centos7搭建kafka集群-第一篇
Kafka初识
1、Kafka使用背景
- 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位
- 我想对用户的搜索关键词进行统计,分析出当前的流行趋势
- 有些数据,存储数据库浪费,直接存储硬盘效率又低
Kafka相关概念
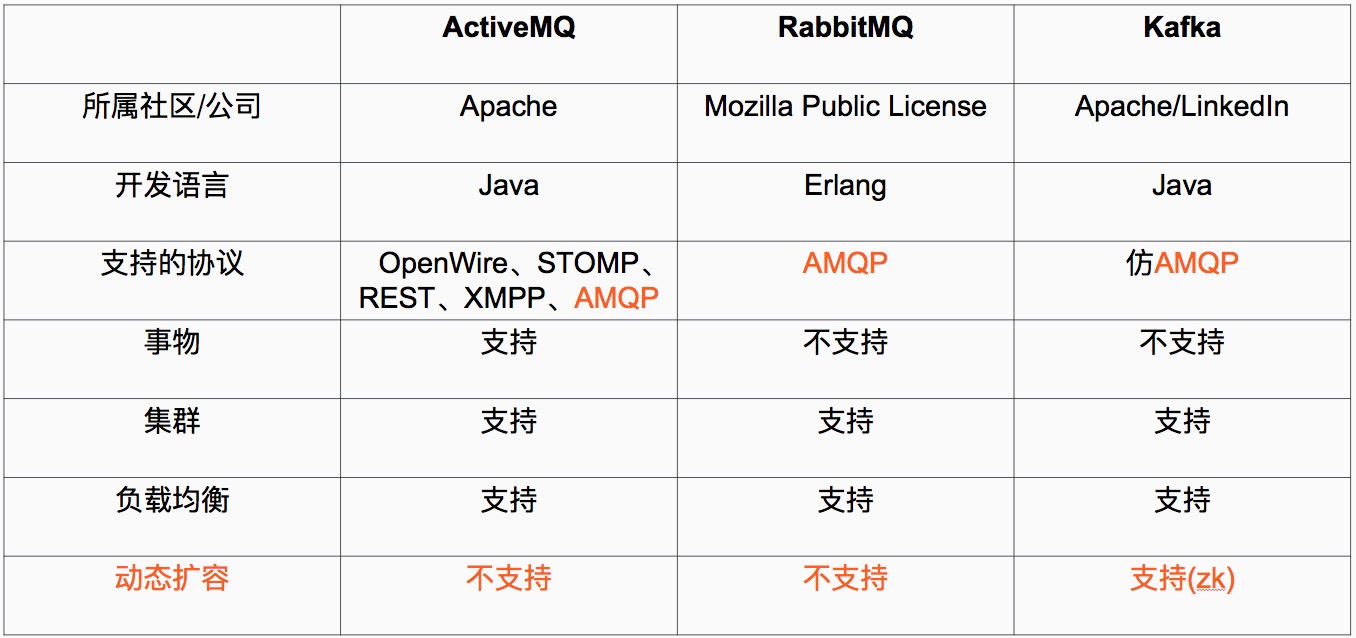
1、 AMQP协议
centos7搭建kafka集群-第一篇的更多相关文章
- centos7搭建kafka集群-第二篇
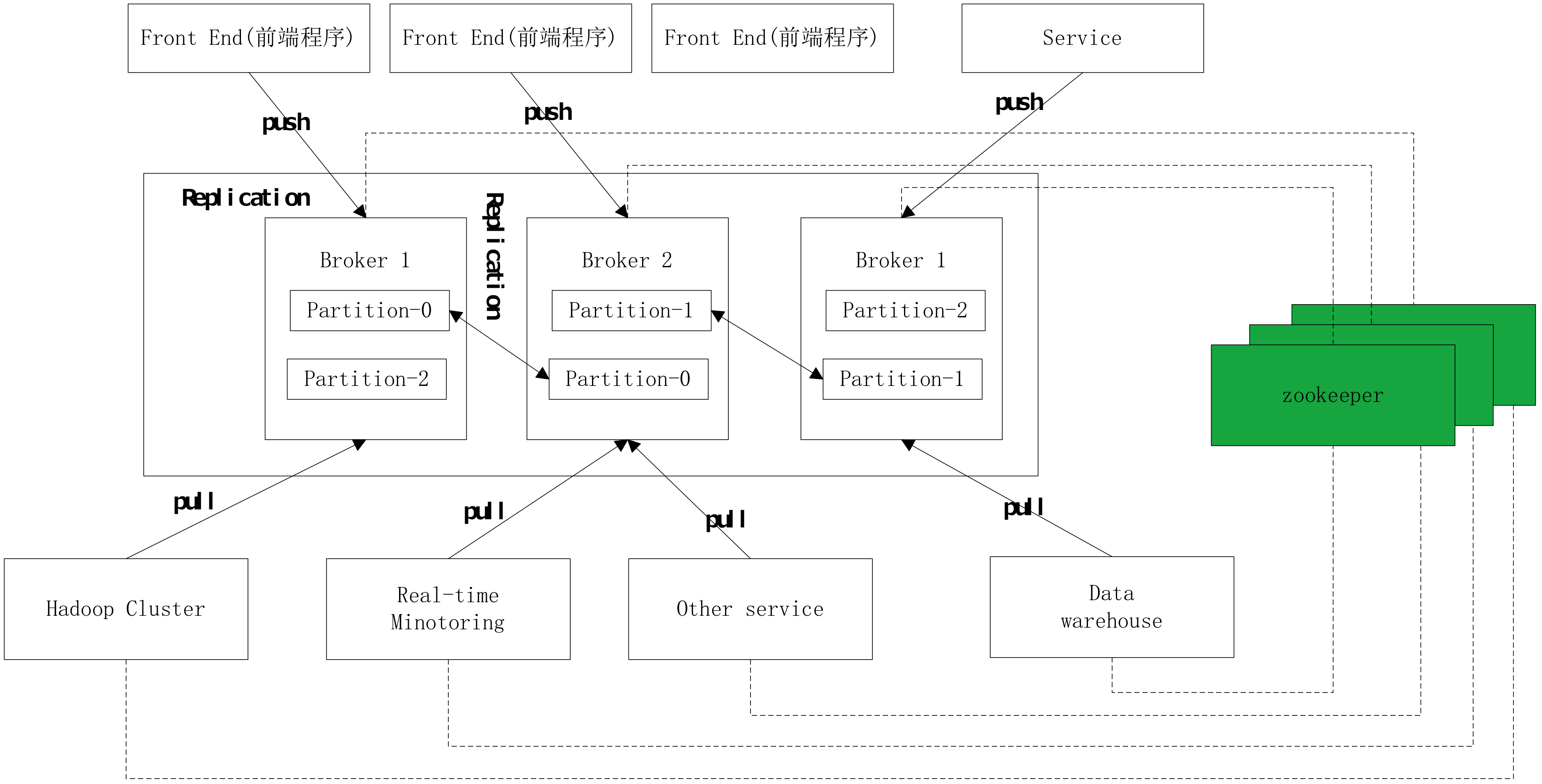
好了,本篇开始部署kafka集群 Zookeeper集群搭建 注:Kafka集群是把状态保存在Zookeeper中的,首先要搭建Zookeeper集群(也可以用kafka自带的ZK,但不推荐) 1.软 ...
- centos7搭建kafka集群
一.安装jdk 1.下载jdk压缩包并移动到/usr/local目录 mv jdk-8u162-linux-x64.tar.gz /usr/local 2.解压 tar -zxvf jdk-8u162 ...
- 利用新版本自带的Zookeeper搭建kafka集群
安装简要说明新版本的kafka自带有zookeeper,其实自带的zookeeper完全够用,本篇文章以记录使用自带zookeeper搭建kafka集群.1.关于kafka下载kafka下载页面:ht ...
