Node爬虫之——使用async.mapLimit控制请求并发
一般我们在写爬虫的时候,很多网站会因为你并发请求数太多当做是在恶意请求,封掉你的IP,为了防止这种情况的发生,我们一般会在代码里控制并发请求数,Node里面一般借助async模块来实现。
1. async.mapLimit方法
mapLimit(arr, limit, iterator, callback)
arr中一般是多个请求的url,limit为并发限制次数,mapLimit方法将arr中的每一项依次拿给iterator去执行,执行结果传给最后的callback;
2. async.mapLimit方法应用
下面是之前写过的一个简单的爬虫示例,将爬取到的新闻标题和路径保存在一个Excel表格中,限制并发数为3,代码如下
webSpider.js:
//request调用url主函数 (mapLimit iterator)
function main(option, callback) {
n++;
timeline[option] = new Date().getTime();
console.log('现在的并发数是', n, ',正在抓取的是', option);
request(option, function(err, res, body) {
if(!err && res.statusCode == 200){
var $ = cheerio.load(body);
$('#post_list .post_item').each(function(index, element) {
// console.log(element);
var item = [$(element).find('.post_item_body h3 a').text(),$(element).find('.post_item_body h3 a').attr('href')];
dataArr[0].data.push(item);
});
console.log('抓取', option, '结束,耗时:', new Date().getTime()-timeline[option], '毫秒');
n--;
callback(null, 'done!');
}else{
console.log(err);
n--;
callback(err, null);
}
});
}
//限制请求并发数为3
async.mapLimit(options, 3, main.bind(this), function(err, result){
if(err) {
console.log(err);
} else {
fs.writeFile('data/cnbNews.xlsx', xlsx.build(dataArr), 'utf-8', function(err){
if(err){
console.log('write file error!');
}else{
console.log('write file success!');
}
});
}
});
这里迭代器里面第二个参数callback(即请求每一条url完成之后的回调方法)是关键,没有异常的情况下所有options中的url都请求完成之后会回调mapLimit方法的回调方法进行后续操作(如这里的生成文件),如果单条url请求异常,回调方法中会接收到err并报出错误,不能执行后续生成文件的操作。
async.mapLimit(options, 3, function(option, callback) {
request(option, main);
callback(null);
}, function(err, result) {
if(err) {
console.log(err);
} else {
console.log('done!');
}
});
如上,网上有些资料中是在迭代器中request方法执行完成之后调用callback,因为request方法异步接收请求数据,这种写法会使async.mapLimit方法limit参数无效,导致无法达到限制请求并发数的目的,这里需要注意下。
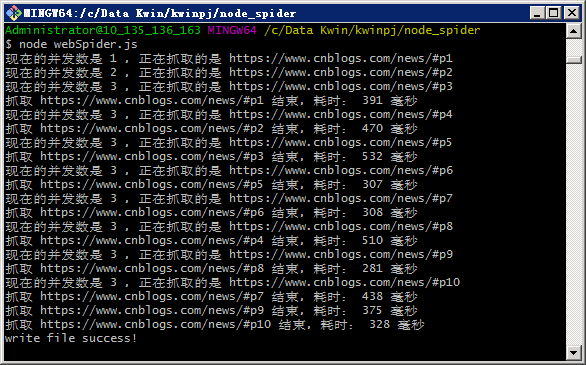
执行webSpider.js,
node webSpider.js
3. 总结
执行结果可以看到并发数依次增加,增加到3时不再继续增加,等待前面一条请求执行完成后才会请求下一条,这样的话,如果我们需要爬取1000条数据,就可以并发10条请求,慢慢爬完这1000个链接,这样就不用担心因并发太多被封IP这种情况发生了。完整代码已上传GitHub,有兴趣去试试吧!
Node爬虫之——使用async.mapLimit控制请求并发的更多相关文章
- node 爬虫 --- 批量下载图片
步骤一:创建项目 npm init 步骤二:安装 request,cheerio,async 三个模块 request 用于请求地址和快速下载图片流. https://github.com/reque ...
- node爬虫扒小说
Step 1: 万年不变的初始化项目,安装依赖 cnpm i express cheerio superagent superagent-charset async -S express 就不用多说 ...
