jmeter的线程数,并发用户数,TPS,RPS 关系解说
背景
在做性能测试的时候,传统方式都是用并发虚拟用户数来衡量系统的性能(站在客户端视角),一般适用于一些网页站点例如首页、H5的压测;而RPS(Requests per second)模式主要是为了方便直接衡量系统的吞吐能力TPS(Transaction Per Second,每秒事务数)而设计的(站在服务端视角),按照被压测端需要达到TPS等量设置相应的RPS,应用场景主要是一些动态的接口API,例如登录、提交订单等等。
VU(虚拟用户)和TPS之间也有其逻辑关系,具体请参见本文下方的说明。
术语定义
- jmeter的线程数就相当于并发用户数,并发用户数就是虚拟用户数。
- 并发用户数:简称VU,指的是现实系统中操作业务的用户,在性能测试工具中,一般称为虚拟用户数(Virtual User),注意并发用户数跟注册用户数、在线用户数有很大差别的,并发用户数一定会对服务器产生压力的,而在线用户数只是 ”挂” 在系统上,对服务器不产生压力,注册用户数一般指的是数据库中存在的用户数。
- 处理能力:简称TPS,每秒事务数,是衡量系统性能的一个非常重要的指标。
- 响应时间:简称RT,指的是业务从客户端发起到客户端接受的时间。
VU和TPS换算
简单例子:在术语中解释了TPS是每秒事务数,但是事务是要靠虚拟用户做出来的,假如1个虚拟用户在1秒内完成1笔事务,那么TPS明显就是1;如果某笔业务响应时间是1ms,那么1个用户在1秒内能完成1000笔事务,TPS就是1000了;如果某笔业务响应时间是1s,那么1个用户在1秒内只能完成1笔事务,要想达到1000TPS,至少需要1000个用户;因此可以说1个用户可以产生1000TPS,1000个用户也可以产生1000TPS,无非是看响应时间快慢。
复杂公式: 试想一下复杂场景,多个脚本,每个脚本里面定义了多个事务(例如一个脚本里面有100个请求,我们把这100个连续请求叫做Action,只有第10个请求,第20个请求分别定义了事务10和事务20)具体公式如下:
符号代表意义:
Vui表示的是第i个脚本使用的并发用户数
Rtj表示的是第i个脚本第j个事务花费的时间,此时间会影响整个Action时间
Rti表示的是第i个脚本一次完成所有操作的时间,即Action时间
n表示的是第n个脚本
m表示的是每个脚本中m个事务
那么第j个事务的TPS = Vui/Rti
总的TPS=
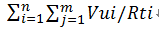
如何获取VU和TPS
- VU获取方式:
已有系统:可选取高峰时刻,在一定时间内使用系统的人数,这些人数可认为是在线用户数,并发用户数可以取10%,例如在半个小时内,使用系统的用户数为10万,那么取10%(即1万)作为并发用户数基本就够了。
新系统:没有历史数据作参考,建议通过业务部门进行评估。
- TPS获取方式:
已有系统:可选取高峰时刻,在一定时间内(如3分钟~10分钟),获取系统总业务量,计算单位时间(秒)内完成的笔数,乘以2-5倍作为峰值的TPS,例如峰值3分钟内处理订单18万笔,平均TPS是1000,峰值TPS可以是2000~5000。
新系统:没有历史数据作参考,建议通过业务部门进行评估。
如何评价系统的性能
针对服务器端的性能,以TPS为主来衡量系统的性能,并发用户数为辅来衡量系统的性能,如果必须要用并发用户数来衡量的话,需要一个前提,那就是交易在多长时间内完成,因为在系统负载不高的情况下,将思考时间(思考时间的值等于交易响应时间)加到串联链路中,并发用户数基本可以增加一倍,因此用并发用户数来衡量系统的性能没太大的意义。同样的,如果系统间的吞吐能力差别很大,那么同样的并发下TPS差距也会很大。
性能测试策略
做性能测试需要一套标准化流程及测试策略。在做负载测试的时候,传统方式一般都是按照梯度施压的方式去加用户数,避免在没有预估的情况下,一次加几万个用户,导致交易失败率非常高,响应时间非常长,已经超过了使用者忍受范围内;较为适合互联网分布式架构的方式。
总结
- 系统的性能由TPS决定,跟并发用户数没有多大关系。
- 系统的最大TPS是一定的(在一个范围内),但并发用户数不一定,可以调整。
- 建议性能测试的时候,不要设置过长的思考时间,以最坏的情况下对服务器施压。
- 一般情况下,大型系统(业务量大、机器多)做压力测试,10000~50000个用户并发,中小型系统做压力测试,5000个用户并发比较常见。
jmeter的线程数,并发用户数,TPS,RPS 关系解说的更多相关文章
- TPS、并发用户数、吞吐量关系
TPS.并发用户数.吞吐量关系 摘要 主要描述了在性能测试中,关于TPS.并发用户数.吞吐量之间的关系和一些计算方法. loadrunner TPS 目录[-] 一.系统吞度量要素: 二.系统吞吐量评 ...
