[Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一、介绍
本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息。
给定关键字:视频;融合;电视
二、网站信息
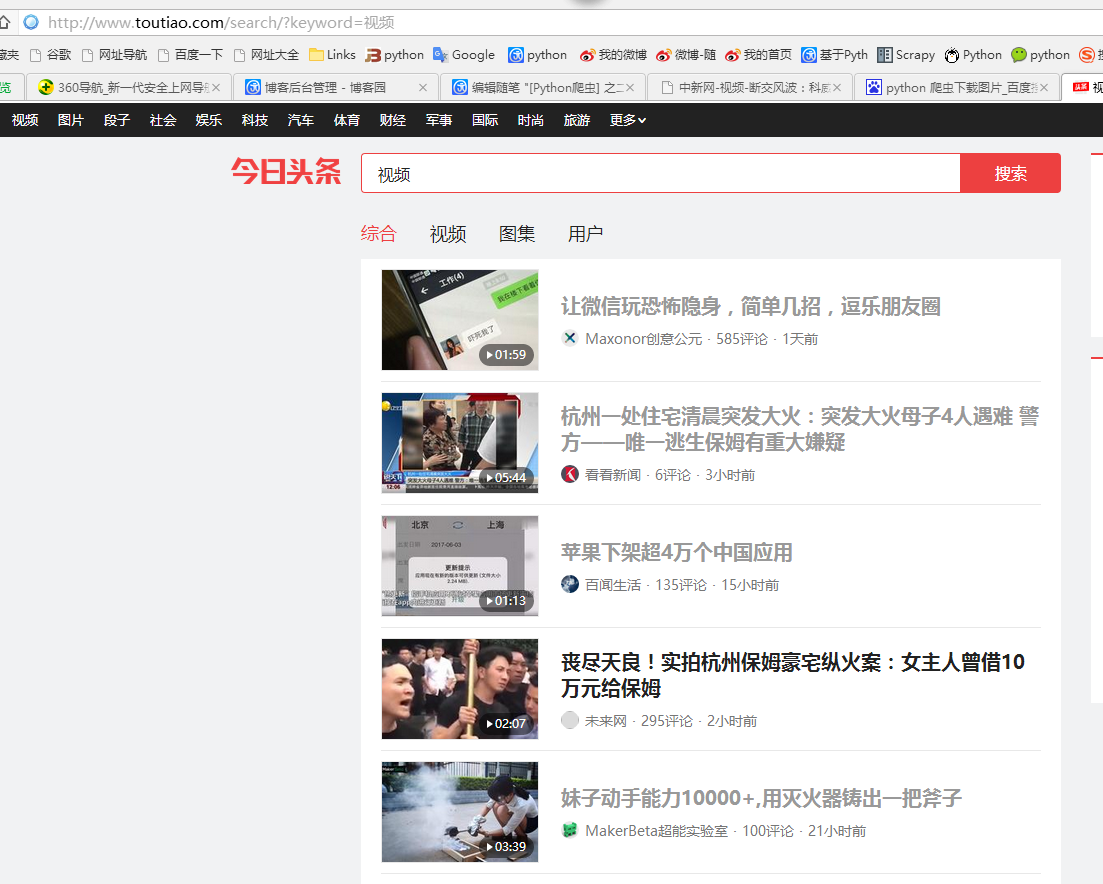
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取视频信息列表
抓取代码:Elements = doc('div[class="articleCard"]')
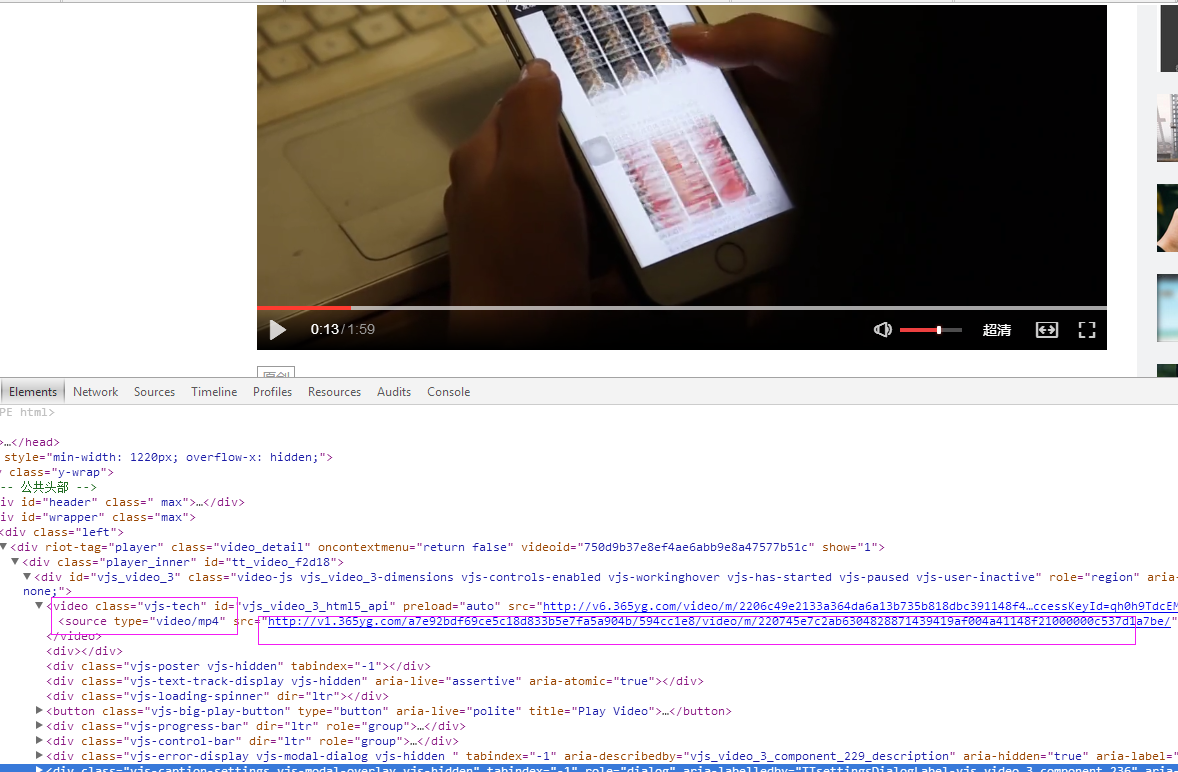
2、抓取图片
视频url:url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href')
videourl = dochtml('video[class="vjs-tech"]').find('source').attr('src')
四、完整代码
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
from datetime import datetime
import IniFile
# from threading import Thread
from pyquery import PyQuery as pq
import LogFile
import mongoDB
import urllib
class toutiaoSpider(object):
def __init__(self): logfile = os.path.join(os.path.dirname(os.getcwd()), time.strftime('%Y-%m-%d') + '.txt')
self.log = LogFile.LogFile(logfile)
configfile = os.path.join(os.path.dirname(os.getcwd()), 'setting.conf')
cf = IniFile.ConfigFile(configfile)
webSearchUrl = cf.GetValue("toutiao", "webSearchUrl")
self.keyword_list = cf.GetValue("section", "information_keywords").split(';')
self.db = mongoDB.mongoDbBase()
self.start_urls = [] for word in self.keyword_list:
self.start_urls.append(webSearchUrl + urllib.quote(word)) self.driver = webdriver.PhantomJS()
self.wait = ui.WebDriverWait(self.driver, 2)
self.driver.maximize_window() def down_video(self, videourl):
