大数据(1):基于sogou.500w.utf8数据的MapReduce程序设计
环境:centos7+hadoop2.5.2
1.使用ECLIPS具打包运行WORDCOUNT实例,统计莎士比亚文集各单词计数(文件SHAKESPEARE.TXT)。
①WorldCount.java 中的main函数修改如下:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入文本路径
FileInputFormat.addInputPath(job, new Path("/input"));
//设置mp结果输出路径
FileOutputFormat.setOutputPath(job, new Path("/output/wordcount")); System.exit(job.waitForCompletion(true) ? 0 : 1);
}
②导出WordCount的jar包:
export->jar file->next->next->Main class里面选择WordCount->Finish。
③使用scp将wc.jar拷贝到node1机器,创建目录:hadoop fs –mkdir /input,将shakespeare.txt上传到hdfs上,运行wc.jar文件:hadoop jar wc.jar
④使用hadoop fs -cat /output/wordcount/part-r-00000 grep|head -n 30 查看前30条输出结果: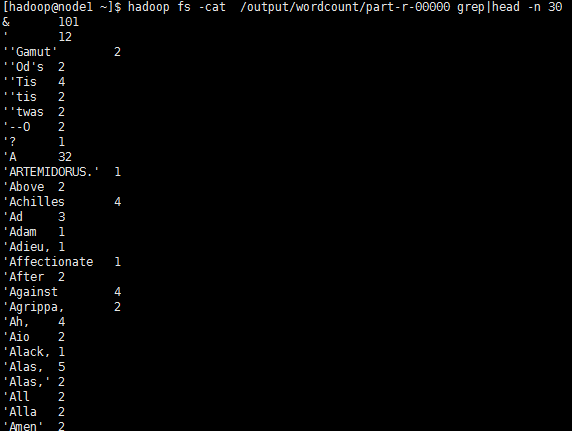
2.对于SOGOU_500W_UTF文件,完成下列程序设计内容:
(1) 统计每个用户搜索的关键字总长度
Mapreduce程序:
public class sougou3 {
public static class Sougou3Map extends
Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] vals = line.split("\t");
String uid = vals[1];
String search = vals[2];
context.write(new Text(uid), new Text(search+"|"+search.length()));
}
}
public static class Sougou3Reduce extends
Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
String result = "";
for (Text value : values) {
String strVal = value.toString();
result += (strVal+" ");
}
context.write(new Text(key + "\t"), new Text(result));
}
}
}
输出结果:
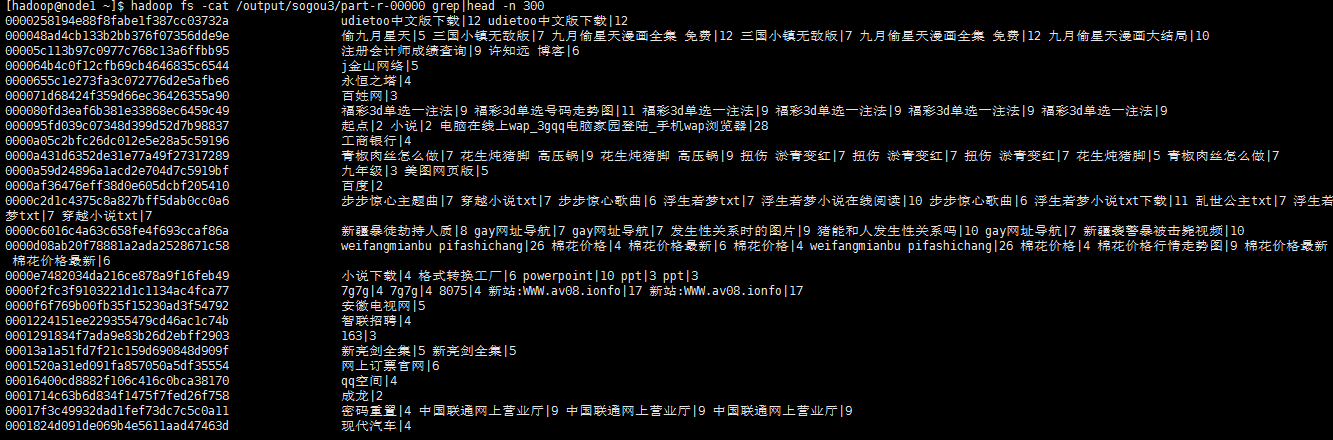 (2) 统计2011年12月30日1点到2点之间,搜索过的UID有哪些?
(2) 统计2011年12月30日1点到2点之间,搜索过的UID有哪些?
