Hadoop MapReduce编程 API入门系列之二次排序(十六)
不多说,直接上代码。

-- ::, INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
-- ::, WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
-- ::, WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
-- ::, INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process :
-- ::, INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:
-- ::, INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local1173601391_0001
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local1173601391_0001
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1173601391_0001_m_000000_0
-- ::, INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
-- ::, INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@65bb90dc
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/data/secondarySort/secondarySort.txt:+
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) kvi ()
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb:
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - soft limit at
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - bufstart = ; bufvoid =
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - kvstart = ; length =
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] -
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - bufstart = ; bufend = ; bufvoid =
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - kvstart = (); kvend = (); length = /
-- ::, INFO [org.apache.hadoop.mapred.MapTask] - Finished spill
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1173601391_0001_m_000000_0 is done. And is in the process of committing
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1173601391_0001_m_000000_0' done.
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1173601391_0001_m_000000_0
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1173601391_0001_r_000000_0
-- ::, INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
-- ::, INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@59b59452
-- ::, INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@73d5cf65
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=, maxSingleShuffleLimit=, mergeThreshold=, ioSortFactor=, memToMemMergeOutputsThreshold=
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1173601391_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher# about to shuffle output of map attempt_local1173601391_0001_m_000000_0 decomp: len: to MEMORY
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read bytes from map-output for attempt_local1173601391_0001_m_000000_0
