浅谈KMP算法
一、介绍
烤馍片KMP算法是用来处理字符串匹配问题的。比如说给你两个字符串A,B,问B是不是A的子串?
比如,eg就是aeggx的子串
一般讲字符串A称为主串,用来匹配的B串称为模式串
定义n为字符串A的长度,m为字符串B的长度(m≤n)
如果用暴力枚举法,时间复杂度为O(NM)
而KMP算法的时间复杂度在最坏的情况下为O(N),十分搞笑高效

↑如果看到这张图饿了,去吃饭,吃完饭再来学KMP
二、烤馍片的流程
step1:把馍片做出来(要想烤馍片,首先得有馍片可以烤)
假设A=“xzxzxqxzxzq”,B=“xzxqxz”,一起来看看这两个馍片字符串如何匹配

step2:烤箱预热,馍片上撒调料
这两个馍片字符串都有各自的调料。A的调料指针是i,B的调料指针是j。

step3:扔到烤箱里,烤!
在高温的作用下,烤箱里发生了微妙的反应,两块馍片也慢慢烤熟,香气充盈……
现在开始烤馍片匹配字符串
假设现在A[i-j+1…i]和B[1…j]两个馍片已经烤熟了两个长度均为j的字符串完全匹配了
很容易想到,下面一步要继续匹配A[i+1]和B[j+1]
当A[i+1]=B[j+1](相同)时,i和j均加一并继续烤重复以上步骤
当A[i+1]≠B[j+1](不相同)时
KMP算法的策略是减小j的值使得A[i-j+1…i]和B[1…j]依然匹配并继续尝试A[i+1]和B[j+1]的值
以样例为例:
i = 1 2 3 4 5 6 7 8 9 10 11
A= x z x z x q x z x z q
B= x z x q x z
j= 1 2 3 4 5 6
从头烤匹配,i=j=2时都没问题
当i=j=3时,A[i+1]='z',B[j+1]='q',A[i+1]≠B[j+1]
那么我们就要减小j值不然就烤糊了
设j减小后变为k
那么k应该是多少呢
由于当前的字符串是已经烤好了的已匹配的,所以k值要尽可能的大,这样馍片就会更好吃匹配的就会尽可能长。
此外,新的k值还要保证B[1…j]中的头k个字符和后k个字符相同
个人认为这里比较难理解,结合图像来看:
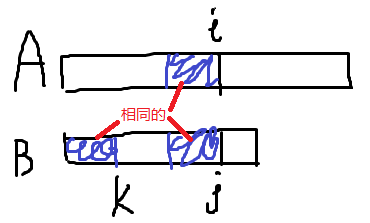
如图,A和B分别以i,j结尾的一段是匹配的,为了可以继续烤匹配,B[1…k]和A[i-k+1…i]也要是匹配的(这样才可以继续匹配A[i+1]和B[k+1]),因此,B[1…j]的开头k个字符和末尾k个字符必须要匹配。
于是图就变成了这样:
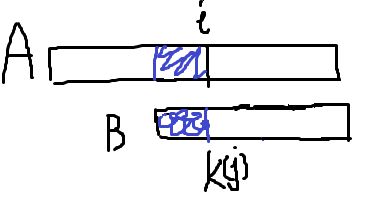
以样例为例,B[1…3]=xzx,开头一个和最后一个字符都是x,恰巧A[4]=B[2],所以j的值变为1,然后就可以继续烤匹配了
i = 1 2 3 4 5 6 7 8 9 10 11
A= x z x z x q x z x z q
B= x z x q x z
j= 1 2 3 4 5
注意:有的时候直到j=0都无法匹配,这时需要增加i并忽略j,直到A[i]=B[1]为止。
从样例可以看出,k的值与i无关,只与j有关,且每个j值仅对应一个k值。因此,我们可以开一个数组提前将每个j对应的k值存起来,这就是KMP算法中的nxt数组(由于C++中变量名叫next有一些问题。所以通常叫nxt)。nxt[j]表示当匹配到B数组第j个字母而第j+1个字母不能匹配时,k值最大是多少。记住,k值应满足B[1…k]=B[j-k+1…j]且尽可能大(k<j)。
然后,就可以继续烤匹配了。

step4:出炉
当馍片烤好了,就可以出炉了
当j=m时,就匹配完成了
此时依题目要求而定
若题目只要回答B是不是A的子串,输出,结束
若题目要寻找B作为子串出现的次数,则继续寻找

↑香香的烤面筋馍片
下面是代码实现
匹配,输出位置:
//这里数组从1开始
j=;
for(i=;i<n;i++)
{
while(j> && a[i+]!=b[j+]) j=nxt[j];//j未减小到0且不能继续匹配,减小j的值
if(a[i+]==b[j+]) j++;//能继续匹配,j的值增加
//若j==0仍不能匹配,由于循环i的值会自动增加
if(j==m)//找到一处匹配
{
printf("%d\n",i+-m+);//输出子串在主串中的位置
j=nxt[j];//继续匹配
}
}
这是代码1
如果若干子串在主串中的位置不能重复,只需将j=nxt[j]改成j=0即可:
//这里数组从1开始
j=;
for(i=;i<n;i++)
{
while(j> && a[i+]!=b[j+]) j=nxt[j];//j未减小到0且不能继续匹配,减小j的值
if(a[i+]==b[j+]) j++;//能继续匹配,j的值增加
//若j==0仍不能匹配,由于循环i的值会自动增加
if(j==m)//找到一处匹配
{
printf("%d\n",i+-m+);//输出子串在主串中的位置
j=;//从头开始匹配,保证不重复
}
}
这是代码2
预处理nxt数组:
//这里数组从1开始
p[]=j=;
for(i=;i<m;i++)
{
while(j> && b[i+]!=b[j+]) j=nxt[j];//j未减小到0且不能继续匹配,退一步
if(b[i+]==b[j+]) j++;//能继续匹配,j的值增加
//若j==0仍不能匹配,由于循环i的值会自动增加
nxt[i+]=j;//nxt数组赋值
}
这是代码3
有没有觉得预处理和匹配的代码很像?因为预处理的过程其实就是B串一个“自我匹配”的过程。预处理和烤的都是馍片能不像吗
于是美味的馍片就烤好了

