Pandas系列(十八)- 多级索引
多级索引
多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
实质上,单级索引对应Index对象,多级索引对应MultiIndex对象。
一、Series对象的多级索引
- 多级索引Series对象的创建
import pandas as pd
import numpy as np se1=pd.Series(np.random.randn(4),index=[list("aabb"),[1,2,1,2]])
se1
Out[6]:
a 1 0.357171
2 0.084055
b 1 -0.678752
2 0.132007
dtype: float64
- 子集的选取
se1['a']
Out[7]:
1 0.357171
2 0.084055
dtype: float64
se1['a':'b']
Out[8]:
a 1 0.357171
2 0.084055
b 1 -0.678752
2 0.132007
dtype: float64
内层选取
se1[:, 1]
Out[9]:
a 0.357171
b -0.678752
dtype: float64
se1[:, 2]
Out[10]:
a 0.084055
b 0.132007
dtype: float64
二、DataFrame对象的多级索引
- 1. 创建多层行索引
- 隐式构造
import numpy as np
df = pd.DataFrame(np.random.randint(0, 150, size=(6,3)), columns=['语文', '数学', 'Python'], index=[['Michal', 'Michal', 'Kobe','Kobe', 'James', 'James'],['Mid','End', 'Mid', 'End','Mid', 'End']])
df
Out[25]:
语文 数学 Python
Michal Mid 100 43 73
End 11 18 60
Kobe Mid 104 66 54
End 30 120 134
James Mid 135 77 56
End 45 127 63
显式构造
- 使用数组
df = pd.DataFrame(np.random.randint(0, 150, size=(6,3)), columns=['语文', '数学', 'Python'], index=pd.MultiIndex.from_arrays([['Michal', 'Michal', 'Kobe','Kobe', 'James', 'James'],['Mid','End', 'Mid', 'End','Mid', 'End']]))
df
Out[27]:
语文 数学 Python
Michal Mid 56 46 104
End 83 57 95
Kobe Mid 48 94 45
End 22 99 49
James Mid 65 66 91
End 69 101 84
- 使用元组
df = pd.DataFrame(np.random.randint(0, 150, size=(6,3)), columns=['语文', '数学', 'Python'], index=pd.MultiIndex.from_tuples([('Michal','期中'), ('Michal','期末'), ('Kobe','期中'), ('Kobe','期末'), ('James','期中'), ('James','期末')]))
df
Out[29]:
语文 数学 Python
Michal 期中 10 107 48
期末 113 49 147
Kobe 期中 116 138 29
期末 7 64 53
James 期中 1 30 21
期末 70 76 108
- 使用product
df = pd.DataFrame(np.random.randint(0, 150, size=(6,3)), columns=['语文', '数学', 'Python'], index=pd.MultiIndex.from_product([['Michal','Kobe','James'],['Mid','End']]))
df
Out[31]:
语文 数学 Python
Michal Mid 85 89 17
End 21 4 23
Kobe Mid 54 117 108
End 37 20 79
James Mid 56 47 82
End 45 57 126
2. 多层列索引
df = pd.DataFrame(np.random.randint(0, 150, size=(3,6)), index=['语文', '数学', 'Python'], columns=pd.MultiIndex.from_product([['Michal','Kobe','James'],['Mid','End']]))
df
Out[34]:
Michal Kobe James
Mid End Mid End Mid End
语文 74 84 76 142 36 87
数学 44 90 57 143 78 68
Python 79 46 120 47 128 145
3. 索引赋值,设置名称和交换
df1=pd.DataFrame(np.arange(12).reshape(4,3),index=[list("AABB"),[1,2,1,2]],columns=[list("XXY"),[10,11,10]])