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: , inMemoryMapOutputs.size() -> , commitMemory -> , usedMemory ->
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - / copied.
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with in-memory map-outputs and on-disk map-outputs
-- ::, INFO [org.apache.hadoop.mapred.Merger] - Merging sorted segments
-- ::, INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with segments left of total size: bytes
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged segments, bytes to disk to satisfy reduce memory limit
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging files, bytes from disk
-- ::, INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging segments, bytes from memory into reduce
-- ::, INFO [org.apache.hadoop.mapred.Merger] - Merging sorted segments
-- ::, INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with segments left of total size: bytes
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - / copied.
-- ::, INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1173601391_0001_r_000000_0 is done. And is in the process of committing
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - / copied.
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1173601391_0001_r_000000_0 is allowed to commit now
-- ::, INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local1173601391_0001_r_000000_0' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/secondarySort/_temporary//task_local1173601391_0001_r_000000
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
-- ::, INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1173601391_0001_r_000000_0' done.
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1173601391_0001_r_000000_0
-- ::, INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
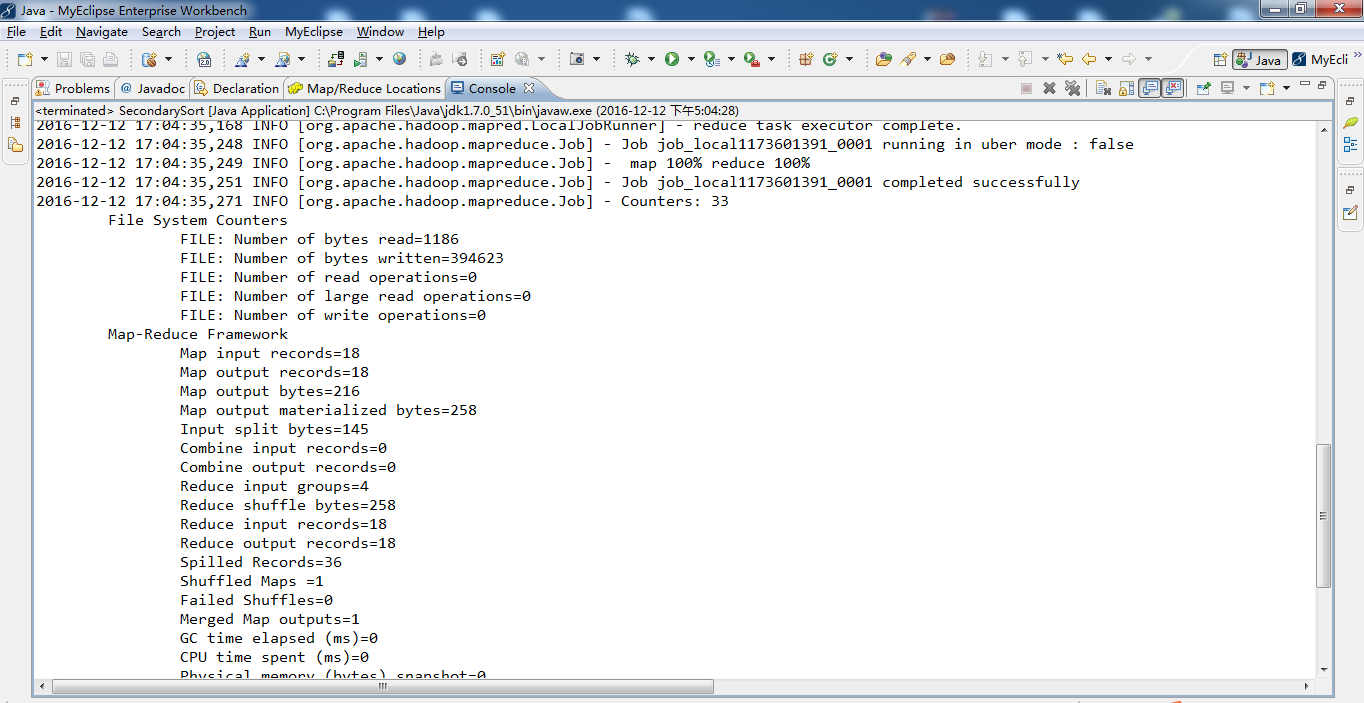
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1173601391_0001 running in uber mode : false
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - map % reduce %
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1173601391_0001 completed successfully
-- ::, INFO [org.apache.hadoop.mapreduce.Job] - Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
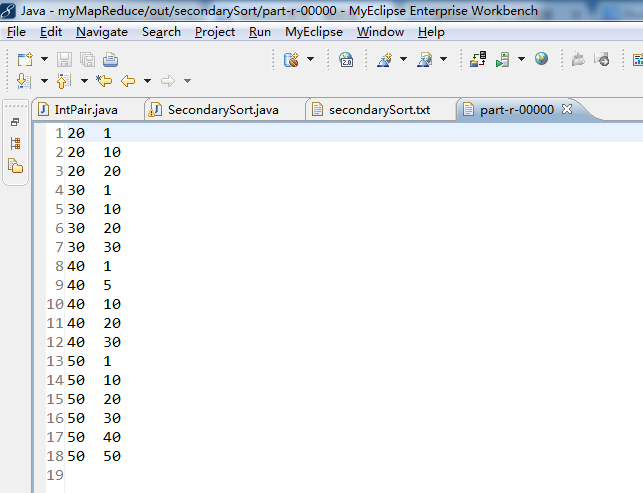
代码
IntPair.java
package zhouls.bigdata.myMapReduce.SecondarySort; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable; //第一步:自定义IntPair类,将示例数据中的key/value封装成一个整体作为Key,同时实现 WritableComparable 接口并重写其方法。
/**
* 自己定义的key类应该实现WritableComparable接口
*/
public class IntPair implements WritableComparable<IntPair>{//类似对应于如TextPair
int first;//第一个成员变量
int second;//第二个成员变量 public void set(int left, int right){//赋值