一不小心好像烤糊了
推荐例题の传送门:
洛谷P4391 [BOI2009]Radio Transmission 无线传输
本文部分图片来源于网络
部分内容参考《信息学奥赛一本通.提高篇》第二部分第二章 KMP算法
若需转载,请注明https://www.cnblogs.com/llllllpppppp/p/9371218.html
~祝大家编程顺利~
浅谈KMP算法的更多相关文章
- 浅谈KMP算法及其next[]数组
KMP算法是众多优秀的模式串匹配算法中较早诞生的一个,也是相对最为人所知的一个. 算法实现简单,运行效率高,时间复杂度为O(n+m)(n和m分别为目标串和模式串的长度) 当字符串长度和字符集大小的比值 ...
- 单模式串匹配----浅谈kmp算法
模式串匹配,顾名思义,就是看一个串是否在另一个串中出现,出现了几次,在哪个位置出现: p.s. 模式串是前者,并且,我们称后一个 (也就是被匹配的串)为文本串: 在这篇博客的代码里,s1均为文本串, ...
- 【字符串算法3】浅谈KMP算法
[字符串算法1] 字符串Hash(优雅的暴力) [字符串算法2]Manacher算法 [字符串算法3]KMP算法 这里将讲述 [字符串算法3]KMP算法 Part1 理解KMP的精髓和思想 其实KM ...
- 【文文殿下】浅谈KMP算法next数组与循环节的关系
KMP算法 KMP算法是一种字符串匹配算法,他可以在O(n+m)的时间内求出一个模式串在另一个模式串下出现的次数. KMP算法是利用next数组进行自匹配,然后来进行匹配的. Next数组 Next数 ...
- 浅谈KMP算法——Chemist
很久以前就学过KMP,不过一直没有深入理解只是背代码,今天总结一下KMP算法来加深印象. 一.KMP算法介绍 KMP解决的问题:给你两个字符串A和B(|A|=n,|B|=m,n>m),询问一个字 ...
- 浅谈 KMP 算法
最近在复习数据结构,学到了 KMP 算法这一章,似乎又迷糊了,记得第一次学习这个算法时,老师在课堂上讲得唾沫横飞,十分有激情,而我们在下面听得一脸懵比,啥?这是个啥算法?啥玩意?再去看看书,完全听不懂 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
随机推荐
- Leaflet API翻译
转自: http://jsrookie.iteye.com/blog/2318972(上) http://jsrookie.iteye.com/blog/2318973(下) L.Map API各种类 ...
- jxl和POI的区别
最近两个项目中分别用到jxl和POI,因为用的都是其中的简单的功能,所以没有觉得这其中有太大的区别.有人针对他们做了比较,这里也拿出来展示一下. 首先从优缺点上来说 一.jxl 优点: Jxl对中文支 ...
- 3. CMake 系列 - 分模块编译&安装项目
目录 1. 项目目录结构 2. 相关代码 2.1 add 模块 2.2 sub 模块 2.3 测试模块 2.4 顶层 CMakeLists.txt 3. 编译 & 安装 4. 项目安装基本语法 ...
- [UFLDL] Basic Concept
博客内容取材于:http://www.cnblogs.com/tornadomeet/archive/2012/06/24/2560261.html 参考资料: UFLDL wiki UFLDL St ...
- [IR] Open Source Search Engines
From:http://blog.csdn.net/xum2008/article/details/8740063 本文档是对现有的开源的搜索引擎的一个简单介绍 1. Lucene Lucene ...
- 14桥接模式Bridge
一.什么是桥接模式 Bridge 模式又叫做桥接模式,是构造型的设 计模式之一.Bridge模式基于类的最小设计原则,通过 使用封装,聚合以及继承等行为来让不同的类承担不同 的责任.它的主要特点是把抽 ...
- BackgroundWorker学习笔记
1 简介 BackgroundWorker 类允许您在单独的专用线程上运行操作. 耗时的操作(如下载和数据库事务)在长时间运行时可能会导致用户界面 (UI) 似乎处于停止响应状态. 如果您需要能进行响 ...
- ElasticSearch6(三)-- Java API实现简单的增删改查
基于ElasticSearch6.2.4, Java API创建索引.查询.修改.删除,pom依赖和获取es连接 可查看此文章. package com.xsjt.learn; import java ...
- Puppet软件资源管理
1.实现的功能: 管理那些软件包被安装,那些软件包被卸载 管理软件包是否更新 要求系统配置yum源(RedHat系统).zypper源(Suse系统)等等 2.可用参数: en ...
- 有重复行,查询时只保留最新一行的sql
一.表结构如下:表名test 二.sql select temp.* from (select test.*, row_number() over(partition by obd_code orde ...