机器学习-线性回归-损失函数+正则化regularization-06
1. 为什么要加上正则项
防止模型的过拟合 需要在损失函数LOSS(MSE或者交叉熵)再加上正则项
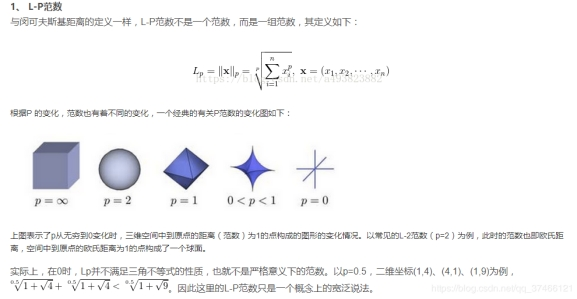
常用的惩罚项有L1正则项或者L2正则项
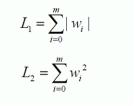
其实L1和L2正则的公式数学里面的意义就是范数,代表空间中向量到原点的距离
当我们把多元线性回归损失函数加上L2正则的时候,就诞生了Ridge岭回归。
当我们把多元线性回归损失函数加上L1正则的时候,就孕育出来了Lasso回归
其实L1和L2正则项惩罚项可以加到任何算法的损失函数上面去提高计算出来模型的泛化能力的
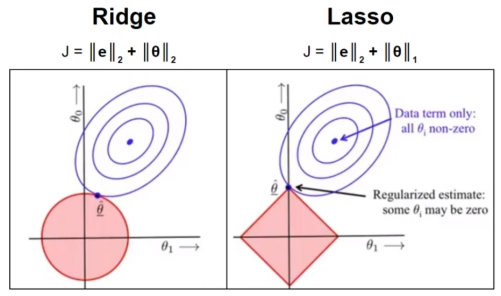
2 L1稀疏 L2平滑
L1
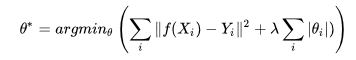
上式中λ是正则项系数,λ越大,说明我们算法工程师越看重模型的泛化能力,经验值是设置0.4
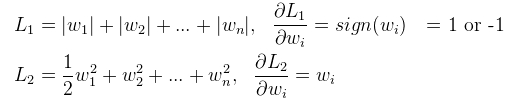
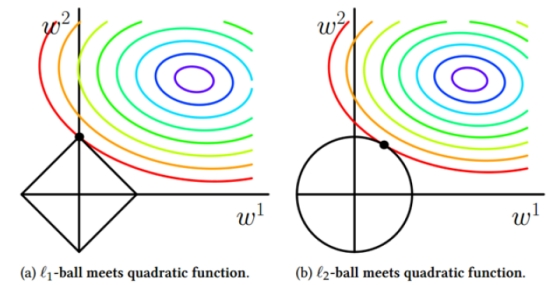
L1更容易相交于坐标轴上,而L2更容易相交于非坐标轴上。如果相交于坐标轴上,如图L1就使得是W2非0,W1是0,这个就体现出L1的稀疏性。如果没相交于坐标轴,那L2就使得W整体变小。通常我们为了去提高模型的泛化能力L1和L2都可以使用。
L1稀疏性的作用:W=0的维度 做特征选择
L1的稀疏性在做机器学习的时候,还有一个副产品就是可以帮忙去做特征的选择。
3. 代码1--L2正则
import numpy as np
from sklearn.linear_model import Ridge
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
ridge_reg = Ridge(alpha=0.4, solver="sag")
ridge_reg.fit(X, y)
print(ridge_reg.predict([[1.5]]))
print(ridge_reg.intercept_)
print(ridge_reg.coef_)
4 代码2--L2正则2
np.ravel(y) 是摊平
import numpy as np
from sklearn.linear_model import SGDRegressor
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
sgd_reg = SGDRegressor(penalty="l2", max_iter=1000)
sgd_reg.fit(X, np.ravel(y))
print(sgd_reg.predict([[1.5]]))
print(sgd_reg.intercept_)
print(sgd_reg.coef_)
5. 代码3--l1正则
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor
X = 2*np.random.rand(100, 1)
y = 4 + 3*X + np.random.randn(100, 1)
lasso_reg = Lasso(alpha=0.15, max_iter=30000)
lasso_reg.fit(X, np.ravel(y))
print(lasso_reg.predict([[1.5]]))
print(lasso_reg.intercept_)
print(lasso_reg.coef_)
sgd_reg = SGDRegressor(penalty="l1", max_iter=10000)
sgd_reg.fit(X, np.ravel(y))
print(sgd_reg.predict([[1.5]]))
print(sgd_reg.intercept_)
print(sgd_reg.coef_)
6. ElasticNet
L1 L2 正则项 都使用
import numpy as np
from sklearn.linear_model import SGDRegressor
from sklearn.linear_model import ElasticNet
X = 2*np.random.rand(100, 1)
y = 4+3*X+np.random.randn(100, 1)
elastic_net = ElasticNet(alpha=0.4, l1_ratio=0.15)
elastic_net.fit(X, np.ravel(y))
print(elastic_net.predict([[1.5]]))
sgd_reg = SGDRegressor(penalty="elasticnet", max_iter=1000)
sgd_reg.fit(X, np.ravel(y))
print(sgd_reg.predict([[1.5]]))
机器学习-线性回归-损失函数+正则化regularization-06的更多相关文章
- 机器学习入门10 - 正则化:简单性(Regularization for Simplicity)
原文链接:https://developers.google.com/machine-learning/crash-course/regularization-for-simplicity 正则化指的 ...
