hadoop(五)HDFS原理剖析
一、HDFS的工作机制
工作机制的学习主要是为加深对分布式系统的理解,以及增强遇到各种问题时的分析解决能 力,形成一定的集群运维能力
PS:很多不是真正理解 hadoop 工作原理的人会常常觉得 HDFS 可用于网盘类应用,但实际 并非如此。要想将技术准确用在恰当的地方,必须对技术有深刻的理解
概述
1、 HDFS 集群分为两大角色: NameNode、 DataNode (Secondary Namenode)
2、 NameNode 负责管理整个文件系统的元数据,并且负责响应客户端的请求
3、 DataNode 负责管理用户的文件数据块,并且通过心跳机制汇报给 namenode
4、 文件会按照固定的大小( blocksize)切成若干块后分布式存储在若干台 datanode 上
5、 每一个文件块可以有多个副本,并存放在不同的 datanode 上
6、 Datanode 会定期向 Namenode 汇报自身所保存的文件 block 信息,而 namenode 则会负 责保持文件的副本数量
7、 HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向 namenode 申请来进行
二、HDFS写数据流程
概述:客户端要向 HDFS 写数据,首先要跟 namenode 通信以确认可以写文件并获得接收文件 block 的 datanode,然后,客户端按顺序将文件逐个 block 传递给相应 datanode,并由接收到 block 的 datanode 负责向其他 datanode 复制 block 的副本 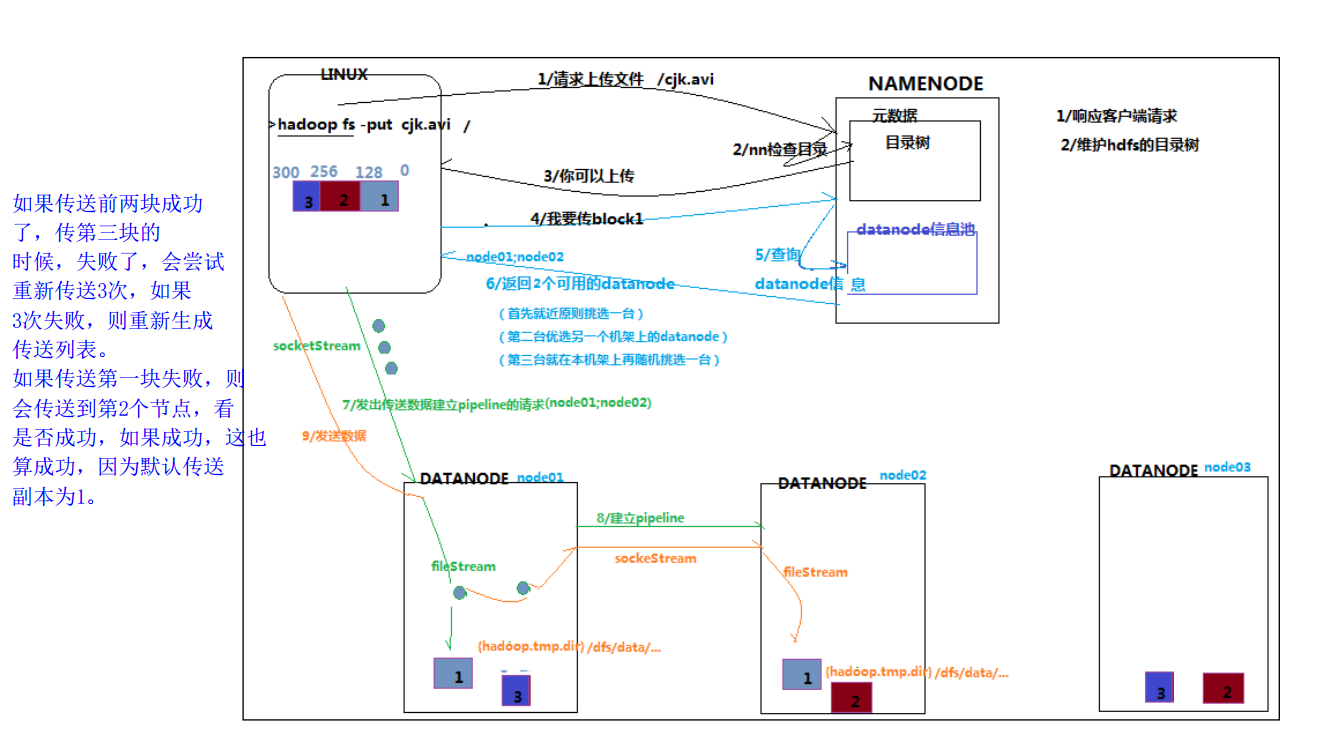
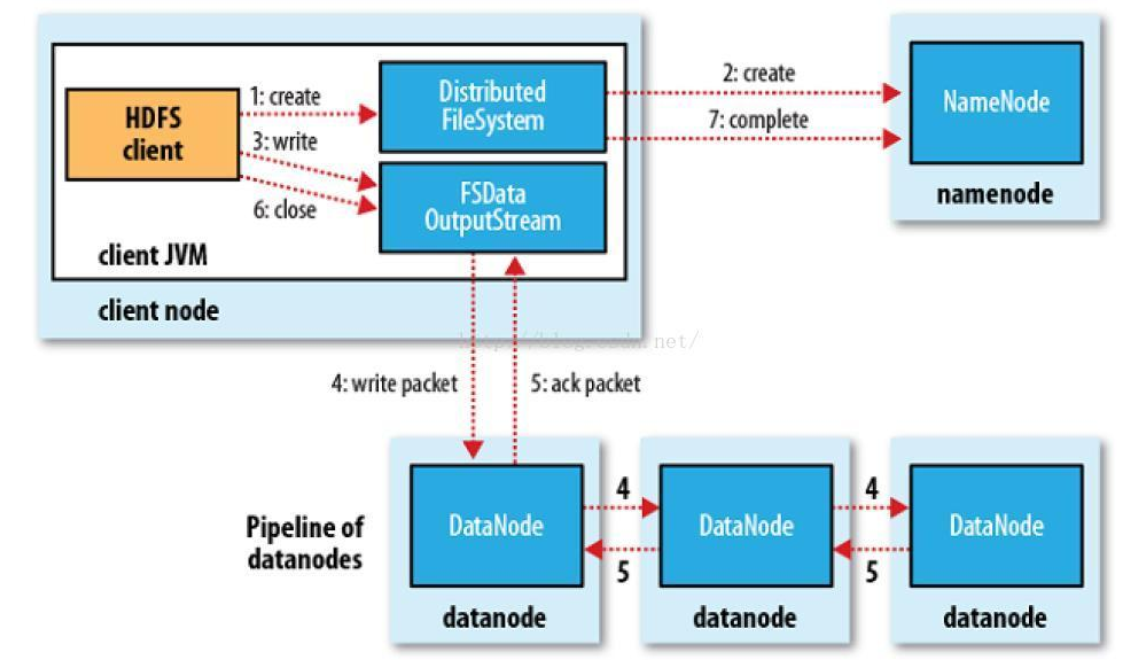
详细步骤文字说明:
1、使用 HDFS 提供的客户端 Client,向远程的 Namenode 发起 RPC 请求
2、 Namenode 会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会 为文件创建一个记录,否则会让客户端抛出异常;
3、当客户端开始写入文件的时候,客户端会将文件切分成多个 packets,并在内部以数据队 列“ data queue(数据队列)”的形式管理这些 packets,并向 Namenode 申请 blocks,获 取用来存储 replicas 的合适的 datanode 列表,列表的大小根据 Namenode 中 replication