"""
下载视频到本地
:param videourl: 视频url
"""
# http://img.tvhomeimg.com/uploads/2017/06/23/144910c41de4781ccfe9435e736ef72b.jpg
if len(videourl) > 0:
fileName = ''
if videourl.rfind('/') > 0:
fileName = time.strftime('%Y%m%d%H%M%S') + '.mp4'
u = urllib.urlopen(videourl)
data = u.read() strpath = os.path.join(os.path.dirname(os.getcwd()), 'video')
with open(os.path.join(strpath, fileName), 'wb') as f:
f.write(data) def scrapy_date(self):
strsplit = '------------------------------------------------------------------------------------'
index = 0
for link in self.start_urls:
self.driver.get(link) keyword = self.keyword_list[index]
index = index + 1
time.sleep(1) #数据比较多,延迟下,否则会出现查不到数据的情况 selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = []
self.log.WriteLog(strsplit)
self.log_print(strsplit) Elements = doc('div[class="articleCard"]') for element in Elements.items():
url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href')
infoList.append(url)
if len(infoList)>0:
for url in infoList:
self.driver.get(url)
htext = self.driver.execute_script("return document.documentElement.outerHTML")
dochtml = pq(htext)
videourl = dochtml('video[class="vjs-tech"]').find('source').attr('src')
if videourl:
self.down_video(videourl) self.driver.close()
self.driver.quit() obj = toutiaoSpider()
obj.scrapy_date()
[Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频的更多相关文章
