《机器学习实战》AdaBoost算法(手稿+代码)
Adaboost:多个弱分类器组成一个强分类器,按照每个弱分类器的作用大小给予不同的权重 |
一.Adaboost理论部分
1.1 adaboost运行过程
注释:算法是利用指数函数降低误差,运行过程通过迭代进行。其中函数的算法怎么来的,你不用知道!当然你也可以尝试使用其它的函数代替指数函数,看看效果如何。

1.2 举例说明算法流程
略,花几分钟就可以看懂的例子。见:《统计学习方法》李航大大
博客都是借鉴(copy)李航博士的:http://blog.csdn.net/v_july_v/article/details/40718799 ,July算总结(copy)最好的吧!
1.3 算法误差界的证明
注释:误差的上界限由Zm约束,然而Zm又是由Gm(xi)约束,所以选择适当的Gm(xi)可以加快误差的减小。

二.代码实现
注释:这里参考大神博客http://blog.csdn.net/guyuealian/article/details/70995333,举例子很详细。
2.1程序流程图

2.2基本程序实现
注释:真是倒霉玩意,本来代码全部注释好了,突然Ubuntu奔溃了,全部程序就GG了。。。下面的代码就是官网的代码,部分补上注释。现在使用Deepin桌面版了,其它方面都比Ubuntu好,但是有点点卡。
from numpy import * def loadDataSet(fileName): #general function to parse tab -delimited floats
numFeat = len(open(fileName).readline().split('\t')) #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#loop over all range in current dimension
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error multiplied by D
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print ("total error: ",errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
#print aggClassEst
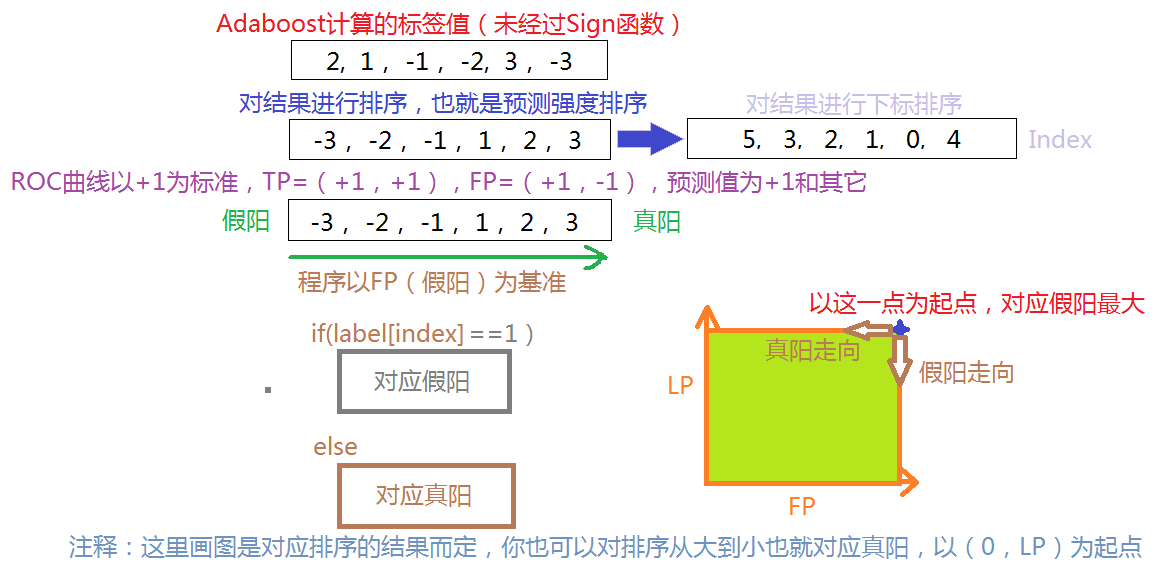
return sign(aggClassEst) def plotROC(predStrengths, classLabels):
import matplotlib.pyplot as plt
cur = (1.0,1.0) #cursor
ySum = 0.0 #variable to calculate AUC
numPosClas = sum(array(classLabels)==1.0)#标签等于1的和(也等于个数)
yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas)
sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse
sortData = sorted(predStrengths.tolist()[0]) fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
#loop through all the values, drawing a line segment at each point
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep;
else:
delX = xStep; delY = 0;
ySum += cur[1]
#draw line from cur to (cur[0]-delX,cur[1]-delY)
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0,1,0,1])
plt.show()
print ("the Area Under the Curve is: ",ySum*xStep)
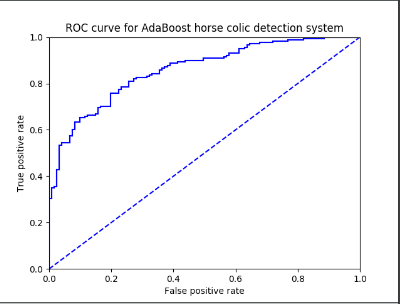
注释:重点说明一下非均衡分类的图像绘制问题,想了很久才想明白!
都是相对而言的,其中本文说的曲线在左上方就为好,也是相对而言的,看你怎么定义个理解!
参考文献:
《统计学习方法》李航
http://blog.csdn.net/v_july_v/article/details/40718799没有书的就看这个大神的博客,基本是上面那本数的原版
《机器学习实战》AdaBoost算法(手稿+代码)的更多相关文章
- 机器学习之AdaBoost原理与代码实现
AdaBoost原理与代码实现 本文系作者原创,转载请注明出处: https://www.cnblogs.com/further-further-further/p/9642899.html 基本思路 ...
- Adaboost算法及其代码实现