的设定而定;
4、开始以 pipeline(管道)的形式将 packet 写入所有的 replicas 中。客户端把 packet 以流的 方式写入第一个 datanode,该 datanode 把该 packet 存储之后,再将其传递给在此 pipeline 中的下一个 datanode,直到最后一个 datanode,这种写数据的方式呈流水线的形式。
5、最后一个 datanode 成功存储之后会返回一个 ack packet(确认队列),在 pipeline 里传递 至客户端,在客户端的开发库内部维护着"ack queue",成功收到 datanode 返回的 ack packet 后会从"ack queue"移除相应的 packet。
6、如果传输过程中,有某个 datanode 出现了故障,那么当前的 pipeline 会被关闭,出现故 障的 datanode 会从当前的 pipeline 中移除,剩余的 block 会继续剩下的 datanode 中继续 以 pipeline 的形式传输,同时 Namenode 会分配一个新的 datanode,保持 replicas 设定的
数量。
7、客户端完成数据的写入后,会对数据流调用 close()方法,关闭数据流;
8、只要写入了 dfs. replication. min(最小)的复本数(默认为 1),写操作就会成功,并且这 个块可以在集群中异步复制,直到达到其目标复本数( dfs. replication 的默认值为 3), 因为 namenode 已经知道文件由哪些块组成,所以它在返回成功前只需要等待数据块进
行最小量的复制。
自己手写版:
1、client发写数据请求
2、namenode 响应请求,然后做一系列校验,如果能上传该数据,则返回该文件的所有切块应该被存在哪些datanode上的datanodes列表
blk-001:hadoop02 hadoop03
blk-002:hadoop03 hadoop04
3、client拿到datanode列表之后,开始传数据
4、首先传第一块blk-001,datanode列表就是hadoop02,hadoop03,client就把blk-001传到hadoop02,hadoop03上
5、....用传第一个数据块同样的方式传其他的数据
