python爬虫入门(1)-urllib模块
- url:需要打开的网址
- data:Post提交的数据
- timeout:设置网站的访问超时时间
import urllib.request
response = urllib.request.urlopen("http://www.fishc.com")#是一个HTTP响应类型
html =response.read()#读取响应内容,为bytes类型
# print(type(html),html) #输出的为一串<class 'bytes'>
html = html.decode('utf-8')#bytes类型解码为str类型
print(html)
import urllib.request
response = urllib.request.urlopen("http://placekitten.com/g/400/400")
cat_img = response.read()
with open('cat_400_400.jpg','wb')as f:
f.write(cat_img)
import urllib.request
import urllib.parse
import json
import time
while True:
content = input("请输入需要翻译的内容《输入q!退出程序》:")
if content == 'q!':
break
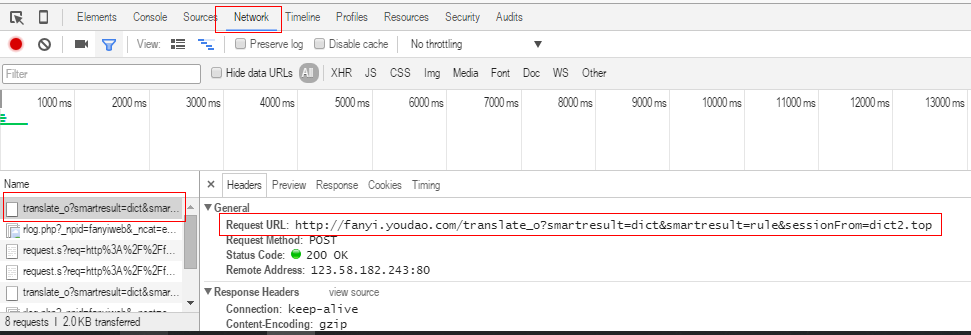
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=http://www.youdao.com/" #即RequestURL中的链接
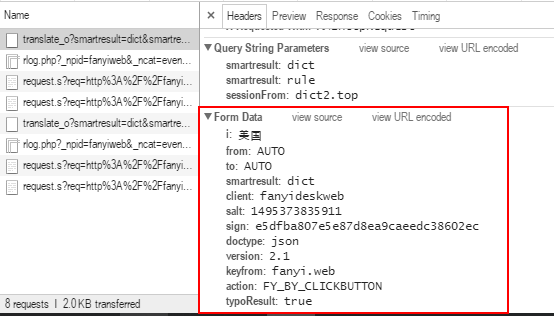
data = {}
#Form Data中的内容,适当删除无用信息
data['i'] = content
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
#打开网址并提交表单
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html)
print("翻译结果:%s" % (target['translateResult'][0][0]['tgt']))
time.sleep(2)
import urllib.request
import random
url ='http://www.whatismyip.com.tw/'
iplist =['61.191.41.130:80','115.46.97.122:8123',] #参数是一个字典{'类型':'代理IP:端口号'}
proxy_support = urllib.request.ProxyHandler({'http':random.choice(iplist)})
#定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
#通过addheaders修改User-Agent
opener.addheaders =[('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.97 Safari/537.36')]
#安装opener
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
print(html)
import urllib.request
import re
def open_url(url):
#打开URL并修改header,将URL内容读取
req = urllib.request.Request(url)
#通过add_header修改User-Agent
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.97 Safari/537.36')
page = urllib.request.urlopen(req)
html = page.read().decode('utf-8')
return html def get_img(html):
p = r'<img class="BDE_Image" src="([^"]+\.jpg)'
imglist = re.findall(p,html)#寻找到图片的链接
for each in imglist:
filename = each.split("/")[-1]
urllib.request.urlretrieve(each,filename,None)#保存图片
if __name__ =='__main__':
url ="https://tieba.baidu.com/p/5090206152"
get_img(open_url(url))
python爬虫入门(1)-urllib模块的更多相关文章
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- Python爬虫入门:Urllib库的高级使用
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门:Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它 是一段HTML代码,加 JS.CS ...
- 芝麻HTTP:Python爬虫入门之Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- 芝麻HTTP: Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门:Urllib parse库使用详解(二)
文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习 如有侵权,请联系删除 获取url参数 urlparse 和 parse_qs ParseRes ...
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
随机推荐
- iOS开发进阶 - 自定义UICollectionViewLayout实现瀑布流布局
移动端访问不佳,请访问我的个人博客 最近项目中需要用到瀑布流的效果,但是用UICollectionViewFlowLayout又达不到效果,自己动手写了一个瀑布流的layout,下面是我的心路路程 先 ...
- dp之最长上升子序列
普通做法是O(n^2)下面介绍:最长上升子序列O(nlogn)算法(http://blog.csdn.net/shuangde800/article/details/7474903) /* HDU 1 ...
- 关于C#中的垃圾回收
http://cnn237111.blog.51cto.com/2359144/1343004 GC.Collect如何影响垃圾回收 主要是 //GC.Collect(); //GC.WaitF ...
- [WCF安全3]使用wsHttpBinding构建基于SSL与UserName授权的WCF应用程序
上一篇文章中介绍了如何使用wsHttpBinding构建UserName授权的WCF应用程序,本文将为您介绍如何使用wsHttpBinding构建基于SSL的UserName安全授权的WCF应用程序. ...
- QT 样式表实例
目标:实现button的圆角效果及背景颜色,鼠标滑过颜色变亮,鼠标点击颜色变重. 总体思路首,先根据需要及样式规则新建.qss文件,然后在代码中将文件引用并应用样式. 具体过程如下: 1在项目当前目录 ...
- POJ3768 Katu Puzzle
本文版权归ljh2000和博客园共有,欢迎转载,但须保留此声明,并给出原文链接,谢谢合作. 本文作者:ljh2000 作者博客:http://www.cnblogs.com/ljh2000-jump/ ...
- 面向对象-PHP面向对象的特性
1.类和公有化 class Computer { //什么叫做类内,就是创建类的花括号内的范围叫做类内,其他地方则类外. //public 是对字段的公有化,这个字段类外即可访问,赋 ...
- python - pandas或者sklearn中如何将字符形式的标签数字化
参考:http://www.php.cn/wenda/91257.html https://www.cnblogs.com/king-lps/p/7846414.html http://blog.cs ...
- 个人知识管理系统Version1.0开发记录(03)
demo 设 计 一个知识点demo,在数据库和用户界面的互动事件.分三个层次,数据存储,数据方法工具,数据呈现界面.这一次先完成数据存储,按以下逻辑实现.工具:eclipse,oracle数据库, ...
- Pytorch 一些函数用法
PyTorch中view的用法:https://blog.csdn.net/york1996/article/details/81949843 max用法 import torch d=torch.T ...