scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取;
项目结构与项目3中相同如下图,唯一不同的为book.py文件
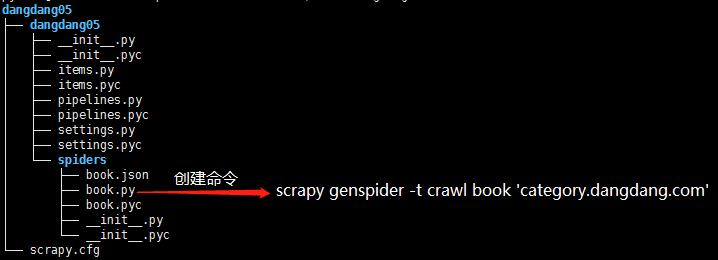
crawlspider类的爬虫文件book的生成命令为:scrapy genspider -t crawl book 'category.dangdang.com'
book.py代码如下:
# -*- coding: utf-8 -*-
import scrapy
# 创建用于提取响应中连接的对象
from scrapy.linkextractors import LinkExtractor
# Rule 用于发送从 LinkExtractor 中提取的连接
from scrapy.spiders import CrawlSpider, Rule
from dangdang05.items import Dangdang05Item class BookSpider(CrawlSpider):
name = 'book'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.54.12.00.00.00.html']
# 提取连接信息,并将提取到的向提取到的url发送请求,调用回调函数处理请求
# 注意follow表示是否继续对response中的连接进行提取,True表示提取,False表示不再提取
# 当未指定回调函数时,follow的默认值为True,当指定回调函数时follow的默认值为False
rules = [Rule(LinkExtractor(allow=r'/pg\d+-cp01.54.12.00.00.00.html'),callback='parse_item',follow=True)] def parse_item(self, response):
# 实例化items中的类
item = Dangdang05Item()
# 网页解析第一步,返回selector对对象
book_list = response.xpath('//ul[@class="bigimg"]/li') for book_info in book_list:
# 书籍名称
item['name'] = book_info.xpath('./p[@class="name"]/a/@title').extract()[0]
# 书籍价格
item['price'] = book_info.xpath('./p[@class="price"]/span[1]/text()').extract()[0]
yield item
scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)的更多相关文章
- scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析 当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html 点击下方的链接,一次观察各个页面的ur ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- 【转】java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- selenium自动化测试工具模拟登陆爬取当当网top500畅销书单
selenium自动化测试工具可谓是爬虫的利器,基本动态加载的网页都能抓取,当然随着大型网站的更新,也出现针对selenium的反爬,有些网站可以识别你是否用的是selenium访问,然后对你加以限制 ...
随机推荐
- 最常见的Python异常报错Error
内置异常 官网链接:https://docs.python.org/zh-cn/3/library/exceptions.html 在 Python 中,所有异常必须为一个派生自 BaseExcept ...
- 【6.18校内test】T2分数线划定
分数线划定[题目链接] 这道题也不是什么难题,思路一带而过吧: SOLUTION: First.输入n,m,计算m*1.5的值,接着输入编号和成绩,然后我的做法是在输入编号成绩之后,开一个101大小的 ...
- Linux 中将用户添加到指定组
添加组 usermod -a -G root dev 修改组 usermod -g root dec 删除组 gpasswd -d dev root gpasswd -a dev root //将用户 ...
- 运维LVS-NAT模式理解
一.LVS-NAT模式的工作原理这个是通过网络地址转换的方法来实现调度的.首先调度器(LB)接收到客户的请求数据包时(请求的目的IP为VIP),根据调度算法决定将请求发送给哪个 后端的真实服务器(RS ...
- ubuntu部署Java、Python开发环境
要部署Java开发环境首先就要安装JDK. 一.安装JDK8 1. 下载 jdk-8u172-linux-x64.tar.gz 到 /usr/java8/ 目录下: 2. tar -zxvf jd ...
- Linux下安装升级python
本文主要是参考帖子,感谢这位博主,我主要是对相关操作进行补充和说明. 本文主要是在linux(centos)下安装Python3.7.1 1.下载安装Python-3.7.1 1) 下载Python- ...
- mysql查看库、表占用存储空间大小
http://blog.csdn.net/bzfys/article/details/55252962 1. 查看该数据库实例下所有库大小,得到的结果是以MB为单位 <span class=&q ...
- ubuntu 安装nginx redis dotnet
1 安装nginx sudo apt-get update sudo apt-get install nginx 配置文件 /etc/nginx/nginx.conf 2 安装redis sudo a ...
- CentOS6.X系统启动流程
1.硬件启动阶段 BIOS自检 BIOS的功能由两部分组成,分别是POST码和Runtime服务.POST阶段完成后它将从存储器中被清除,而Runtime服务会被一直保留,用于目标操作系统的启动.B ...
- vue2.0 监听滚动 锚点定位
vue中监听滚动的方法其实可以用: // Chrome document.body.scrollTop // Firefox document.documentElement.scrollTop // ...