6、当所有数据块都传完之后,client会给namenode 返回一个状态信息,表示数据已全部写入成功,或者是失败信息。
7、Namenode 接受到client返回的状态信息来判断当次写入数据的请求是否成功,如果成功,就需要更新元数据信息。
三、HDFS读数据流程
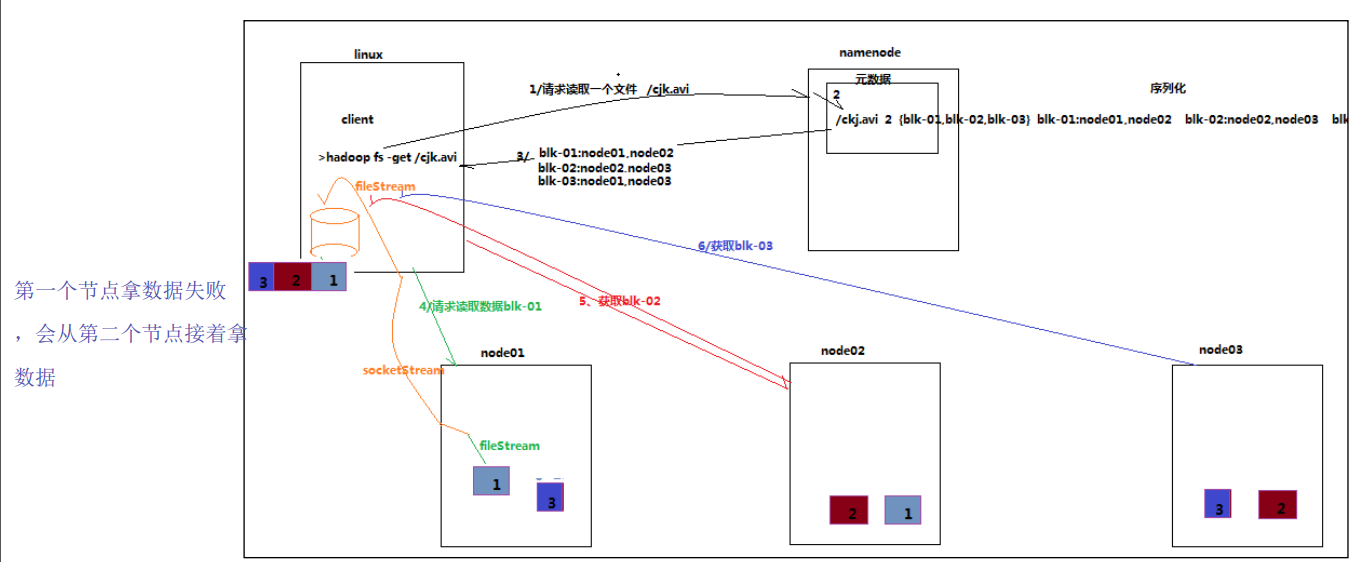
概述:客户端将要读取的文件路径发送给 namenode, namenode 获取文件的元信息(主要是 block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应 datanode 逐个获取文件的 block 并在客户端本地进行数据追加合并从而获得整个文件
详细步骤图:
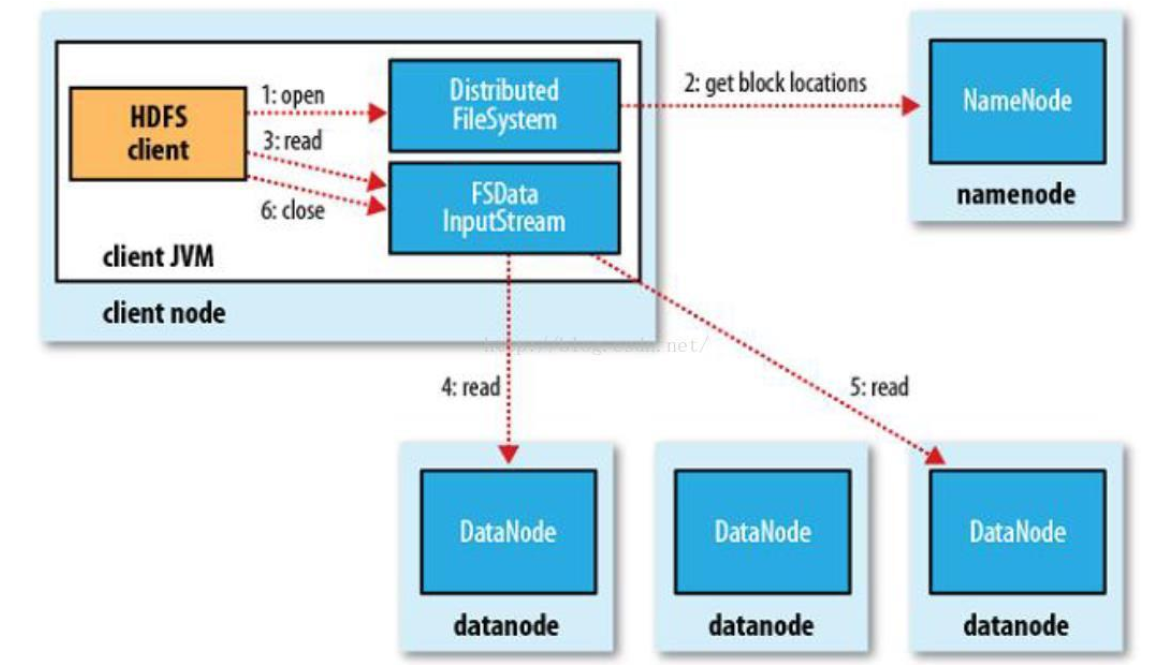
详细文字说明
1、使用 HDFS 提供的客户端 Client,向远程的 Namenode 发起 RPC 请求;
2、 Namenode 会视情况返回文件的全部 block 列表,对于每个 block, Namenode 都会返回有该 block 拷贝的 DataNode 地址;
3、客户端 Client 会选取离客户端最近的 DataNode 来读取 block;如果客户端本身就是 DataNode,那么将从本地直接获取数据;
4、读取完当前 block 的数据后,关闭当前的 DataNode 链接,并为读取下一个 block 寻找最 佳的 DataNode;
5、当读完列表 block 后,且文件读取还没有结束,客户端会继续向 Namenode 获取下一批 的 block 列表;
6、读取完一个 block 都会进行 checksum 验证,如果读取 datanode 时出现错误,客户端会 通知 Namenode,然后再从下一个拥有该 block 拷贝的 datanode 继续读。
四、NameNode 的工作机制
1、namenode 职责
负责客户端请求的响应(读写文件、删除文件、重命名等等)
元数据的管理(查询,修改)
2、namenode元数据管理
WAL( Write ahead Log): 每做一次操作之前,都会被记下来到这个日志中,然后再做操作,如果成功了,日志会对这次操作做一个成功或者失败的标记,下次执行时,直接从WAL中拿出来执行 (WAL主要记录 增删改)
NameNode 对数据的管理采用了三种存储形式:
