python基础之 time,datetime,collections
1.time模块
python中的time和datetime模块是时间方面的模块 time模块中时间表现的格式主要有三种:
1、timestamp:时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
2、struct_time:时间元组,共有九个元素组。
3、format time :格式化时间,已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
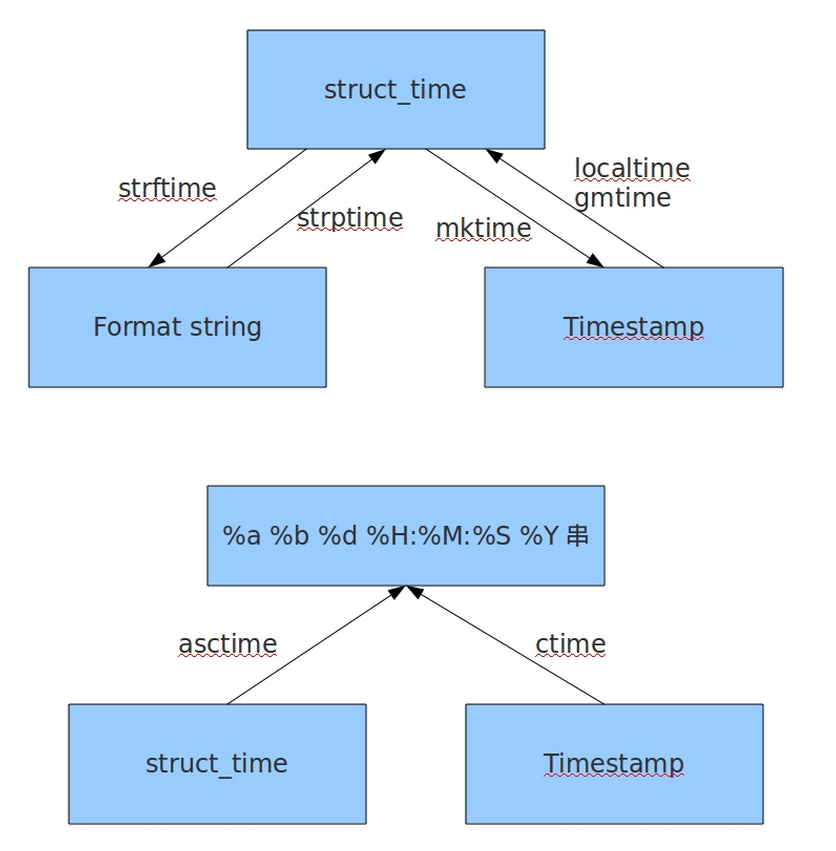
time的生成方法和time格式的转换
生成时间
import time
生成时间戳格式的时间:
print(time.time()) #是机器看的时间,拿到的是float类型的
time = 1553066161.9998 生成结构化格式的时间:
print(time.localtime()) #用在修改时间是使用的,得到一个命名元祖time.struct_time
time = time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=15, tm_min=16, tm_sec=1, tm_wday=2, tm_yday=79, tm_isdst=0) 生成字符串格式的时间:
print(time.strftime('%Y-%m-%d %H;%M:%S')) #或者'%Y-%m-%d %X/x
time = 2019-03-20 15:17:04 时间格式转换
注意:字符串格式的时间不能与时间戳格式的时间相互转换 转换顺序:字符串时间 <----->结构化时间<---->时间戳
字符串时间---->结构化时间
t = '2018-11-30 12:30:00'
f = time.strptime(t,'%Y-%m-%d %H:%M':%S) 结构化时间---->字符串时间
t = time.localtime()
f = time.strftime('%Y-%m-%d %H:%M:%S',t) 结构化时间---->时间戳时间
t = time.localtime()
f = (time.mktime(t)) 时间戳时间---->格式化时间
t = time.time()
f = time.localtime(t) 注意:
time.strftime() #获取当前字符串时间
timt.time()=1553052418.0508 #获取当时间时间戳
时间戳--结构化 time.localtime(time.time())
结构化--时间戳 time.mktime(f) #f =time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=11, tm_min=25, tm_sec=56, tm_wday=2, tm_yday=79, tm_isdst=0)
结构化--字符串 time.strftime('%Y-%m-%d %H:%M:%S',f) f=结构化时间 格式可以少写
字符串--结构化 f =time.strptime('2019-03-20 10:40:00','%Y-%m-%d %H:%M:%S') 格式可以少写
time模块练习
t = time.time() #获取当前时间戳
t1 = t - 30*86400 #按照30天算,求出30天之前的时间戳
old_time = time.localtime(t1) #将时间戳时间转换成字符串时间
print(time.strftime('%Y-%m-%d %X',old_time))
求当前时间的前一个月的现在时间
t = '2018-11-30 12:30:00'
t1 = time.strptime(t,'%Y-%m-%d %H:%M:%S') #将字符串时间转成格式化时间
t2 =time.mktime(t1 ) + 60*60*2 #将格式化时间转成时间戳+7200秒
t3 = time.localtime(t2)
print(time.strftime('%Y-%m-%d %H:%M:%S',t3))
将当前时间加2个小时
2.datetime模块
from datetime import datetime ,timedelta
f =datetime.now() #精确到毫秒 datetime.now()拿到的是时间对象
