【Python】理想论坛每小时发帖量统计图表
写以下代码的目的是分析一天中各时段理想论坛中用户发帖回帖的活跃程度,获得结尾那张图表是核心。
以下代码两种爬虫协助,论坛爬虫先爬主贴,爬到主贴后启动帖子爬虫爬子贴,然后把每个子贴的发表时间等存入数据库。
再用一个程序对各个时段中发帖次数进行统计,然后用Excel生产图表。
获取数据的爬虫代码如下:
# 论坛爬虫,用于爬取主贴再爬子贴
from bs4 import BeautifulSoup
import requests
import threading
import re
import pymysql
user_agent='Mozilla/4.0 (compatible;MEIE 5.5;windows NT)'
headers={'User-Agent':user_agent}
# 论坛爬虫类(多线程)
class forumCrawler(threading.Thread):
def __init__(self,name,url):
threading.Thread.__init__(self,name=name)
self.name=name
self.url=url
self.infos=[]
def run(self):
print("线程"+self.name+"开始爬取页面"+self.url);
try:
rsp=requests.get(self.url,headers=headers)
soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='utf-8')
#print(rsp.text); # rsp.text是全文
# 找出span
for spans in soup.find_all('span',class_="forumdisplay"):
#找出link
for link in spans.find_all('a'):
if link and link.get("href"):
#print(link.get("href"))
#print(link.text+'\n')
topicLink="http://www.55188.com/"+link.get("href")
tc=topicCrawler(name=self.name+'_tc#'+link.get("href"),url=topicLink)
tc.start()
except Exception as e:
print("线程"+self.name+"发生异常。")# 不管怎么出现的异常,就让它一直爬到底
print(e);
# 帖子爬虫类(多线程)
class topicCrawler(threading.Thread):
def __init__(self,name,url):
threading.Thread.__init__(self,name=name)
self.name=name
self.url=url
self.infos=[]
def run(self):
while(self.url!="none"):
print("线程"+self.name+"开始爬取页面"+self.url);
try:
rsp=requests.get(self.url,headers=headers)
self.url="none"#用完之后置空,看下一页能否取到值
soup= BeautifulSoup(rsp.text,'html.parser',from_encoding='utf-8')
#print(rsp.text); # rsp.text是全文
# 找出一页里每条发言
for divs in soup.find_all('div',class_="postinfo"):
#print(divs.text) # divs.text包含作者和发帖时间的文字
# 用正则表达式将多个空白字符替换成一个空格
RE = re.compile(r'(\s+)')
line=RE.sub(" ",divs.text)
arr=line.split(' ')
#print(len(arr))
arrLength=len(arr)
if arrLength==7:
info={'楼层':arr[1],
'作者':arr[2].replace('只看:',''),
'日期':arr[4],
'时间':arr[5]}
self.infos.append(info);
elif arrLength==8:
info={'楼层':arr[1],
'作者':arr[2].replace('只看:',''),
'日期':arr[5],
'时间':arr[6]}
self.infos.append(info);
#找下一页所在地址
for pagesDiv in soup.find_all('div',class_="pages"):
for strong in pagesDiv.find_all('strong'):
print('当前为第'+strong.text+'页')
# 找右边的兄弟节点
nextNode=strong.next_sibling
if nextNode and nextNode.get("href"): # 右边的兄弟节点存在,且其有href属性
#print(nextNode.get("href"))
self.url='http://www.55188.com/'+nextNode.get("href")
if self.url!="none":
print("有下一页,线程"+self.name+"前往下一页")
continue
else:
print("无下一页,线程"+self.name+'爬取结束,开始打印...')
for info in self.infos:
print('\n')
for key in info:
print(key+":"+info[key])
print("线程"+self.name+'打印结束.')
