【Memcached】原理、体系架构、基本操作及路由算法
1. 什么是Memcached
要了解Memcached首先要到官网上去看官方对它的描述。Memcached的官网网站是:http://memcached.org/,官方对Memcached的描述如下图:

从官方的描述中可以总结出,Memcached是一个高性能分布式的内存对象缓存系统。它将数据以key-value形式存储的存储在内存中,极大的提高了效率。但是Memcached的缺点在于不支持持久化(不支持写入磁盘),所以一旦断电,内存中的全部数据都会丢失。而Redis弥补了这个缺点,既在内存中存取数据,又支持持久化,所以Memcached可以理解为是Redis的前身,关于Redis的技术,后续会发新的文章论述,这里不展开讨论。
2. Memcached基本原理和体系架构
实际上,Memcached是在内存中维护一张巨大的Hash表。这张Hash表的结构是由多个slab组成,每个slab的大小是1M;每个slab中存在多个chunk,chunk是数据最终存储的单位。chunk采用预分配的方式提高性能,在保存数据之前,需要制定chunk的大小来分配内存。如add key *** 3
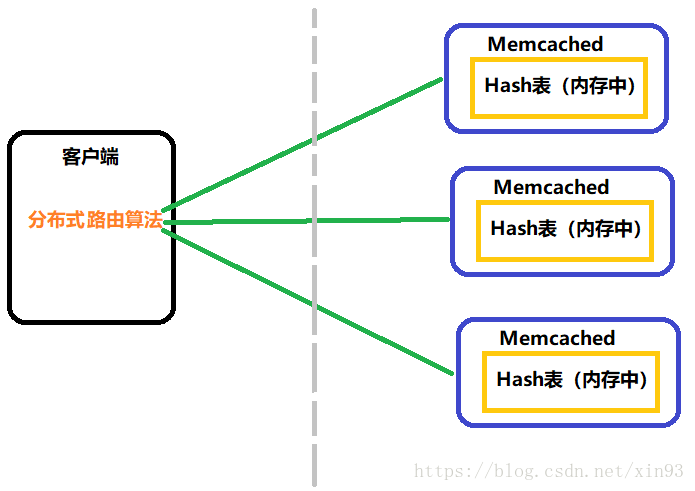
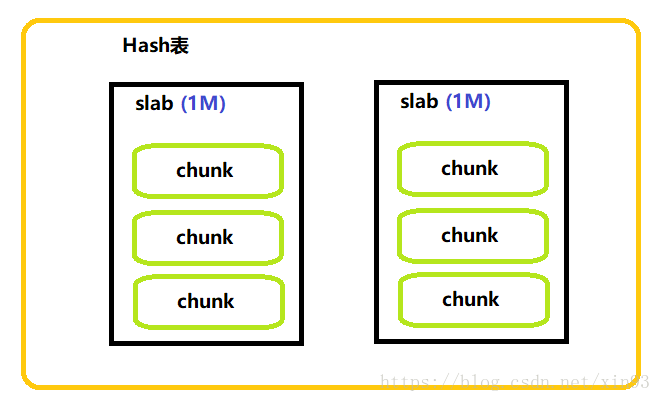
3. Memcached 集群
3.1 背景
Memcached官方版本不支持集群搭建,Memcached彼此之间不进行通信,也就是把一个数据存到一个Memcached上,一旦这个Memcached宕掉了,不能从其它Memcached上读取这些数据,会造成数据丢失。
但是,一个日本工程师改写了官方Memcached,使它能够支持集群。此时,Memcached之间可以进行通信,数据存储到一个Memcached实例上,可以同步到其它Memcached实例,防止数据丢失。
3.2 基本操作
3.2.1 命令行
(1) 启动并连接memcached

(2) 添加数据:set、add(当存在相同key值时,set会覆盖value,add会报错);获取数据:get
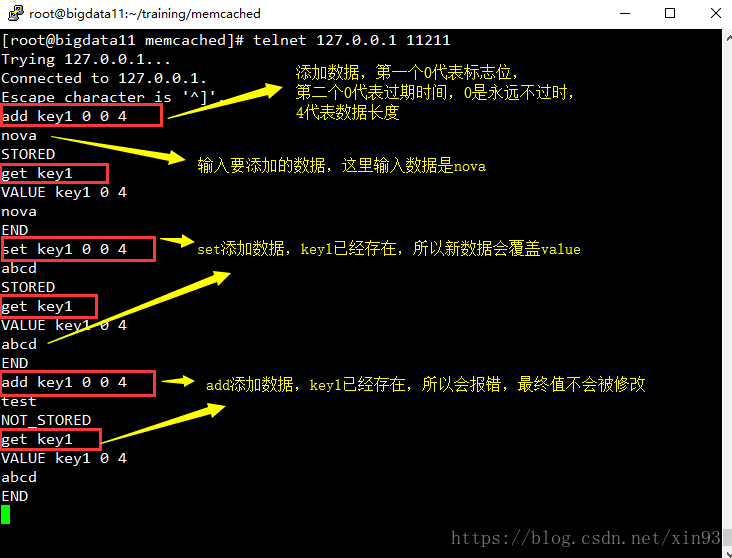
(2) 查看slab信息

3.2.2 JavaAPI
1. 首先创建一个Java项目,然后添加memcached的jar包,如果网上找不到jar包的话可以在这个链接下载:https://download.csdn.net/download/xin93/10482424
2. 创建一个简单的Person信息类,用于存储到Memcached。
package com.nova; import java.io.Serializable;
/**
*
* @author Supernova
* @date 2018/06/16
*
*/
public class Person implements Serializable{
private String name; //姓名
private String sex; //性别 public Person() { }
public Person(String name, String sex) {
super();
this.name = name;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
} }
3. 添加、获取
package com.nova; import java.net.InetSocketAddress;
import java.util.concurrent.Future; import org.junit.Test; import net.spy.memcached.MemcachedClient;
/**
*
* @author Supernova
* @date 2018/06/16
*
*/
public class MemcachedOperation {
/*
* 向memcached添加数据
*/
@Test
public void addData() throws Exception {
// 创建Memcached客户端