df1
Out[11]:
X Y
10 11 10
A 1 0 1 2
2 3 4 5
B 1 6 7 8
2 9 10 11
- 赋名
df1.columns.names=['XY','sum']
df1.index.names=['AB','num']
df1
Out[12]:
XY X Y
sum 10 11 10
AB num
A 1 0 1 2
2 3 4 5
B 1 6 7 8
2 9 10 11
- 创建MultiIndex对象再作为索引
df1.index=pd.MultiIndex.from_arrays([list("AABB"),[3,4,3,4]],names=["AB","num"])
df1
Out[13]:
XY X Y
sum 10 11 10
AB num
A 3 0 1 2
4 3 4 5
B 3 6 7 8
4 9 10 11
- 可以对各级索引进行互换
df1.swaplevel('AB','num')
Out[14]:
XY X Y
sum 10 11 10
num AB
3 A 0 1 2
4 A 3 4 5
3 B 6 7 8
4 B 9 10 11
4. 获取索引值
df = pd.DataFrame(np.random.randint(0, 150, size=(6,3)), columns=['语文', '数学', 'Python'], index=pd.MultiIndex.from_product([['Michal','Kobe','James'],['Mid','End']]))
df
Out[38]:
语文 数学 Python
Michal Mid 65 134 85
End 94 91 48
Kobe Mid 118 142 141
End 2 32 106
James Mid 29 11 127
End 16 93 99
df.index
Out[39]:
MultiIndex([('Michal', 'Mid'),
('Michal', 'End'),
( 'Kobe', 'Mid'),
( 'Kobe', 'End'),
( 'James', 'Mid'),
( 'James', 'End')],
) # loc获取
df.loc['James', :]
Out[42]:
语文 数学 Python
Mid 29 11 127
End 16 93 99
df[df.index.get_level_values(0) == 'Michal']
Out[45]:
语文 数学 Python
Michal Mid 65 134 85
End 94 91 48
df[df.index.get_level_values(1) == 'Mid']
Out[46]:
语文 数学 Python
Michal Mid 65 134 85
Kobe Mid 118 142 141
James Mid 29 11 127
df.loc[('James', 'Mid'), :]
Out[41]:
语文 29
数学 11
Python 127
Name: (James, Mid), dtype: int32
三、案例:考试数据分析

试题:
1. 计算每个学生的总成绩
2. 计算每个学生各学期的总成绩
3. 各门课程平均成绩
4. 各学期大于本课程平均成绩的学生姓名及成绩
整理数据
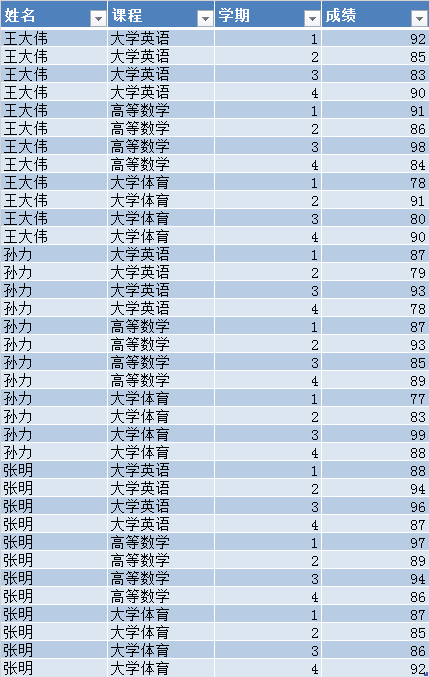
- 读取数据
import pandas as pd
exam_data = pd.read_excel('试题.xlsx', sheet_name='试题数据')
exam_data
Out[3]:
姓名 课程 学期 成绩
0 王大伟 大学英语 1 92
1 王大伟 大学英语 2 85
2 王大伟 大学英语 3 83
3 王大伟 大学英语 4 90
4 王大伟 高等数学 1 91
5 王大伟 高等数学 2 86
6 王大伟 高等数学 3 98
7 王大伟 高等数学 4 84
8 王大伟 大学体育 1 78
9 王大伟 大学体育 2 91
- 设置索引
# 读取时设置
exam_data = pd.read_excel('试题.xlsx', sheet_name='试题数据', index_col=[0, 1])
exam_data
Out[5]:
学期 成绩
姓名 课程
王大伟 大学英语 1 92
大学英语 2 85
大学英语 3 83
大学英语 4 90
高等数学 1 91
高等数学 2 86
高等数学 3 98
高等数学 4 84
大学体育 1 78
大学体育 2 91
大学体育 3 80
大学体育 4 90
孙力 大学英语 1 87
大学英语 2 79
大学英语 3 93
大学英语 4 78
高等数学 1 87
高等数学 2 93
高等数学 3 85
高等数学 4 89
大学体育 1 77
大学体育 2 83
大学体育 3 99
大学体育 4 88
张明 大学英语 1 88
大学英语 2 94
大学英语 3 96
大学英语 4 87
高等数学 1 97
高等数学 2 89
高等数学 3 94
高等数学 4 86
大学体育 1 87
大学体育 2 85
大学体育 3 86
大学体育 4 92 # 设置索引列
exam_data.set_index(keys=['姓名', '课程'])
Out[21]:
学期 成绩
姓名 课程
王大伟 大学英语 1 92
大学英语 2 85