(1) 内存元数据 metadata(全部存在内存中) (完整的元数据全部存在内存中,断电就没了)
(2)磁盘元数据镜像文件 fsimage(全部存在磁盘)
(3)数据操作日志文件(可通过日志运算出元数据) edits(全部存在磁盘中)
edits:(edits-inprogress + 所有类似edits-001-004这种格式的edits)
metadata = 最新的fsimage + edits-inprogress
metadata = 所有的edits之和
(所有类似edits-001-004这种格式的edits 已经合并到fsimage)
3、NameNode 元数据存储机制
A、内存中有一份完整的元数据(内存 metadata)
B、磁盘有一个“准完整”的元数据镜像( fsimage)文件(在 namenode 的工作目录中)
C、用于衔接内存 metadata 和持久化元数据镜像 fsimage 之间的操作日志( edits 文件)
PS:当客户端对 hdfs 中的文件进行新增或者修改操作,操作记录首先被记入 edits 日志 文件中,当客户端操作成功后,相应的元数据会更新到内存 metadata 中 (这就是WAL)
4、元数据的CheckPoint
每隔一段时间,会由 secondary namenode 将 namenode 上积累的所有 edits 和一个最新的 fsimage 下载到本地,并加载到内存进行 merge(这个过程称为 checkpoint)
CheckPoint 详细过程图解:
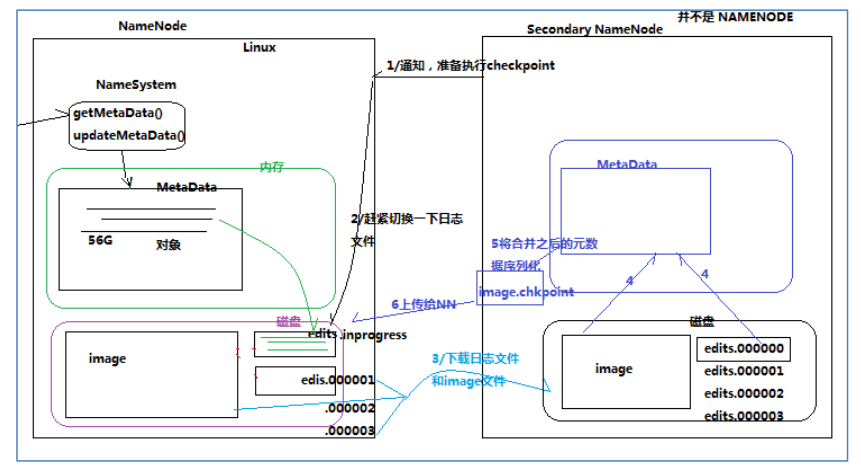
5、CheckPoint触发配置

6、CheckPoint的附带作用
Namenode 和 SecondaryNamenode 的工作目录存储结构完全相同,所以,当 Namenode 故障 退出需要重新恢复时,可以从 SecondaryNamenode的工作目录中将 fsimage拷贝到 Namenode 的工作目录,以恢复 namenode 的元数据
五、DataNode工作机制
1、 Datanode 工作职责:
存储管理用户的文件块数据
定期向 namenode 汇报自身所持有的 block 信息(通过心跳信息上报)
( PS: 这点很重要,因为,当集群中发生某些 block 副本失效时,集群如何恢复 block 初始 副本数量的问题)