- QPS、TPS、并发用户数、吞吐量关系
1.QPS QPS Queries Per Second 是每秒查询率 ,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准, 即每秒的响应请求数,也即 ...
- 简述 QPS、TPS、并发用户数、吞吐量关系
1. QPS QPS Queries Per Second 是每秒查询率 ,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准, 即每秒的响应请求数,也即 ...
- shell 外部传入jmeter脚本线程数,rampUp时间,持续运行时间
jmeter参数化部分参考上一篇 shell参数说明:$1线程数,$2:全部并发数rampup时间,$3:脚本持续运行时间,$4:每次脚本循环持续时间 $5:所以循环持续时间 #!/bin/bash ...
- LoadRunner之并发用户数与迭代关系---并发数与迭代的区别
Q1: 例如在LR里,我要测100个用户同时并发登陆所用时间,那我是不是在录制好脚本后,需要参数化“用户名”,“密码”以及在那个记事本里构造100个真实的用户名和密码? 然后运行Controller, ...
- 如何理解 jmeter 的线程数与并发数之间的关系
https://blog.csdn.net/weixin_39955351/article/details/110548162 多个线程组的并发是如何计算的?
- 性能测试中TPS和并发用户数
并发用户数与TPS之间的关系 1. 背景 在做性能测试的时候,很多人都用并发用户数来衡量系统的性能,觉得系统能支撑的并发用户数越多,系统的性能就越好:对TPS不是非常理解,也根本不知道它们之间的关系 ...
- ThreadPoolExecutor最佳实践--如何选择线程数
去年看过一篇<ThreadPoolExecutor详解>大致讲了ThreadPoolExecutor内部的代码实现. 总结一下,主要有以下四点: 当有任务提交的时候,会创建核心线程去执行任 ...
- 线程池线程数与(CPU密集型任务和I/O密集型任务)的关系
近期看了一些JVM和并发编程的专栏,结合自身理解,来做一个关于(线程池线程数与(CPU密集型任务和I/O密集型任务)的关系)的总结: 1.任务类型举例: 1.1: CPU密集型: 例如,一般我们系统的 ...
随机推荐
- 【k8s实战一】Jenkins 部署应用到 Kubernetes
[k8s实战一]Jenkins 部署应用到 Kubernetes 01 本文主旨 目标是演示整个Jenkins从源码构建镜像到部署镜像到Kubernetes集群过程. 为了简化流程与容易重现文中效果, ...
- python之解压序列并赋值给变量
N个数量的序列(可迭代对象),赋值给N个变量. 字符串: 1 #!usr/bin/env python3 2 # -*- Coding=utf-8 -*- 3 4 ''' 5 解压序列(或者任何可迭代 ...
- Autofac官方文档翻译--一、注册组件--4组件扫描
官方文档:http://docs.autofac.org/en/latest/register/scanning.html Autofac 组件扫描 在程序集中Autofac 可以使用约定来找到并注册 ...
- 基于LNMP架构搭建wordpress博客之安装架构说明
架构情况 架构情况:基于LNMP架构搭建wordpress系统 软件包版本说明: 系统要求 : CentOS-6.9-x86_64-bin-DVD1.iso PHP版本 : php-7.2.29 ...
- Vue2+Koa2+Typescript前后端框架教程--04班级管理示例(路由调用控制器)
上篇文章分享了简单的三层模式和基础文件夹的创建,本篇将以示例的形式详细具体的展示Router.Controller.Service.Model之间业务处理和数据传输. 1. 班级管理数据模型创建.数据 ...
- shiro 拦截时序图
shiro 集成 web 1.第一个过滤器-AbstractShiroFilter subject 是后续动作的主体. 首先构造 subject: WebSubject DefaultSecurity ...
- Hadoop支持的压缩格式对比和应用场景以及Hadoop native库
对于文件的存储.传输.磁盘IO读取等操作在使用Hadoop生态圈的存储系统时是非常常见的,而文件的大小等直接影响了这些操作的速度以及对磁盘空间的消耗. 此时,一种常用的方式就是对文件进行压缩.但文件被 ...
- 什么是Redis?
Remote Dictionary Server(Redis)是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value 数据库,并提供多种语言的API.它通常被 ...
- 死磕以太坊源码分析之MPT树-上
死磕以太坊源码分析之MPT树-上 前缀树Trie 前缀树(又称字典树),通常来说,一个前缀树是用来存储字符串的.前缀树的每一个节点代表一个字符串(前缀).每一个节点会有多个子节点,通往不同子节点的路径 ...
- TurtleBot3 Waffle (tx2版华夫)(1)笔记本上安装虚拟机、 Ubuntu 系统
1.1虚拟机的安装 1.1.1.windows7系统建议安装14.1版本 VMware workstation 百度云链接: 链接:https://pan.baidu.com/s/1q6Lh9fMuX ...