python编程)控制虚拟机器人的移动(不精确的制定目标位置)
ROS 提高篇 之 A Mobile Base-04 - 控制移动平台 - (Python编程)控制虚拟机器人的移动(不精确的制定目标位置) 我使用的虚拟机软件:VMware Workstation ...
- JavaPersistenceWithMyBatis3笔记-第3章SQL Mappers Using XMLs-001
一. 1.Mapper 2.Service 3.Domain package com.mybatis3.domain; import java.io.Serializable; import java ...
- Linux bc命令
一.简介 GNU bc是一款基于命令行的计算器程序,支持高精度数字和多种数值类型(例如二进制.十进制.十六进制)的输入输出. 二.实例 http://www.linuxidc.com/Linux/20 ...
- Linux 控制台/终端/tty/shell
一.简介 使用linux已经有一段时间,却一直弄不明白这几个概念之间的区别.这些概念本身有着非常浓厚的历史气息,随着时代的发展,他们的含义也在发生改变,它们有些已经失去了最初的含义,但是它们的名字却被 ...