first = left;
second = right;
}
public int getFirst(){//读值
return first;
}
public int getSecond(){//读值
return second;
} //反序列化,从流中的二进制转换成IntPair
public void readFields(DataInput in) throws IOException{
first = in.readInt();
second = in.readInt();
} //序列化,将IntPair转化成使用流传送的二进制
public void write(DataOutput out) throws IOException{
out.writeInt(first);
out.writeInt(second);
} //key的比较
public int compareTo(IntPair o){
// TODO Auto-generated method stub
if (first != o.first){
return first < o.first ? - : ;
}else if (second != o.second)
{
return second < o.second ? - : ;
}else
{
return ;
}
} @Override
public int hashCode(){
return first * + second;
}
@Override
public boolean equals(Object right){
if (right == null)
return false;
if (this == right)
return true;
if (right instanceof IntPair){
IntPair r = (IntPair) right;
return r.first == first && r.second == second;
}else{
return false;
}
}
}
SecondarySort.java
package zhouls.bigdata.myMapReduce.SecondarySort; import zhouls.bigdata.myMapReduce.Join.JoinRecordAndStationName; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /*
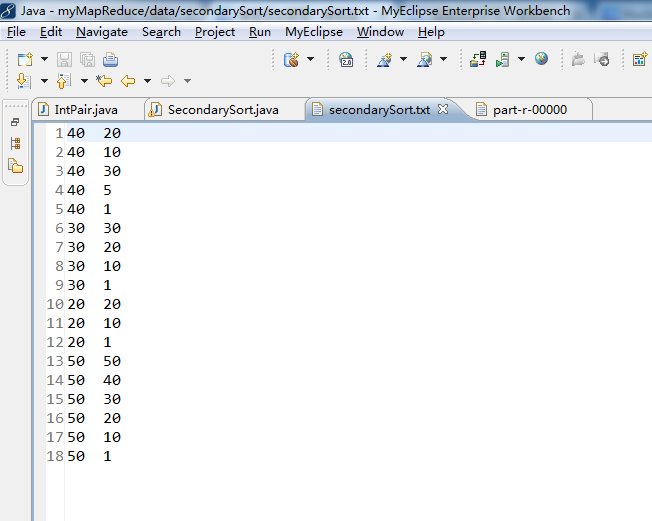
SecondarySort内容是
40 20
40 10
40 30
40 5
40 1
30 30
30 20
30 10
30 1
20 20
20 10
20 1
50 50
50 40
50 30
50 20
50 10
50 1
*/ public class SecondarySort extends Configured implements Tool{
// 自定义map
public static class Map extends Mapper<LongWritable, Text, IntPair, IntWritable>{
private final IntPair intkey = new IntPair();
private final IntWritable intvalue = new IntWritable(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
int left = ;
int right = ;
if (tokenizer.hasMoreTokens()){
left = Integer.parseInt(tokenizer.nextToken());
if (tokenizer.hasMoreTokens())
right = Integer.parseInt(tokenizer.nextToken());
intkey.set(left, right);//设为k2
intvalue.set(right);//设为v2
context.write(intkey,intvalue);//写入intkeyk2,intvalue是v2
// context.write(new IntPair(intkey),new IntWritable(intvalue));等价 }
}
} //第二步:自定义分区函数类FirstPartitioner,根据 IntPair 中的first实现分区。
/**
* 分区函数类。根据first确定Partition。
*/
public static class FirstPartitioner extends Partitioner< IntPair, IntWritable>{
@Override
public int getPartition(IntPair key, IntWritable value,int numPartitions){
return Math.abs(key.getFirst() * ) % numPartitions;
}
} //第三步:自定义 SortComparator 实现 IntPair 类中的first和second排序。本课程中没有使用这种方法,而是使用 IntPair 中的compareTo()方法实现的。
//第四步:自定义 GroupingComparator 类,实现分区内的数据分组。
/**
*继承WritableComparator
*/
public static class GroupingComparator extends WritableComparator{
protected GroupingComparator(){
super(IntPair.class, true);
}
@Override
//Compare two WritableComparables.