大学英语 3 83
大学英语 4 90
高等数学 1 91
高等数学 2 86
高等数学 3 98
高等数学 4 84
大学体育 1 78
大学体育 2 91
大学体育 3 80
大学体育 4 90
孙力 大学英语 1 87
大学英语 2 79
大学英语 3 93
大学英语 4 78
高等数学 1 87
高等数学 2 93
高等数学 3 85
高等数学 4 89
大学体育 1 77
大学体育 2 83
大学体育 3 99
大学体育 4 88
张明 大学英语 1 88
大学英语 2 94
大学英语 3 96
大学英语 4 87
高等数学 1 97
高等数学 2 89
高等数学 3 94
高等数学 4 86
大学体育 1 87
大学体育 2 85
大学体育 3 86
大学体育 4 92
当然,这里我们不需要对其设置索引
- 1. 计算每个学生总成绩
exam_data = pd.read_excel('试题.xlsx', sheet_name='试题数据')
# 1. 计算每个学生总成绩
student_total_score = exam_data.groupby(by=['姓名']).agg(
{'成绩': sum}).rename(columns={'成绩': '总成绩'})
print('1. 学生总成绩:\n', student_total_score)
1. 学生总成绩:
总成绩
姓名
孙力 1038
张明 1081
王大伟 1048
- 2. 每个学生各学期的总成绩
# 2. 每个学生各学期的总成绩
student_semester_total = exam_data.groupby(by=['姓名', '学期']).agg(
{'成绩': sum}).rename({'成绩': ' 总成绩'})
print('\n2. 学生每个学期总成绩:\n', student_semester_total)
2. 学生每个学期总成绩:
成绩
姓名 学期
孙力 1 251
2 255
3 277
4 255
张明 1 272
2 268
3 276
4 265
王大伟 1 261
2 262
3 261
4 264
3. 各门课程平均成绩
# 3. 各门课程平均成绩
course_avg_score = exam_data.groupby(by=['课程'])['成绩'].mean()
print('\n3. 各门课程平均成绩:\n', course_avg_score)
3. 各门课程平均成绩:
课程
大学体育 86.333333
大学英语 87.666667
高等数学 89.916667
Name: 成绩, dtype: float64
- 4. 各学期大于本课程平均成绩的学生姓名及成绩
def judge_score(row):
return row['成绩'] > course_avg_score[row['课程']]
greater_than_avg_student = exam_data[exam_data.apply(judge_score, axis=1)].set_index(keys=['姓名', '课程'])
print('\n4. 各学期大于本课程平均成绩的学生姓名及成绩: \n', greater_than_avg_student)
4. 各学期大于本课程平均成绩的学生姓名及成绩:
学期 成绩
姓名 课程
王大伟 大学英语 1 92
大学英语 4 90
高等数学 1 91
高等数学 3 98
大学体育 2 91
大学体育 4 90
孙力 大学英语 3 93
高等数学 2 93
大学体育 3 99
大学体育 4 88
张明 大学英语 1 88
大学英语 2 94
大学英语 3 96
高等数学 1 97
高等数学 3 94
大学体育 1 87
大学体育 4 92
- 将结果输出到文件
# 输出文件
with pd.ExcelWriter(path="结果.xlsx") as writer:
exam_data.to_excel(excel_writer=writer, sheet_name='试题数据', encoding='utf-8', index=False)
student_total_score.to_excel(excel_writer=writer, sheet_name='学生总成绩', encoding='utf-8')
student_semester_total.to_excel(excel_writer=writer, sheet_name='每个学生各学期总成绩', encoding='utf-8')
course_avg_score.to_excel(excel_writer=writer, sheet_name='各门课程平均成绩', encoding='utf-8')
greater_than_avg_student.to_excel(excel_writer=writer, sheet_name='各学期大于本课程平均成绩的学生姓名及成绩', encoding='utf-8')
writer.save()
Pandas系列(十八)- 多级索引的更多相关文章
- Web 前端开发精华文章集锦(jQuery、HTML5、CSS3)【系列十八】
<Web 前端开发精华文章推荐>2013年第六期(总第十八期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各种增强网站用户体验的 jQuery 插件,展示前沿的 HTML5 和 C ...