insertDB(self.name,self.infos)
except Exception as e:
print("线程"+self.name+"发生异常。重新爬行")# 不管怎么出现的异常,就让它一直爬到底
print(e);
continue
# 数据库插值
def insertDB(crawlName,infos):
conn=pymysql.connect(host=',db='test',charset='utf8')
for info in infos:
sql="insert into test.topic(floor,author,tdate,ttime,crawlername,addtime) values ('"+info['楼层']+"','"+info['作者']+"','"+info['日期']+"','"+info['时间']+"','"+crawlName+"',now() )"
print(sql)
conn.query(sql)
conn.commit()# 写操作之后commit不可少
conn.close()
# 入口函数
def main():
for i in range(1,10):
url='http://www.55188.com/forum-8-'+str(i)+'.html'
tc=forumCrawler(name='fc#'+str(i),url=url)
tc.start()
# 开始
main()
控制台输出太多就不贴了,把插入数据后的数据库展示一下,ttime字段就是想要获得的关键数据:
再做一个小程序对发帖时间进行统计,代码如下:
# 对发帖时间进行统计
import pymysql
# 入口函数
def main():
dic={':0}
conn=pymysql.connect(host=',db='test',charset='utf8')
cs=conn.cursor()
cs.execute("select * from topic")
results = cs.fetchall()
for row in results:
ttime=row[4]
hour=ttime.split(':')[0]
dic[hour]=dic[hour]+1
conn.close()
print(dic)
# 开始
main()
输出字典如下:
C:\Users\horn1\Desktop\python\17>python sum.py
{': 388}
用Excel来个图形化看看:
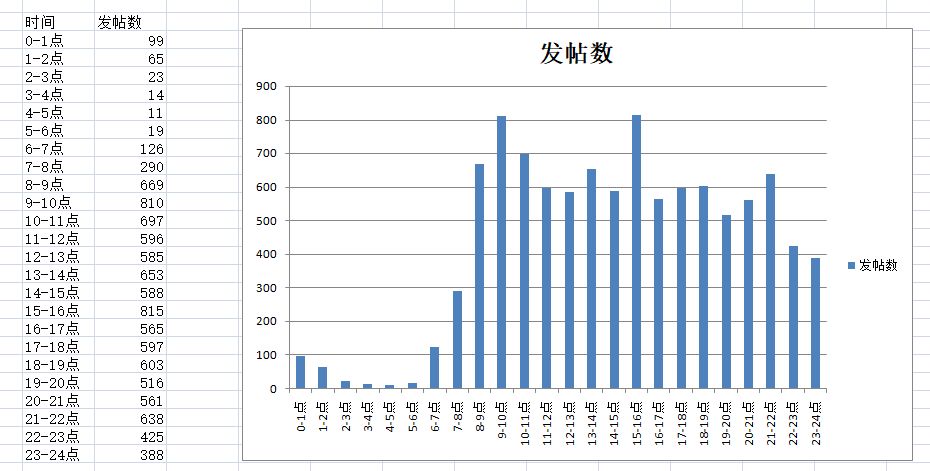
从上图可以得出以下结论:
1.早上0点-6点是交易者最闲的时候,他们大部分都在睡觉,3-5点睡得最熟。
2.发帖峰值一个是在9-10点,一个是15-16点。股市在9:30开盘,低开高开也出来了,行情也走了一段,大家开始热情高涨了发帖,之后就逐步回落,午休落入低谷,下午15点收盘后,大家又争相发表对这天行情的看法,但能一天走势能谈多少,于是一个小时就消停了。另外15-16点也是股评家发表股评的黄金时段。
3.入夜了,虽然早已收盘,大家依旧在浏览论坛,希望从帖子里发现什么或者讨论什么,直到23-24点还有不少人从事这项活动。
呵呵,我也玩票了一把数据分析。
2018年4月4日16点14分
【Python】理想论坛每小时发帖量统计图表的更多相关文章
- 【ichartjs】爬取理想论坛前30页帖子获得每个子贴的发帖时间,总计83767条数据进行统计,生成统计图表
统计数据如下: {': 2451} 图形化后效果如下: 源码: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//E ...
- 【pyhon】理想论坛爬虫1.08
#------------------------------------------------------------------------------------ # 理想论坛爬虫1.08,用 ...