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
一.介绍 本例子用Selenium +phantomjs爬取界面(https://a.jiemian.com/index.php?m=search&a=index&type=news& ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
随机推荐
- Codeforces 362E Petya and Pipes 费用流建图
题意: 给一个网络中某些边增加容量,增加的总和最大为K,使得最大流最大. 费用流:在某条边增加单位流量的费用. 那么就可以2个点之间建2条边,第一条给定边(u,v,x,0)这条边费用为0 同时另一条边 ...
- 修改ueditor CSS
- 手机端图片插件可缩放 旋转 全屏查看photoswipe
官方介绍PhotoSwipe 是专为移动触摸设备设计的相册/画廊.兼容所有iPhone.iPad.黑莓6+,以及桌面浏览器.底层实现基于HTML/CSS/JavaScript,是一款免费开源的相册产品 ...
- python多线程实现多任务
#转载请联系 1.什么是线程? 进程是操作系统分配程序执行资源的单位,而线程是进程的一个实体,是CPU调度和分配的单位.一个进程肯定有一个主线程,我们可以在一个进程里创建多个线程来实现多任务. --- ...
- python tips:列表推导
看一个代码: a=[1,2,3,4,5,6,7,8,9] b=[5 if (i >3) else 1 for i in a] print(b) 这就是列表推导. 列表推导一般用在通过一个list ...
- Ubuntu-16.04安装Xdebug-2.2.5及相关介绍
Xdebug是一个开放源代码的PHP程序调试器(即一个Debug工具),可以用来跟踪,调试和分析PHP程序的运行状况.在日常开发中,我们会使用如 print_r() var_dump()等函数来进行调 ...
- javascript面试题(一)(转载)
1,判断字符串是否是这样组成的,第一个必须是字母,后面可以是字母.数字.下划线,总长度为5-20 var reg = /^[a-zA-Z][a-zA-Z_0-9]{4,19}$/; /*注意:1.要用 ...
- Redis 源码走读(二)对象系统
Redis设计了多种数据结构,并以此为基础构建了多种对象,每种对象(除了新出的 stream 以外)都有超过一种的实现. redisObject 这个结构体反应了 Redis 对象的内存布局 type ...
- 线段树 (区间合并)【p2894】[USACO08FEB]酒店Hotel
Descripion 奶牛们最近的旅游计划,是到苏必利尔湖畔,享受那里的湖光山色,以及明媚的阳光.作为整个旅游的策划者和负责人,贝茜选择在湖边的一家著名的旅馆住宿.这个巨大的旅馆一共有N (1 < ...
- Ubuntu开机启动的方式
方法一:--------------------------------------------------1. 在/etc/init.d/下放置启动脚本,比如postgresqlroot@ubunt ...