python抓取今日头条
# 直接上代码,抓取关键词搜索结果的json数据
# coding:utf-8
import requests
import json url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E5%B0%8F%E5%BA%B7%E7%A4%BE%E4%BC%9A&autoload=true&count=20&cur_tab=1'
wbdata = requests.get(url).text data = json.loads(wbdata)
news = data['data'] for n in news:
if 'title' in n:
title = n['title']
source = n['source']
url = n['article_url']
keyword = n['keywords']
print(title,url,keyword,source)
github: https://github.com/haibincoder/ToutiaoCrawler
1.浏览器中找到内容的接口,Network --> XHR是动态加载的,如果没有内容的话刷新当前页面,我们这里可以看到data节点下面有需要的数据。
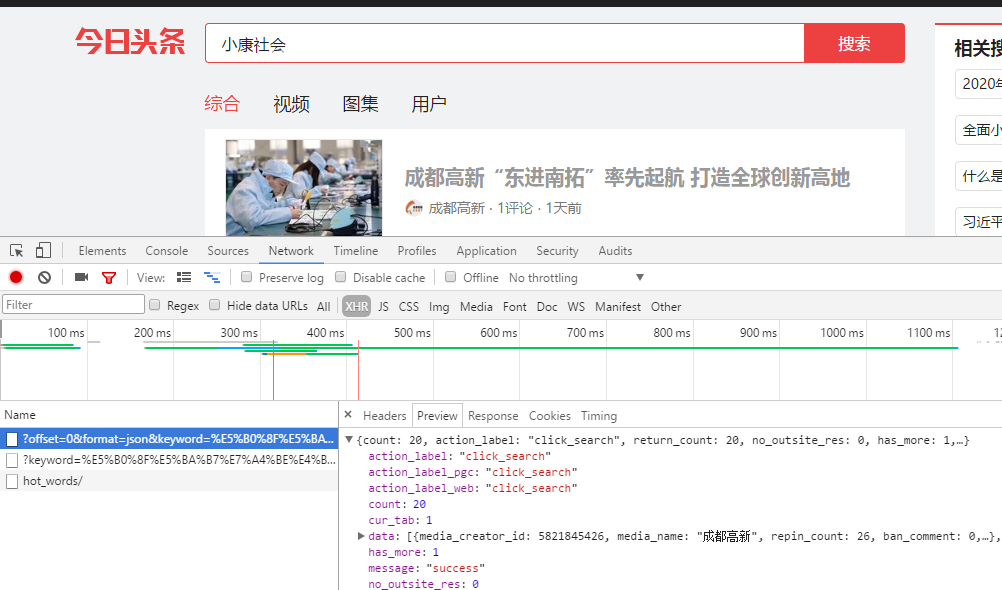
2.找到需要的内容和url

3.返回结果

另外可以爬取关键词搜索结果,keyword就是一个数组,可以自己定义。
def keyword_search(keyword):
url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword= ' + keyword + '&autoload=true&count=200&cur_tab=1' toutiao_data = requests.get(url).text data = json.loads(toutiao_data)
items = data['data'] news_list = []
link_head = 'http://toutiao.com' for n in items:
if 'title' in n:
news = News()
news.title = n['title']
news.tag = n['tag']
news.source = n['source']
news.source_url = link_head + n['source_url']
# 两会关键词
news.keyword = keyword
# 今日头条自带关键词
news.keywords = n['keywords'] news_list.append(news)
#print(news.title, news.source_url, news.source, news.keyword, news.keywords) return news_list
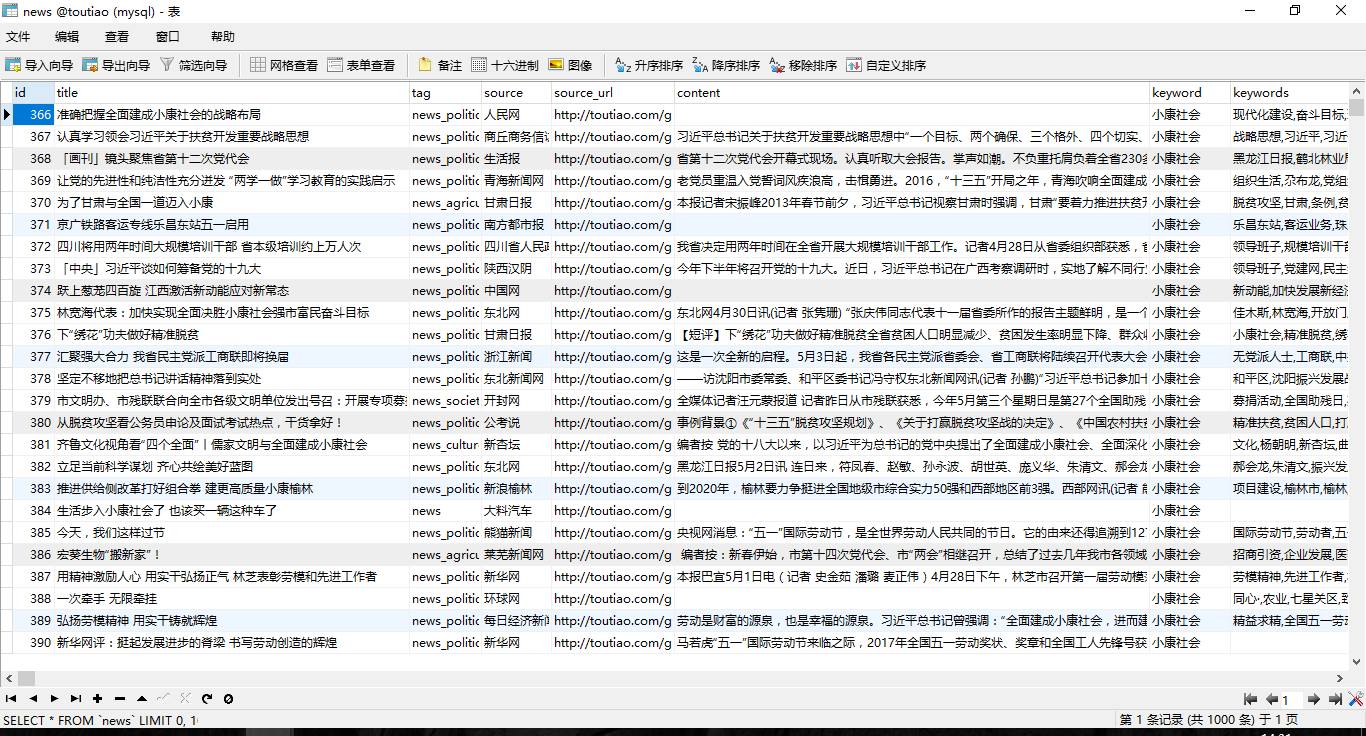
爬取结果,其中Content另外写了一个爬虫,第二个爬虫就是读取source_url,然后抓取正文
python抓取今日头条的更多相关文章
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- Python爬取今日头条段子
刚入门Python爬虫,试了下爬取今日头条官网中的段子,网址为https://www.toutiao.com/ch/essay_joke/源码比较简陋,如下: import requests impo ...
- Python爬虫学习==>第十一章:分析Ajax请求-抓取今日头条信息
