Flink读写Redis(一)-写入Redis
项目pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jike.flink</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<flink.version>1.10.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink 11中需要手动添加
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.2</version>
</dependency>
-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
<scope>system</scope>
<systemPath>${basedir}/lib/flink-connector-redis_2.11-1.1.5.jar</systemPath>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
实现flink写入redis
实现wordcount功能,并将结果实时写入redis,这里使用了第三方依赖flink-connector-redis_2.11,该依赖提供了RedisSink可以直接使用,具体代码如下:
代码
首先定义数据源处理实现类LineSplitter,该类将一行数据分词,输出<单词,1>元祖
package com.jike.flink.examples.redis;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class LineSplitter implements FlatMapFunction<String, Tuple2<String,Integer>> {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] tokens = s.toLowerCase().split("\\W+");
for(String token : tokens){
if(token.length() > 0){
collector.collect(new Tuple2<String,Integer>(token,1));
}
}
}
}
然后定义数据写入Redis的配置类,这里面将统计后的所有信息词频写入一个哈希表,哈希表的key为"flink",作为测试使用,哈希表中每个元素key为单词,value为词频
package com.jike.flink.examples.redis;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
public class SinkRedisMapper implements RedisMapper<Tuple2<String,Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
//hset
return new RedisCommandDescription(RedisCommand.HSET,"flink");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> stringIntegerTuple2) {
return stringIntegerTuple2.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> stringIntegerTuple2) {
return stringIntegerTuple2.f1.toString();
}
}
最后编写主程序类,该类中使用了socketTextStream数据源,通过前面定义LineSplitter完成解析,然后根据单词进行分组统计,最后写入redis
package com.jike.flink.examples.redis;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
public class Sink2Redis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStreamSource = executionEnvironment.socketTextStream("实际IP",12345);
DataStream<Tuple2<String,Integer>> counts = dataStreamSource.flatMap(new LineSplitter()).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
}).sum(1);
//控制台打印
counts.print().setParallelism(1);
//定义redis服务器信息
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("redis服务器ip").setPort(redis服务端口).setPassword("redis服务密码").build();
counts.addSink(new RedisSink<>(conf,new SinkRedisMapper()));
executionEnvironment.execute();
}
}
运行效果
通过nc -l 12345,命令模拟数据源,并输入一些数据

IDEA中查看打印记录
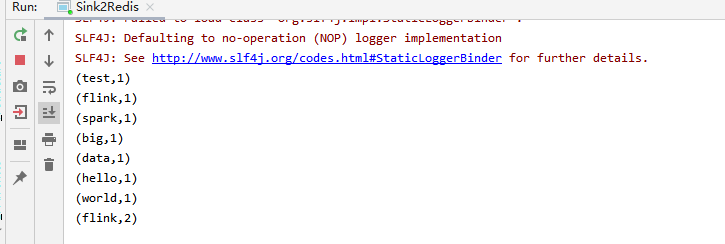
查看redis

可以发现数据已写入redis
总结
flink-connector-redis_2.11中提供了RedisSink类,该类实现了RichSinkFunction,可以直接使用,如果有特殊需求,可以自定义Sink类,继承RichSinkFunction,实现特殊处理。flink-connector-redis_2.11的源码比较简洁,下一篇打算分析学习下。
Flink读写Redis(一)-写入Redis的更多相关文章
- Flink读写Redis(三)-读取redis数据
自定义flink的RedisSource,实现从redis中读取数据,这里借鉴了flink-connector-redis_2.11的实现逻辑,实现对redis读取的逻辑封装,flink-connec ...
- Flink读写Redis(二)-flink-redis-connector代码学习
源码结构 RedisSink package org.apache.flink.streaming.connectors.redis; import org.apache.flink.configur ...
- Redis学习笔记~Redis主从服务器,读写分离
回到目录 Redis这个Nosql的存储系统一般会被部署到linux系统中,我们可以把它当成是一个数据服务器,对于并发理大时,我们会使用多台服务器充当Redis服务器,这时,各个Redis之间也是分布 ...
- redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请求,导致 redis 短时间不可用
redis 突然大量逐出导致读写请求block 内容目录: 现象 背景 原因 解决方案 ref 现象 redis作为缓存场景使用,内存耗尽时,突然出现大量的逐出,在这个逐出的过程中阻塞正常的读写请 ...
- flink04 -----1 kafkaSource 2. kafkaSource的偏移量的存储位置 3 将kafka中的数据写入redis中去 4 将kafka中的数据写入mysql中去
1. kafkaSource 见官方文档 2. kafkaSource的偏移量的存储位置 默认存在kafka的特殊topic中,但也可以设置参数让其不存在kafka的特殊topic中 3 将k ...
- 批量写入redis
批量写入redis key := GetSeriesKey(series.Id) idNames = append(idNames, key, series.Name) == { err = Mset ...
- ELKStack入门篇(三)之logstash收集日志写入redis
1.部署Redis 1.1.下载redis [root@linux-node2 ~]# wget http://download.redis.io/releases/redis-4.0.6.tar.g ...
- ELK之logstash收集日志写入redis及读取redis
logstash->redis->logstash->elasticsearch 1.安装部署redis cd /usr/local/src wget http://download ...
- Redis原子性写入HASH结构数据并设置过期时间
Redis中提供了原子性命令SETEX或SET来写入STRING类型数据并设置Key的过期时间: > SET key value EX NX ok > SETEX key value ok ...
随机推荐
- Spark SQL | 目前Spark社区最活跃的组件之一
Spark SQL是一个用来处理结构化数据的Spark组件,前身是shark,但是shark过多的依赖于hive如采用hive的语法解析器.查询优化器等,制约了Spark各个组件之间的相互集成,因此S ...
- 【C++】sort函数使用方法
一.sort函数 1.sort函数包含在头文件为#include<algorithm>的c++标准库中,调用标准库里的排序方法可以实现对数据的排序,但是sort函数是如何实现的,我们不用考 ...
- JS 数组对象
定义数组: 数组对象用来在单独的变量名中存储一系列的值. 创建一个数组有三种方法. 1: 常规方式: var myCars=new Array(); myCars[0]="Saab" ...
- 关于redis在cluster模式化下的 分布式锁的探索
背景 redis作为一个内存数据库,在分布式的服务的大环境下,占的比重越来越大啦,下面我们和大家一起探讨一下如何使用redis实现一个分布式锁 说明 一个分布式锁至少要满足下面几个条件 ...
- uni-app p-table下时间转换的问题
问题描述: 从后台获取时间戳,转成日期格式,出现NaN的问题 uni的p-table插件 解决思路
- kafka监听出现的问题,解决和剖析
问题如下: kafka为什么监听不到数据 kafka为什么会有重复数据发送 kafka数据重复如何解决 为什么kafka会出现俩个消费端都可以消费问题 kafka监听配置文件 一. 解决问题一(kaf ...
- Cys_Control(二) MButton
一.添加自定义Button 二.Xaml文件自动关联 Custom Control 取名与资源文件相同加.cs文件将自动关联 Themes文件下Generic.xaml引入该控件,用于对外公布样式 & ...
- 课堂笔记【java JDBC】
目录 JDBC简介 工作原理: 工作过程: JDBC驱动与连接 JDBC驱动 连接JDBC驱动 1.下载特定数据库的JDBCjar包 2.加载并注册数据库驱动 3.连接驱动 JDBC常见API JDB ...
- python核心高级学习总结4-------python实现进程通信
Queue的使用 Queue在数据结构中也接触过,在操作系统里面叫消息队列. 使用示例 # coding=utf-8 from multiprocessing import Queue q = Que ...
- moviepy音视频剪辑:headblur的参数r_blur卷积核以及fx、fy、r_zone的功能作用及用途
☞ ░ 前往老猿Python博文目录 ░ 在moviepy1.03版本中,headblur的调用语法为:headblurbak(clip,fx,fy,r_zone,r_blur=None) 其中参数f ...