- Kafka集群优化篇-调整broker的堆内存(heap)案例实操
Kafka集群优化篇-调整broker的堆内存(heap)案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看kafka集群的broker的堆内存使用情况 1>. ...
- Kafka学习之(六)搭建kafka集群
想要搭建kafka集群,必须具备zookeeper集群,关于zookeeper集群的搭建,在Kafka学习之(五)搭建kafka集群之Zookeeper集群搭建博客有说明.需要具备两台以上装有zook ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- 什么是kafka以及如何搭建kafka集群?
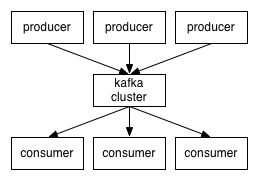
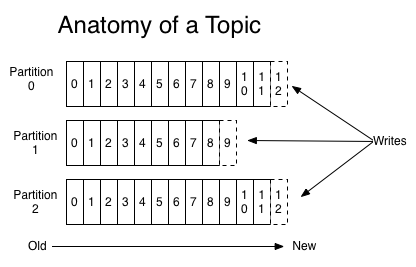
一.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. Kafka场景比喻 接下来我大概比喻下Kafka的使用场景 消息中间件:生产者和消费者 妈妈:生产 ...
- Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装
Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装 集群规划: hostname Zookeeper Kafka kafka-eagle kafka01 √ √ √ kaf ...
- docker-compose 搭建kafka集群
docker-compose搭建kafka集群 下载镜像 1.wurstmeister/zookeeper 2.wurstmeister/kafka 3.sheepkiller/kafka-manag ...
随机推荐
- servlet填充Response时,数据转换之content-type
在Http请求中,我们每天都在使用Content-type来指定不同格式的请求信息,但是却很少有人去全面了解content-type中允许的值有多少,这里将讲解Content-Type的可用值. 1. ...
- MYSQL 问题小总结
mysql 问题小总结 1.MySQL远程连接ERROR 2003(HY000):Can't connect to MySQL server on ‘ip’(111)的问题 通常是mysql配置文件中 ...
- css样式记忆
text-indent: 2em; //开头空两格: display : none; //隐藏元素 background:#CCC; //背景颜色 background: url(imag ...
- idea中实体类序列化后生成序列化版本ID的方法
为什么要添加序列化版本ID了(serialVersionUID)? 通过判断实体类的serialVersionUID来验证版本一致性的.在进行反序列化时,JVM会把传来的字节流中的serialVers ...
- 2018.09.11 bzoj3629: [JLOI2014]聪明的燕姿(搜索)
传送门 一道神奇的搜索. 直接枚举每个质因数的次数,然后搜索就行了. 显然质因数k次数不超过logkn" role="presentation" style=" ...
- 字典树Java实现
Trie树的原理 Trie树也称字典树,因为其效率很高,所以在在字符串查找.前缀匹配等中应用很广泛,其高效率是以空间为代价的. 利用串构建一个字典树,这个字典树保存了串的公共前缀信息,因此可以降低查询 ...
- html自适应布局,@media screen,媒体查询
html自适应布局,@media screen,媒体查询 自适应代码示例: <!doctype html> <html> <head> <meta chars ...
- spring boot打包后windows启动乱码
事情的起因什么的就不多表了,直接进入主题... 项目都要上线了,结果发现使用 idea mvn install之后的 jar在windows下启动乱码,而使用idea启动却没有问题!!! 这是神马情况 ...
- (转)C#静态方法使用经验浅谈
转自:http://developer.51cto.com/art/200908/147734.htm C#静态方法有什么弊端? 我们在实际的开发过程中会注意到C#静态方法对于我们程序的影响,那么有哪 ...
- hdu 4972 根据每轮篮球赛分差求结果
http://acm.hdu.edu.cn/showproblem.php?pid=4972 两支球队进行篮球比赛,每进一次球后更新比分牌,比分牌的计数方法是记录两队比分差的绝对值,每次进球的分可能是 ...