python的scrapy框架
scrapy是python中数据抓取的框架。简单的逻辑如下所示
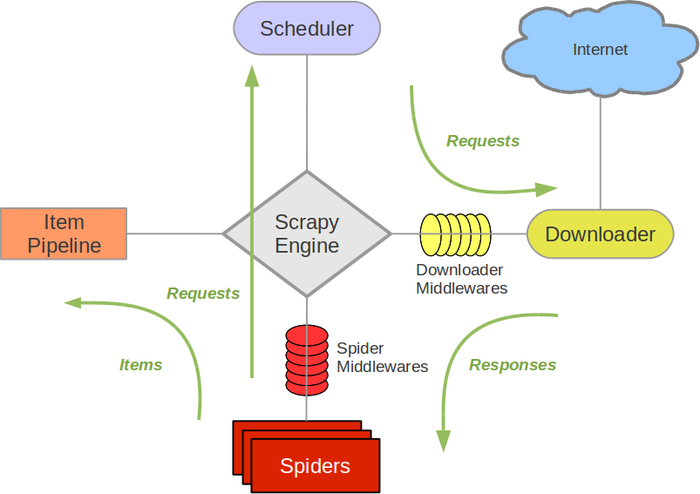
scrapy的结构如图所示,包括scrapy engine、scheduler、downloader、spider、item pipeline。
scrapy engine:引擎,是负责scheduler、downloader、spider、item pipeline之间的消息的传递等等
scheduler:调度器,是负责接受scrapy engine 的request请求,并将request进行整理排列,入队,等待scrapy engine来请求时,交给引擎
downloader:下载器,是用来下载scrapy engine的请求,并将response返回给spider。
spider:爬虫,是将downloader的response,由spider分析并提取item所要抓取的数据,并将所要跟进的url再次交给scrapy engine,再次进入scheduler。
item pipeline:项目管道,是将spider中提取到的数据,进行处理,存储。
还有两个:
download middlewares:下载中间件,是一个可以扩展的下载功能的组件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
spider middlewares:spider的中间件:是一个可以扩展和操作引擎和spider中间通信的功能组件(比如进入spider的response,和从spider传出去的request),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出
这俩当前还没有试过~
经过:
1.scrapy engine获取到spider要获取的第一个url
2.scrapy engine将要获取的url给scheduler,并将url入队,整理,并将处理好的request请求返回
3.scrapy engine将处理好的request给downloader,通过downloader下载数据,如果下载失败,会将下载失败的结果告诉scrapy engine,然后会让scrapy engine等会再次请求下载。
4.scrapy engine获取到downloader下载的数据,并且将数据给spider,经由spider进行数据处理,spider将需要跟进的request交给scrapy engine,将处理的结果返回给item pipeline
5.item pipeline将spider反悔的结果进行去重,持久化,写入数据库等操作。
只有当scheduler中没有任何request了,整个过程才会停止。
python的scrapy框架的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- python安装Scrapy框架
看到自己写的惨不忍睹的爬虫,觉得还是学一下Scrapy框架,停止一直造轮子的行为 我这里是windows10平台,python2和python3共存,这里就写python2.7安装配置Scrapy框架 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
随机推荐
- 常州day2
Task1 为了测试小 W 的数学水平,果果给了小 W N 个点,问他这 N 个点能构成的三角形个数. 对于 100%的数据:N<=100,保证任意两点不重合,坐标<=10000 恶心题( ...
- 洛谷 [POI2007]BIU-Offices 解题报告
[POI2007]BIU-Offices 题意 给定\(n(\le 100000)\)个点\(m(\le 2000000)\)条边的无向图\(G\),求这个图\(G\)补图的连通块个数. 一开始想了半 ...
- Communications link failure;;The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure::The ...
- 解题:POI 2009 TAB
题面 这也算是个套路题(算吗)?发现换来换去每行每列数的组成是不变的,那么就把每行每列拎出来哈希一下,复杂度$O(Tn^2log$ $n)$有点卡时=.=. 然而正解似乎不需要哈希,就像这样↓ ;i& ...
- Linux系统之路——python多版本共存问题(ps:自行切换python版本,pip安装遇到的一些问题)
经常遇到这样的情况: 系统自带的Python是2.6,自己需要Python 2.7中的某些特性: 系统自带的Python是2.x,自己需要Python 3.x: 此时需要在系统中安装多个Python, ...
- python基础6--目录结构
为什么要设计好目录结构? "设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题.对于这种风格上的规范,一直都存在两种态度: 一类同学认为,这种个人风 ...
- 「CSS」文本编排相关的CSS属性设置
1.font-family:设置字体族. 格式为font-family:字体1,字体2,……,通用字体族|inherit. 通用字体族,是指一类相似的字体.W3C的CSS规则规定,要指定一个通用字体族 ...
- 从一个集合中过滤另一个集合中存在的项(类似in)
直接贴代码出来: List<PriceMark> list = PriceMarkDAL.m_PriceMarkDAL.GetList("Erp_ProName='TLC7528 ...
- [DeeplearningAI笔记]序列模型2.3-2.5余弦相似度/嵌入矩阵/学习词嵌入
5.2自然语言处理 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3词嵌入的特性 properties of word embedding Mikolov T, Yih W T, Zwe ...
- webpack4.0.1安装问题及解决方法
2月底的时候,webpack4正式发布了,但是当我们安装之后,使用下面的语句来打包的时候,发现打包失败了 webpack ./src/main.js ./dist/bundle.js 并且给出了下面这 ...