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property
2、 Datanode 掉线判断时限参数
datanode 进程死亡或者网络故障造成 datanode 无法与 namenode 通信, namenode 不会立即 把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。 HDFS 默认的超时时长
为 10 分钟+30 秒。如果定义超时时间为 timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的 heartbeat.recheck.interval 大小为 5 分钟, dfs.heartbeat.interval 默认为 3 秒。 需 要 注 意 的 是 hdfs-site.xml 配 置 文 件 中 的 heartbeat.recheck.interval 的 单位 为 毫 秒 ,dfs.heartbeat.interval 的单位为秒。
所以,举个例子,如果 heartbeat.recheck.interval 设置为 5000(毫秒), dfs.heartbeat.interval 设置为 3(秒,默认),则总的超时时间为 40 秒。

3、观察验证Datanode功能
上传一个文件,观察文件的 block 具体的物理存放情况:
在每一台 datanode 机器上的这个目录中能找到文件的切块:
/home/hadoop/app/hadoop-2.5.2/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457
733977/current/finalized
六、SecondaryNamenode 工作机制
就是 CheckPoint 的工作机制 请看元数据的 CheckPoint
hadoop(五)HDFS原理剖析的更多相关文章
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- 【Hadoop】HDFS原理、元数据管理
1.HDFS原理 2.元数据管理原理
- MapReduce/Hbase进阶提升(原理剖析、实战演练)
什么是MapReduce? MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",和他们 ...