- node爬虫(转)
我们先来看看今天的目标: mmjpg.com的美腿频道下的图片 一.实现步骤 使用superagent库来获取页面分析页面结构,使用cheerio 获取有效信息保存图片到本地开撸不断优化 这儿我们用到 ...
- 简单的node爬虫练手,循环中的异步转同步
简单的node爬虫练手,循环中的异步转同步 转载:https://blog.csdn.net/qq_24504525/article/details/77856989 看到网上一些基于node做的爬虫 ...
- 继续node爬虫 — 百行代码自制自动AC机器人日解千题攻占HDOJ
前言 不说话,先猛戳 Ranklist 看我排名. 这是用 node 自动刷题大概半天的 "战绩",本文就来为大家简单讲解下如何用 node 做一个 "自动AC机&quo ...
- Node爬虫
Node爬虫 参考 http://www.cnblogs.com/edwardstudy/p/4133421.html 所谓的爬虫就是发送请求,并将响应的数据做一些处理 只不过不用浏览器来发送请求 需 ...
- node爬虫(简版)
做node爬虫,首先像如何的去做这个爬虫,首先先想下思路,我这里要爬取一个页面的数据,要调取网页的数据,转换成页面格式(html+div)格式,然后提取里面独特的属性值,再把你提取的值,传送给你的页面 ...
- node爬虫的几种简易实现方式
说到爬虫大家可能会觉得很NB的东西,可以爬小电影,羞羞图,没错就是这样的.在node爬虫方面,我也是个新人,这篇文章主要是给大家分享几种实现node 爬虫的方式.第一种方式,采用node,js中的 s ...
- 自己写的服务出现"服务没有及时响应启动或控制请求 1053" 错误
自己写了一个服务,安装到电脑上后 启动时发现报"服务没有及时响应启动或控制请求 1053" 这个错误 在网上找了一些方法,都没有解决 后来,看了下,原来有个写文件的方法读取文件没有 ...
随机推荐
- EK算法复杂度分析
引理: EK算法每次增广使所有顶点$v\in V-\{s,t\}$到$s$的最短距离$d[v]$增大. 采用反证法, 假设存在一个点$v\in V-\{s,t\}$, 使得$d'[v]< d[v ...
- Linux命令详解-install
install命令的作用是安装或升级软件或备份数据,它的使用权限是所有用户. 1.命令格式: (1)install [选项]... 来源 目的地 (2)install [选项]... 来源... 目录 ...
- [转]Linux下彻底卸载mysql详解
http://www.jb51.net/article/97516.htm 一.使用以下命令查看当前安装mysql情况,查找以前是否装有mysql 1 rpm -qa|grep -i mysql 可以 ...
- 无法安装64位版本的office因为在您的pc
无法安装64位版本的office因为在您的pcWindows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\Installer\Products\00 ...
- RabbitMq window下配置安装
1. 搭建环境 1.1 安装Erlang语言运行环境 由于RabbitMQ使用Erlang语言编写,所以先安装Erlang语言运行环境. 1.2 Erlang(['ə:læŋ])是一种通用的面向并发的 ...
- Scrum立会报告+燃尽图 07
作业要求[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2289] 版本控制:https://git.coding.net/liuyy08 ...
- win7下解压安装mysql的方法
在win7下通过解压安装mysql 5.7一直出现启动不成功,网上找了好久终于找到一个解决方法,记录一下: 1.解压下载的压缩包 2.在解压目录下,将my-default.ini改名为my.ini, ...
- ubuntu14.04安装Android Studio出现error while loading shared libraries: libz.so.1的解决方法
参考博客地址: http://blog.csdn.net/newairzhang/article/details/28656693 安装lib32z1就可以解决,如下: 首先,sudo apt-get ...
- 本地代码同步到github
1 设置 ssh 公钥信息 首先你要确保 github 账号设置了ssh 公钥信息.如果没有的话可以按照下面的方式设置: 前往 github 网站的 account settings, 依次点击 Se ...
- Git 将代码恢复到一个历史的版本
Git 将代码恢复到一个历史的版本 要把代码回到某个历史版本 比如 test有两种方法 暴力的方式 如果你的仓库是自己在用(不影响别人),那么你可以使用 git reset --hard <ta ...