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 7、 正则化(Regularization)
7.1 过拟合的问题 到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fittin ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- 机器学习入门13 - 正则化:稀疏性 (Regularization for Sparsity)
原文链接:https://developers.google.com/machine-learning/crash-course/regularization-for-sparsity/ 1- L₁正 ...
- 线性回归和正则化(Regularization)
python风控建模实战lendingClub(博主录制,包含大量回归建模脚本和和正则化解释,2K超清分辨率) https://study.163.com/course/courseMain.htm? ...
- 《机器学习_01_线性模型_线性回归_正则化(Lasso,Ridge,ElasticNet)》
一.过拟合 建模的目的是让模型学习到数据的一般性规律,但有时候可能会学过头,学到一些噪声数据的特性,虽然模型可以在训练集上取得好的表现,但在测试集上结果往往会变差,这时称模型陷入了过拟合,接下来造一些 ...
- 机器学习(五)--------正则化(Regularization)
过拟合(over-fitting) 欠拟合 正好 过拟合 怎么解决 1.丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA) 2.正则化. ...
- 吴恩达-机器学习+正则化regularization
随机推荐
- c标签的使用问题
这是在使用c标签的时候遇到的问题,发现在导入包成功的情况下,jsp页面代码也没有问题.在网页上查了查,发现需要修改tomcat中的 conf/catalina.properties文件. 将tomca ...
- ubuntu安装cudnn
有些忙,这一段时间,博客就随便写写了--- 默认cuda安装好了,这里就不多说了,我们从cuda的环境变量开始说起: 配置cuda环境变量: 打开终端,输入"gedit ~/.bashrc& ...
- ACTF flutter逆向学习
参考了许多大佬的博客,在此特别诚挚感谢oacia大佬和其他大佬的博客和指导! 1.flutter和apk基础结构介绍 首先下载附件,是一个apk文件,用jadx打开 可以看见flutter字样,而fl ...
- Centos7——防火墙(Firewall)命令
centos防火墙根据系统大致有2种,一种是centos6时代的iptables:一种是centos7时代的firewalld: CentOS 7中防火墙是一个非常的强大的功能,在CentOS 6.5 ...
- Typecho 反向代理 http 访问强制启用生成 https 链接
问题描述 微酷是使用Nginx反向代理内网的Typecho站点,为了效率内网访问不需要使用https,这样Typecho接收到的请求是http协议的,于是网站内部资源链接被修改成了http. 解决方案 ...
- Spring系列:基于注解的方式构建IOC
目录 一.搭建子模块spring6-ioc-annotation 二.添加配置类 三.使用注解定义 Bean 四.@Autowired注入 五.@Resource注入 六.全部代码 从 Java 5 ...
- 分门别类输入输出,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang基本数据类型和输入输出EP03
前文再续,Go lang和Python一样,基础数据类型有着很多分类,分门别类,一应俱全.它们对应着不同的使用场景,分别是:整形.浮点.字符.字符串.布尔等等.常用的基本数据类型经常会参与日常业务逻辑 ...
- Serverless时代的微服务开发指南:华为云提出七大实践新标准
摘要:本文结合华为云在Serverless Microservice方面的实践,总结提炼出七大Serverless Microservice开发 "实践标准",为加速全域Serve ...
- Python 绑定:从 Python 调用 C 或 C++
摘要:您是拥有想要从 Python 中使用的C或 C++ 库的 Python 开发人员吗?如果是这样,那么Python 绑定允许您调用函数并将数据从 Python 传递到C或C++,让您利用这两种语言 ...
- 聊聊数仓中TPCD-DS&TPC-H与查询性能的那些事儿
摘要:详细讲述使用GaussDB(DWS)时,如何使用TPC-DS/TPC-H等标准数据模型,获取DWS的查询性能数据. 本文分享自华为云社区<GaussDB(DWS) <DWS之TPCD ...