. . Adaboost算法及其代码实现 算法概述 AdaBoost(adaptive boosting),即自适应提升算法. Boosting 是一类算法的总称,这类算法的特点是通过训练若干弱分类器 ...
- 机器学习实战-AdaBoost
1.概念 从若学习算法出发,反复学恶习得到一系列弱分类器(又称基本分类器),然后组合这些弱分类器构成一个强分类器.简单说就是假如有一堆数据data,不管是采用逻辑回归还是SVM算法对当前数据集通过分类 ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 机器学习实战 logistic回归 python代码
# -*- coding: utf-8 -*- """ Created on Sun Aug 06 15:57:18 2017 @author: mdz "&q ...
- 《机器学习实战》学习笔记第七章 —— AdaBoost元算法
主要内容: 一.提升方法与AdaBoost算法的简介 二.AdaBoost算法 三.代码解释 一.提升方法与AdaBoost算法的简介 1.提升方法:从弱学习算法出发,反复学习,得到一系列弱分类器(又 ...
- 机器学习&深度学习基础(机器学习基础的算法概述及代码)
参考:机器学习&深度学习算法及代码实现 Python3机器学习 传统机器学习算法 决策树.K邻近算法.支持向量机.朴素贝叶斯.神经网络.Logistic回归算法,聚类等. 一.机器学习算法及代 ...
- 学习笔记之机器学习实战 (Machine Learning in Action)
机器学习实战 (豆瓣) https://book.douban.com/subject/24703171/ 机器学习是人工智能研究领域中一个极其重要的研究方向,在现今的大数据时代背景下,捕获数据并从中 ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- 《机器学习实战》学习笔记第十三章 —— 利用PCA来简化数据
相关博文: 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA) 主成分分析(PCA)的推导与解释 主要内容: 一.向量內积的几何意义 二.基的变换 三.协方差矩阵 四.PCA求解 一.向量內 ...
随机推荐
- Linux yum仓库配置
yum仓库配置 10.1 概述 YUM(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器.基于RPM包 ...
- kafka_2.11-0.10.0.1生产者producer的Java实现
转载自:http://blog.csdn.net/qq_26479655/article/details/52555283 首先导入包 将kafka目录下的libs中的jar包导入 用maven建立 ...
- Kafka三款监控工具比较
在之前的博客中,介绍了Kafka Web Console这个监控工具,在生产环境中使用,运行一段时间后,发现该工具会和Kafka生产者.消费者.ZooKeeper建立大量连接,从而导致网络阻塞.并且这 ...
- 基于Eclipse搭建hadoop开发环境
一.基础环境准备 1.Eclipse 下载地址:http://pan.baidu.com/s/1slArxAP 2.JDK1.8 下载地址:http://pan.baidu.com/s/1i5iNy ...
- php统计中英文混合的文章字数
function ccStrLen($str) #计算中英文混合字符串的长度 { $ccLen=0; $ascLen=strlen($str); $ind=0; $hasCC=ereg("[ ...
- 关于libusb-win32开发的经验
引用:http://blog.sina.com.cn/s/blog_4b4b54da010153zb.html 作为设备开发者, 一般需要让设备与上位机PC通讯, 我们往往考虑采用以下几种接口: rs ...
- DS二叉树--二叉树构建与遍历
题目描述 给定一颗二叉树的逻辑结构如下图,(先序遍历的结果,空树用字符‘0’表示,例如AB0C00D00),建立该二叉树的二叉链式存储结构,并输出该二叉树的先序遍历.中序遍历和后序遍历结果 输入 第一 ...
- 解决MSDE安装回滚的问题
rem 解决MSDE安装回滚的问题.bat rem 设置为手动rem sc config "LanmanServer" start= DEMAND rem 设置为自动sc conf ...
- Bitmap BitmapData
var sp:Sprite=new Sprite(); sp.graphics.beginFill(0xffccdd); sp.graphics.drawRect(0,0,100,100); sp.g ...
- Ubuntu 14.10 下Eclipse操作HBase
环境介绍 64位Ubuntu14.10,Hadoop 2.5.0 ,HBase 0.99.0 准备环境 1 安装Hadoop 2.5.0,可参考http://www.cnblogs.com/liuch ...