学习目的: 解决AJAX请求的爬虫,网页解析库的学习,MongoDB的简单应用 正式步骤 Step1:流程分析 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果: ...
- python学习(26)分析ajax请求抓取今日头条cosplay小姐姐图片
分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片.这里分析ajax请求,获取cosplay美女图片. 登陆今日头条,点击搜索,输入cosplay 下面查看浏览 ...
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
随机推荐
- 基于key/value+Hadoop HDFS 设计的存储系统的shell命令接口
对于hadoop HDFS 中的全部命令进行解析(当中操作流程是自己的想法有不允许见欢迎大家指正) 接口名称 功能 操作流程 get 将文件拷贝到本地文件系统 . 假设指定了多个源文件,本地目的端必须 ...
- memcache 与 redis 为web app 带来的性能提升
memcache 与 redis 为web app 带来的性能提升 参考: 1. http://www.cnblogs.com/ToDoToTry/p/3513688.html
- java 执行mysql 8.0.11存储过程报错The user specified as a definer ('root'@'10.%.%.%') does not exist解决办法
执行存储过程,报错 java.sql.SQLException: The user specified as a definer ('root'@'10.%.%.%') does not exist ...
- php分享二十:mysql优化
1:垂直分割 示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段.那么,为什么不把他放到另外一张表中呢 ...
- linux分享二:Linux如何修改字符集
问题: 当在项目中用到服务器端导出并且查询条件中包含汉字时,总是导出失败,Excel中出现null字样,如何解决方法呢? 解决方法: 把linux的字符集改变一下. 路径:etc/sysconfig/ ...
- SpringBoot不使用模板引擎直接返回html
一.在resource目录下面建立文件夹,里面方静态页面. 路径:src\main\resources\static\page\index.html 访问:http://localhost:8080/ ...
- docker容器网络通信原理分析
概述 自从docker容器出现以来,容器的网络通信就一直是大家关注的焦点,也是生产环境的迫切需求.而容器的网络通信又可以分为两大方面:单主机容器上的相互通信和跨主机的容器相互通信.而本文将分别针对这两 ...
- grub配置指南
GRUB(统一引导装入器)是基本的Linux引导装入器.其有四个作用,如下:1.选择操作系统(如果计算机上安装了多个操作系统).2.表示相应引导文件所在的分区.3.找到内核.4.运行初始内存盘,设置内 ...
- 设计模式-建造者模式(Builder Pattern)
建造者模式(Builder Pattern):将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示. 建造者模式要求建造过程中是稳定的. Android 用到的 Builder 模 ...
- c++中c_str()用法
string c="abc123"; ]; strcpy(d,c.c_str()); cout<<"c:"<<c<<endl ...