- 【Python】爬取理想论坛单帖爬虫
代码: # 单帖爬虫,用于爬取理想论坛帖子得到发帖人,发帖时间和回帖时间,url例子见main函数 from bs4 import BeautifulSoup import requests impo ...
- 【python】理想论坛爬虫长贴版1.00
理想论坛有些长贴,针对这些长贴做统计可以知道某ID什么时段更活跃. 爬虫代码为: #---------------------------------------------------------- ...
- 【python】理想论坛爬虫1.08
#------------------------------------------------------------------------------------ # 理想论坛爬虫1.08, ...
- 【python】理想论坛帖子爬虫1.06
昨天认识到在本期同时起一百个回调/线程后程序会崩溃,造成结果不可信. 于是决定用Python单线程操作,因为它理论上就用主线程跑不会有问题,只是时间长点. 写好程序后,测试了一中午,210个主贴,11 ...
- 【Python】理想论坛帖子读取爬虫1.04版
1.01-1.03版本都有多线程争抢DB的问题,线程数一多问题就严重了. 这个版本把各线程要添加数据的SQL放到数组里,等最后一次性完成,这样就好些了.但乱码问题和未全部完成即退出现象还在,而且速度上 ...
- 【Python】分析自己的博客 https://www.cnblogs.com/xiandedanteng/p/?page=XX,看每个月发帖量是多少
要执行下面程序,需要安装Beautiful Soup和requests,具体安装方法请见:https://www.cnblogs.com/xiandedanteng/p/8668492.html # ...
- 【Nodejs】理想论坛帖子爬虫1.01
用Nodejs把Python实现过的理想论坛爬虫又实现了一遍,但是怎么判断所有回调函数都结束没有好办法,目前的spiderCount==spiderFinished判断法在多页情况下还是会提前中止. ...
随机推荐
- ssm+RESTful bbs项目后端主要设计
小谈: 帖主妥妥的一名"中"白了哈哈哈.软工的大三狗了,也即将找工作,怀着丝丝忐忑接受社会的安排.这是第一次写博客(/汗颜),其实之前在学习探索过程中,走了不少弯路,爬过不少坑.真 ...
- (bc 1001) hdu 6015 skip the class
Skip the Class Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) T ...
- [2]树的DFS序
定义: 树的DFS序就是在对树进行DFS的时候,对树的节点进行重新编号:DFS序有一个很强的性质: 一颗子树的所有节点在DFS序内是连续的一段, 利用这个性质我们可以解决很多问题. 代码: void ...
- Matrix-tree定理 spoj HIGH
Matrix-tree定理,给出一个无向图,问求出的生成树方案有多少种方案,利用Matrix-tree定理,主对角线第i行是i的度数,(i,j) 值为i和j之间边的数量,然后删去第一行第一列,利用初等 ...
- python3-开发进阶 django-rest framework 中的 版本操作(看源码解说)
今天我们来说一说rest framework 中的 版本 操作的详解 首先我们先回顾一下 rest framework的流程: 请求进来走view ,然后view调用视图的dispath函数 为了演示 ...
- Failed to read auto-increment value from storage engine错误的处理方法
在进行数据的插入时,系统提示Failed to read auto-increment value from storage engine(从存储引擎读取自增字段失败)错误,经查阅资料,解决方法如下: ...
- php -- php读取sqlserver中的datetime出现的格式问题
php连接sqlserver2005时,读取出来的数据是01 15 2014 12:00AM, 也就是说日期的格式是MM DD YY hh:mmAM 那如何把它转变成24小时制,且显示的格式为YY-M ...
- [转] 关于Struts-JSON配置(详解带实例struts2的json数据支持)
关于Struts-JSON的提高开发效率 一.JSON是什么? :JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.易于人阅读和编写,同时也易于机器解 析和 ...
- HDU 5650 so easy 数学
so easy 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5650 Description Given an array with n integ ...
- HDU 5646 DZY Loves Partition 数学 二分
DZY Loves Partition 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5646 Description DZY loves parti ...