MemcachedClient client = new MemcachedClient(new InetSocketAddress("192.168.243.11", 11211));
// 插入数据
Future<Boolean> future= client.set("name", 0, "Supernova");
//判断执行操作后返回的Boolean值
if(future.get().booleanValue()) {
//插入成功 client.shutdown();
}
} /*
* 获取memcached数据
*/
@Test
public void getData() throws Exception{
// 创建Memcached客户端
MemcachedClient client = new MemcachedClient(new InetSocketAddress("192.168.243.11",11211));
// 获取对应key值的value
String name = client.get("name").toString();
System.out.println(name);
}
/*
* 向memcached存储一个对象
*/
@Test
public void insertObject() throws Exception{
// 创建Memcached客户端
MemcachedClient client = new MemcachedClient(new InetSocketAddress("192.168.243.11",11211)); Person person = new Person("Supernova","man");
// 插入对象
Future<Boolean> future = client.set("person", 0, person); if(future.get().booleanValue()) {
//插入成功 client.shutdown();
}
} }
3.2 路由算法
既然Memcached实例可以有多个,那么当客户端发送一条数据的时候,这条数据要存储到哪个Memcached实例中?所以这就涉及到了Memcached路由算法,由它来决定数据最终存储在哪个Memcached上。注意:Memcached路由算法是由客户端实现的。在Memcached中有两种路由算法
3.2.1 求余数
【基本原理】将key做hash运算,对memcached数量进行求余数,根据余数来决定存储到哪个Memcached实例。
如:有 4 台Memached,将对4进行求余数
8%4 = 0
7%4 = 3
6%4 = 2
5%4 = 1
……
这样根据余数路由的优点在于,能够使数据均匀分布在每个Memcached上,但是也有很大的缺点,一旦某个Memcached宕机,或有新的memcached加入就会找不到数据,出现严重的数据丢失。
【数据丢失的原因】:
比如原先有3个Memcached:1%3=1, 2%3=2, 3%3=0, 4%3=1,……
新增之后为4个Memcached:1%4=1, 2%4=2, 3%4=2, 4%4=0,……
原先3存在0号,4存在1号,但是新增后,3变成2号,4变成0号。导致了存取的目标位置不一样,在0号存,去2号取就会找不到数据。
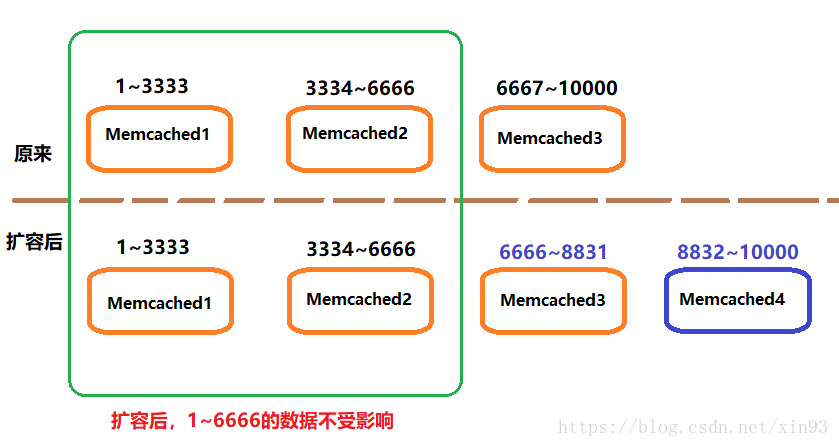
3.2.2 一致性Hash
一致性hash能够将丢失的数据减小到最小,但不能完全解决宕机造成的数据丢失。
【基本原理】:
如下图所示,数据分段在Memcached上存储,当扩容的时候,1~6666的数据将不受影响。同理,当有机器宕机的时候也一样。
【Memcached】原理、体系架构、基本操作及路由算法的更多相关文章
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- Kylin工作原理、体系架构
核心思想:预计算. 对多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube,并存在HBase中,供查询时直接访问 将高复杂度的聚合运算.多表连接……操作转换成对预计算结果的查询.决定了Kyl ...