- hadoop之hdfs及其工作原理
hadoop之hdfs及其工作原理 (一)hdfs产生的背景 随着数据量的不断增大和增长速度的不断加快,一台机器上已经容纳不下,因此就需要放到更多的机器中,但这样做不方便维护和管理,因此需要一种文件系 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- hadoop学习之HDFS原理
HDFS原理 HDFS包括三个组件: NameNode.DataNode.SecondaryNameNode NameNode的作用是存储元数据(文件名.创建时间.大小.权限.与block块映射关系等 ...
- hadoop中HDFS的NameNode原理
1. hadoop中HDFS的NameNode原理 1.1. 组成 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 1.2. HDFS架构 ...
随机推荐
- CentOS 下 MySQL 5.6 基于 RPM 的下载、安装、配置
CentOS 下 MySQL 5.6 基于 RPM 的下载.安装.配置 系统: CentOS 7 x86_64 MySQL 版本: 5.6.40 安装方式: RPM 下载 下载地址 操作系统 选择 R ...
- qs.js - 更好的处理url参数
第一次接触 qs 这个库,是在使用axios时,用于给post方法编码,在使用过程中,接触到了一些不同的用法,写在这里分享一下. qs.parse qs.parse 方法可以把一段格式化的字符串转换为 ...
- 使用Photon引擎进行unity网络游戏开发(一)——Photon引擎简介
使用Photon引擎进行unity网络游戏开发(一)--Photon引擎简介 Photon PUN Unity 网络游戏开发 Photon引擎简介: 1. 服务器引擎: 服 务 器 引 擎 介 绍 服 ...
- 最强NLP模型-BERT
简介: BERT,全称Bidirectional Encoder Representations from Transformers,是一个预训练的语言模型,可以通过它得到文本表示,然后用于下游任务, ...
- PPM、PGM、PBM图像格式剖析
今天突然需要用到PPM这个图像文件格式,之前没见过,在此记录一下. PPM.PGM.PBM这三个图像文件格式很少见,其实也不难,分别用于彩色图像.灰度图像.二值图像.这里以PPM格式为例. PPM格式 ...
- mac react-native从零开始android真机测试
1. 安装android相关jdk,(https://blog.csdn.net/vvv_110/article/details/72897142) 2. 手机和mac使用usb连接, 手机开发者设置 ...
- VisualSVN Server的配置和使用方法
VisualSVN Server的配置和使用方法 VisualSVN Server的配置和使用方法[服务器端] 安装好VisualSVN Server后[安装过程看这里],运行VisualSVN Se ...
- "Hello World"团队召开的第三周第七次会议
今天是我们团队“Hello World!”团队召开的第三周的第七次会议.博客内容: 一.会议时间 二.会议地点 三.会议成员 四.会议内容 五.Todo List 六.会议照片 七.燃尽图 一.会议时 ...
- RIGHT-BICEP测试第二次程序
根据Right-BICEP单元测试的方法我对我写的第二次程序进行了测试: 测试一:测试能否控制使用乘除 测试二:测试是否能加括号 测试三:是否可以控制题目输出数量 测试四:能否控制输出方式,选择文件输 ...
- 四则运算4 WEB(结对开发)
在第三次实验的基础上,teacher又对此提出了新的要求,实现网页版或安卓的四则运算. 结对开发的伙伴: 博客名:Mr.缪 姓名:缪金敏 链接:http://www.cnblogs.com/miaoj ...