Mapreduce程序:
public class sougou1 {
public static class Sougou1Map extends
Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] vals = line.split("\t");
String time = vals[0];
String uid = vals[1];
//2008-07-10 19:20:00
String formatTime = time.substring(0,4)+"-"+time.substring(4,6)+"-"+time.substring(6,8)+" "
+time.substring(8,10)+":"+time.substring(10,12)+":"+time.substring(12,14);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date;
try {
date = sdf.parse(formatTime);
Date date1 = sdf.parse("2011-12-30 01:00:00");
Date date2 = sdf.parse("2011-12-30 02:00:00");
//日期在范围区间上
if (date.getTime() > date1.getTime() && date.getTime() < date2.getTime()){
context.write(new Text(uid), new Text(formatTime));
}
} catch (ParseException e) {
e.printStackTrace();
}
}
}
public static class Sougou1Reduce extends
Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
String result = "";
for (Text value : values) {
result += value.toString()+"|";
}
context.write(key, new Text(result));
}
}
}
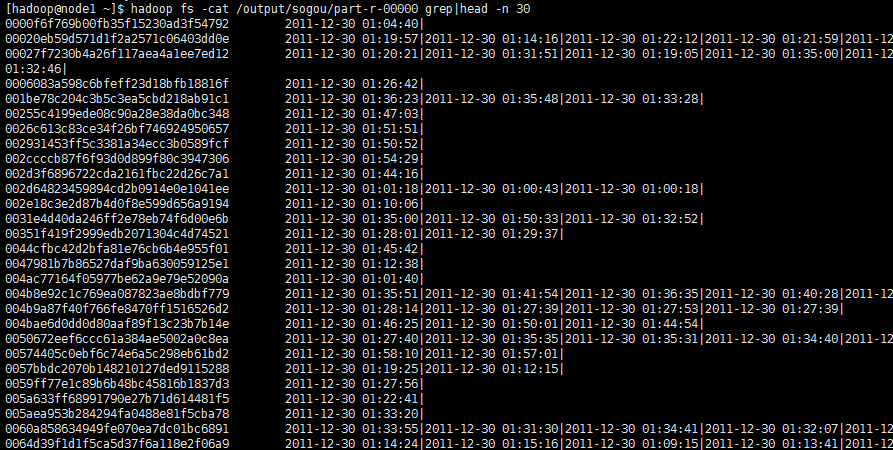
输出结果:
左边是用户id,右边分别是时间,以“|”作为分割。
(3) 统计搜索过‘仙剑奇侠’的每个UID搜索该关键词的次数。
Mapreduce程序:
public class sougou2 {
public static class Sougou2Map extends
Mapper<Object, Text, Text, IntWritable> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] vals = line.split("\t");
String uid = vals[1];
String search = vals[2];
if (search.equals("仙剑奇侠")){
context.write(new Text(uid), new IntWritable(1));
}
}
}
public static class Sougou2Reduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int result = 0;
for (IntWritable value : values) {
result += value.get();
}
context.write(new Text(key+"\t"), new IntWritable(result));
}
}
}
输出结果:
UID为:6856e6e003a05cc912bfe13ebcea8a04的用户搜索过“仙剑奇侠”共1次。
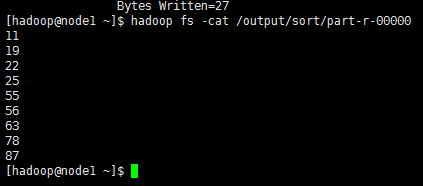
3.使用MAPREDUCE程序设计实现对文件中下列数据的排序操作78 11 56 87 25 63 19 22 55
Mapreduce程序:
public class Sort {
//map将输入中的value化成IntWritable类型,作为输出的key
public static class Map extends Mapper<Object,Text,IntWritable,NullWritable>{
private static IntWritable data=new IntWritable();
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
String line=value.toString();
data.set(Integer.parseInt(line));
context.write(data, NullWritable.get());
}
}
//reduce将输入中的key复制到输出数据的key上,
//然后根据输入的value-list中元素的个数决定key的输出次数
//用全局linenum来代表key的位次
public static class Reduce extends
Reducer<IntWritable,NullWritable,IntWritable,NullWritable>{
//实现reduce函数
public void reduce(IntWritable key,Iterable<NullWritable> values,Context context)
throws IOException,InterruptedException{
for(NullWritable val:values){
context.write(key, NullWritable.get());
}
}
}
}
输出内容为:
4.学生成绩文件TXT内容(字段用TAB键分隔)如下,使用MAPREDUCE计算每个学生的平均成绩
李平 87 89 98 75
张三 66 78 69 70
李四 96 82 78 90
王五 82 77 74 86
赵六 88 72 81 76
Mapreduce 程序:
public class Score {
public static class ScoreMap extends
Mapper<Object, Text, Text, NullWritable> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
context.write(value, NullWritable.get());
}
}
public static class ScoreReduce extends
Reducer<Text, NullWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
for (NullWritable nullWritable : values) {
String line = key.toString();
String[] vals = line.split("\t");
String name = vals[0];
int val1 = Integer.parseInt(vals[1]);
int val2 = Integer.parseInt(vals[2]);
int val3 = Integer.parseInt(vals[3]);
int average = (val1 + val2 + val3) / 3;
context.write(new Text(name), new IntWritable(average));
}
}
}
}
输出结果为
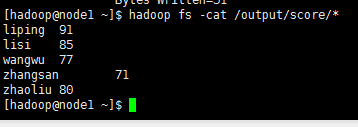
相关资料:
链接:http://pan.baidu.com/s/1dFD7mdr 密码:xwu8
大数据(1):基于sogou.500w.utf8数据的MapReduce程序设计的更多相关文章
- 大数据(2):基于sogou.500w.utf8数据hive的实践
一.环境的搭建 1.安装配置mysql rpm –ivh MySQL-server-5.6.14.rpm rpm –ivh MySQL-client-5.6.14.rpm 启动mysql 创建hive ...