- 说说面向服务的体系架构SOA
序言 在.Net的世界中,一提及SOA,大家想到的应该是Web Service,WCF,还有人或许也会在.NET MVC中的Web API上做上标记,然后泛泛其谈! 的确,微软的这些技术也确实推动着面 ...
- 面向服务的体系架构SOA
面向服务的体系架构SOA 序言 在.Net的世界中,一提及SOA,大家想到的应该是Web Service,WCF,还有人或许也会在.NET MVC中的Web API上做上标记,然后泛泛其谈! 的确,微 ...
- Memcached原理与应用
Memcached原理与应用 标签: linux 笔者Q:972581034 交流群:605799367.有任何疑问可与笔者或加群交流 1.Memcached是什么 高性能 支持高并发 分布式内存缓存 ...
- kafka原理和架构
转载自: https://blog.csdn.net/lp284558195/article/details/80297208 参考: https://blog.csdn.net/qq_2059 ...
- [转]OpenContrail 体系架构文档
OpenContrail 体系架构文档 英文原文:http://opencontrail.org/opencontrail-architecture-documentation/ 翻译者:@KkBLu ...
- InnoDB引擎体系架构
InnoDB引擎架构介绍 innodb存储引擎的体系架构,可简单划分成三层: 数据文件 :磁盘上的数据文件 内存池:缓存磁盘上的数据,方便读取,同时在对磁盘文件数据修改之前在这里缓存,然后按一定规刷新 ...
随机推荐
- 分布式服务框架dubbo原理解析
alibaba有好几个分布式框架,主要有:进行远程调用(类似于RMI的这种远程调用)的(dubbo.hsf),jms消息服务(napoli.notify),KV数据库(tair)等.这个框架/工具/产 ...
- D3 JS study notes
如何使用d3来解析自定义格式的数据源? var psv = d3.dsvFormat("|"); // This parser can parse pipe-delimited t ...
- 上传通用化 VHD 并使用它在 Azure 中创建新 VM
本主题逐步讲解如何使用 PowerShell 将通用化 VM 的 VHD 上传到 Azure.从该 VHD 创建映像,然后从该映像创建新 VM. 可以上传从本地虚拟化工具或其他云导出的 VHD. 对新 ...
- 【Oracle】查看被锁的表和解锁
--以下几个为相关表SELECT * FROM v$lock;SELECT * FROM v$sqlarea;SELECT * FROM v$session;SELECT * FROM v$proce ...
- Sql Server关于日期查询时,如果表中日期到具体某个时间
1.如果查询日期参数为'2017/02/21',而数据库表中的字段为'2017/02/21 12:34:16.963',则需要格式化一下日期才能查询出来,如下 select * from table ...
- Ubuntu下Visual Studio Code的配置
最近在Ubuntu系统里用Visual Studio Code编写vue代码时,在build的时候老是报错,后来发现原来Visual Studio Code里默认Tab是4个空格,而vue代码要求ta ...
- [翻译] TWRPickerSlider
TWRPickerSlider https://github.com/chasseurmic/TWRPickerSlider Usage Add the dependency to your Podf ...
- Java 运算符(引用和对象)
1. 算数运算符 就是+.-.*./.%.++.--这些,没什么好说的,稍微强调下自加,自减: 前缀自增自减法(++i,--i): 先进行自增或者自减运算,再进行表达式运算. 后缀自增自减法(i++, ...
- Apache Jemeter 开发插件
为什么选择使用JMeter 当被问到这个问题的时候,也许你会在脑海里产生很多的理由,比如: Apache基金会下的开源项目,没有版权问题: 为数不多的还在持续更新的开源性能自动化测试工具: 支持协议丰 ...
- Python数据类型-字典
字典(dict) 字典是key:value形式的一种表达形式,例如在Java中有map,JavaScript中的json,Redis中的hash等等这些形式.字典可以存储任意的对象,也可以是不同的数据 ...