- 为什么不建议给MySQL设置Null值?《死磕MySQL系列 十八》
大家好,我是咔咔 不期速成,日拱一卒 之前ElasticSearch系列文章中提到了如何处理空值,若为Null则会直接报错,因为在ElasticSearch中当字段值为null时.空数组.null值数 ...
- 学习ASP.NET Core Razor 编程系列十八——并发解决方案
学习ASP.NET Core Razor 编程系列目录 学习ASP.NET Core Razor 编程系列一 学习ASP.NET Core Razor 编程系列二——添加一个实体 学习ASP.NET ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- Pandas进阶之DataFrame多级索引
多级索引:在一个轴上有多个(两个以上)的索引,能够以低维度形式来表示高维度的数据.单级索引是Index对象,多级索引是MultiIndex对象. 一.创建多级索引 方法一:隐式创建,即给DataFra ...
- Pandas系列(八)-筛选工具介绍
内容目录 1. 字典式 get 访问 2. 属性访问 3. 切片操作 4. 通过数字筛选行和列 5. 通过名称筛选行和列 6. 布尔索引 7. isin 筛选 8. 通过Callable筛选 数据准备 ...
- mysql系列十、mysql索引结构的实现B+树/B-树原理
一.MySQL索引原理 1.索引背景 生活中随处可见索引的例子,如火车站的车次表.图书的目录等.它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的 ...
- Oracle索引梳理系列(八)- 索引扫描类型及分析(高效索引必备知识)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- BizTalk开发系列(十八) 使用信封拆分数据库消息
之前写了一篇的<BizTalk开发系列(十七) 信封架构(Envelop)> 是关于信封架构及其拆装原理的,都是理论性的内容.信封在BizTalk开发过程中最常用的应该是在读取SQL Se ...
- iOS开发技巧(系列十八:扩展UIColor,支持十六进制颜色设置)
新建一个Category,命名为UIColor+Hex,表示UIColor支持十六进制Hex颜色设置. UIColor+Hex.h文件, #import <UIKit/UIKit.h> # ...
随机推荐
- java多线程2:Thread中的方法
静态方法: Thread类中的静态方法表示操作的线程是"正在执行静态方法所在的代码块的线程". 为什么Thread类中要有静态方法,这样就能对CPU当前正在运行的线程进行操作.下面 ...
- typeScript基本概念
我一直认为学习是知识的累加,而前端技术也是进步的.所以学习的重点就是,'它有什么不同,它好在哪里'.这要求我们必须结合之前的经验和知识去学习一门新技术,而不是无情的复制粘贴机器. 首先,ts的官方定义 ...
- 如何基于 Docker 快速搭建 Springboot + Mysql + Redis 项目
目录 前言 项目目录 搭建项目 1. docker安装启动mysql以及redis 1.1 安装mysql 1.2 安装redis 2. 初始化数据库 3.创建项目 4.初始化代码 4.1 全局配置文 ...
- CF1440A Buy the String 题解
Content 有 \(t\) 组询问,每组询问给出一个长度为 \(n\) 的 \(0/1\) 串,你可以花 \(h\) 的代价把 \(0\) 修改成 \(1\) 或者把 \(1\) 修改成 \(0\ ...
- .NET 6 优先队列 PriorityQueue 实现分析
在最近发布的 .NET 6 中,包含了一个新的数据结构,优先队列 PriorityQueue, 实际上这个数据结构在隔壁 Java中已经存在了很多年了, 那优先队列是怎么实现的呢? 让我们来一探究竟吧 ...
- Lucene 基础类型
Lucene 索引文件中,用一下基本类型来保存信息:1. Byte:是最基本的类型,长 8 位(bit).2. UInt32:由 4 个 Byte 组成.3. UInt64:由 8 个 Byte 组成 ...
- 【LeetCode】326. Power of Three 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 循环 递归 取对数 判断是不是最大3的倍数的因子 日 ...
- 【LeetCode】213. House Robber II 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址:https://leetcode.com/problems/house-rob ...
- 【LeetCode】275. H-Index II 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/h-index- ...
- window11连接局域网共享失败处理办法
第一步1.按 Win + R 组合键,打开运行,并输入:gpedit.msc 命令,确定或回车,可以快速打开本地组策略编辑器2.本地组策略编辑器窗口中,依次展开到:计算机配置 - 管理模板 - 网络 ...