- 大数据(3):基于sogou.500w.utf8数据Hbase和Spark实践
1. HBase安装部署操作 a) 解压HBase安装包tar –zxvf hbase-0.98.0-hadoop2-bin.tar.gzb) 修改环境变量 hbase-env.shexport JA ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据下基于Tensorflow框架的深度学习示例教程
近几年,信息时代的快速发展产生了海量数据,诞生了无数前沿的大数据技术与应用.在当今大数据时代的产业界,商业决策日益基于数据的分析作出.当数据膨胀到一定规模时,基于机器学习对海量复杂数据的分析更能产生较 ...
- 【T-BABY 夜谈大数据】基于内容的推荐算法
这个系列主要也是自己最近在研究大数据方向,所以边研究.开发也边整理相关的资料.网上的资料经常是碎片式的,如果要完整的看完可能需要同时看好几篇文章,所以我希望有兴趣的人能够更轻松和快速地学习相关的知识. ...
- SpringMVC + ehcache( ehcache-spring-annotations)基于注解的服务器端数据缓存
背景 声明,如果你不关心java缓存解决方案的全貌,只是急着解决问题,请略过背景部分. 在互联网应用中,由于并发量比传统的企业级应用会高出很多,所以处理大并发的问题就显得尤为重要.在硬件资源一定的情况 ...
- 基于IBM Bluemix的数据缓存应用实例
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 摘要:IBM® Data Cache for Bluemix 是快速缓存服务.支持 Web 和 ...
- 使用C#处理基于比特流的数据
使用C#处理基于比特流的数据 0x00 起因 最近需要处理一些基于比特流的数据,计算机处理数据一般都是以byte(8bit)为单位的,使用BinaryReader读取的数据也是如此,即使读取bool型 ...
- 微软开放技术(中国)携 CKAN 和 OData 技术引入基于 Azure 的开放数据平台
今天,微软开放技术(中国)通过微软公有云Azure引入一个全新的开放数据平台,该平台基于开源数据门户解决方案 CKAN,以及由微软开放技术(中国)特别针对中国市场优化的ODATA插件来增强其国际化和本 ...
随机推荐
- 用Git的hooks实现项目的自动部署
https://segmentfault.com/a/1190000003836345?_ea=386770 http://blog.csdn.net/wsyw126/article/details/ ...
- Linux下用户和组管理
用户与组之间的关系是,组下面有若干个用户,每个用户必须从属于唯一一个组.组可以理解为权限的集合.用户管理的命令有:useradd, userdel, usermod, passwd, chsh, ch ...
- 前端JS面试题汇总 Part 3 (宿主对象与原生对象/函数调用方式/call与apply/bind/document.write)
原文:https://github.com/yangshun/front-end-interview-handbook/blob/master/questions/javascript-questio ...
- jstree树形菜单
final 用于声明属性.方法和类,分别表示属性不可变,方法不可重写,类不可继承.其实可以参考用easyui的tree 和 ztree参考: https://www.jstree.com/demo/ ...
- 什么是 JSX
JSX 即 JavaScript XML--一种在 React 组件内部构建标签的类 xml 语法.React 在不使用 JSX 的情况下一样可以工作,然而使用 JSX 可以提高组件的可读性,因此推荐 ...
- apue.h头文件(UNIX环境高级编程)
在看UNIX环境高级编程是,碰到一个头文件"apue.h",搜一下别人的帖子,其实apue.h是作者自己写的一个文件,包含了常用的头文件,系统不自带.其中包含了常用的头文件,以及出 ...
- 项目使用EntityFramework需要做的几项工作
1..新项目引用创建好的其他项目,比如实体类库.数据库业务.实体数据模型等需要用到的项目进行引用. 2.新项目使用NuGet获取AutoMapper和EntityFramework程序包进行安装引用, ...
- Unable to find the ncurses libraries的解决办法
我们在更新CentOS或者Ubuntu的内核时,执行make menuconfig可能看如这样的错误: *** Unable to find the ncurses libraries or the* ...
- mongodb一些使用技巧或注意事项记录
1.有的时候需要删除指定字段那一列,使用update操作.例如要删除name这一列: query json: {"name":{$exists:true}} update jso ...
- 错误代码: 1449 The user specified as a definer ('root'@'%') does not exist
1. 错误描述 1 queries executed, 0 success, 1 errors, 0 warnings 查询:call analyse_use('20150501','20150601 ...