public int compare(WritableComparable w1, WritableComparable w2){
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
int l = ip1.getFirst();
int r = ip2.getFirst();
return l == r ? : (l < r ? - : );
}
} // 自定义reduce
public static class Reduce extends Reducer<IntPair, IntWritable, Text, IntWritable>{
private final Text left = new Text();
public void reduce(IntPair key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
left.set(Integer.toString(key.getFirst()));//设为k3
for (IntWritable val : values){
context.write(left, val);//写入left是k3,val是v3
// context.write(new Text(left),new IntWritable(val));等价
}
}
} public int run(String[] args)throws Exception{
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Path mypath=new Path(args[]);
FileSystem hdfs = mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath)){
hdfs.delete(mypath, true);
} Job job = new Job(conf, "secondarysort");
job.setJarByClass(SecondarySort.class); FileInputFormat.setInputPaths(job, new Path(args[]));//输入路径
FileOutputFormat.setOutputPath(job, new Path(args[]));//输出路径 job.setMapperClass(Map.class);// Mapper
job.setReducerClass(Reduce.class);// Reducer
//job.setNumReducerTask(3); job.setPartitionerClass(FirstPartitioner.class);// 分区函数
//job.setSortComparatorClass(KeyComparator.Class);//本课程并没有自定义SortComparator,而是使用IntPair自带的排序
job.setGroupingComparatorClass(GroupingComparator.class);// 分组函数 job.setMapOutputKeyClass(IntPair.class);
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); return job.waitForCompletion(true) ? : ;
} /**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub // String[] args0={"hdfs://HadoopMaster:9000/secondarySort/secondarySort.txt",
// "hdfs://HadoopMaster:9000/out/secondarySort"}; String[] args0={"./data/secondarySort/secondarySort.txt",
"./out/secondarySort"}; int ec =ToolRunner.run(new Configuration(),new SecondarySort(),args0);
System.exit(ec);
}
}
Hadoop MapReduce编程 API入门系列之二次排序(十六)的更多相关文章
- Hadoop MapReduce编程 API入门系列之wordcount版本2(六)
这篇博客,给大家,体会不一样的版本编程. 代码 package zhouls.bigdata.myMapReduce.wordcount4; import java.io.IOException; i ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之计数器(二十七)
不多说,直接上代码. MapReduce 计数器是什么? 计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况. Ma ...
- Hadoop MapReduce编程 API入门系列之倒排索引(二十四)
不多说,直接上代码. 2016-12-12 21:54:04,509 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JV ...
随机推荐
- 计算机图形学课件pdf版
为方便大家学习,我将自己计算机图形学的课件分享. 下载链接:http://pan.baidu.com/s/1kV5BW8n 密码:eqg4 注:本课件与教材配套PPT有所不同.教材配套PPT是编写教材 ...
- appium的等待
在自动化过程中,元素出现受网络环境,设备性能等多种因素影响.因此元素加载的时间可能不一致,从而会导致元素无法定位超时报错,但是实际上元素是正常加载了的,只是出现时间晚一点而已.那么如何解决这个问题呢? ...
- 【剑指Offer】36、两个链表的第一个公共结点
题目描述: 输入两个链表,找出它们的第一个公共结点. 解题思路: 本题首先可以很直观的想到蛮力法,即对链表1(假设长度为m)的每一个结点,遍历链表2(假设长度为n),找有没有与其相同的 ...
- [poj1325] Machine Schedule (二分图最小点覆盖)
传送门 Description As we all know, machine scheduling is a very classical problem in computer science a ...
- 爬虫数据使用MongDB保存时自动过滤重复数据
本文转载自以下网站: 爬虫断了?一招搞定 MongoDB 重复数据 https://www.makcyun.top/web_scraping_withpython13.html 需要学习的地方: Mo ...
- String去除重复字符两个方法
package cn.aresoft; import java.util.ArrayList;import java.util.List; public class TestBasic { publi ...
- 利用IO多路复用,使用linux下的EpollSelector实现并发服务器
import socket import selectors # IO多路复用选择器的模块 # 实例化一个和epoll通信的选择器 epoll_selector = selectors.EpollSe ...
- 0622通过插件的方式来热安装sphinx
1.查看当前运行的mysql版本 mysqldump --version 我的Mysql版本5.5.32 2.下载对应的mysql 5.5.32 (版本号一定不能错,要不安装不成功)源码,并解压 下载 ...
- D - Mayor's posters
D - Mayor's posters POJ - 2528 思路:线段树+离散化. 离散化时注意特殊情况,如果两个数相差大于一,离散时也应该差1.比如 1 3 离散后应该为 1 2. 错因: 1.二 ...
- TI C66x DSP 系统events及其应用 - 5.6(INTMUX)
系统event 0~127(包含了eventCombiner的输出event 0~3)与CPU支持的12个可屏蔽中断是通过INTMUX寄存器进行映射的(不包含NMI.RESET).能够选择将系统eve ...