f1=datetime.timestamp(f) #将时间对象转成时间戳
f2=datetime.fromtimestamp(f1) #将时间戳转换成时间对象
f3= datetime.strptime('1984-1-29','%Y-%m-%d') #将字符串转成时间戳
f5 = datetime.strftime(f,'%Y-%m-%d') #将时间对象转成字符串 当前时间减去2个小时
print(datetime.now() - timedelta(hours=2)) #这个是datetime的精华 注意;datetime没有结构化时间
注意:将a格式的转化为b格式的时间,就应该用b将a包起来,比如将结构化的时间转成字符串时间print(time.strftime('%Y-%m-%d %X',time.localtime()))
3.数据结构的补充(官方文档)
Counter:计数器
引入模块:from collections import Counter
Counter 集成于 dict 类,因此也可以使用字典的方法,此类返回一个以元素为 key 、元素个数为 value 的 Counter 对象集合 #读取history中执行过最多的十条命令
import os
from collections import Counter
c = Counter()
with open(os.path.expanduser('~/.bash_history')) as cmd_info:
for line in cmd_info:
cmd = line.strip().split()
if cmd:
c[cmd[0]]+=1
print(c.most_common(10)) 常用操作:
sum(c.values()) # 所有计数的总数
c.clear() # 重置Counter对象,注意不是删除
list(c) # 将c中的键转为列表
set(c) # 将c中的键转为set
dict(c) # 将c中的键值对转为字典
c.items() # 转为(elem, cnt)格式的列表
Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象
c.most_common()[:-n:-1] # 取出计数最少的n-1个元素
c += Counter() # 移除0和负值
文章
nametuple:命名函数
引入模块:from collections import namedtuple
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便 #当元组的元素较多时们就可以使用命名元组来明确标明每个元素是什么意思
tu = namedtuple('people',['name','age','sex','hobby']) #是一个类
print(tu('kobe','','man','抽烟,喝酒烫头'))
ll =tu('kobe','','man','抽烟,喝酒烫头') #实例化一个类。对象
print(ll.name) #调用名字之后返回值
deque:双端队列
导入模块
from collections import deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。deque是为了高效实现插入和删除操作的双向列表。
适合用于队列和栈: #增
d = deque([1,2,3,4,5])
d.append(10)
print(d)
d.appendleft(-10)
print(d)
d.insert(2,9999) #在索引为2的地方添加999
print(d)
#删
print(d.pop())
print(d.popleft()) deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict:默认字典
导入模块:from collections import defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict: from collections import defaultdict
dd = defaultdict(lambda: 'N/A')
dd['key1'] = 'abc'
dd['key1'] # key1存在
'abc'
dd['key2'] # key2不存在,返回默认值
'N/A' 注意:默认值是调用函数返回的,而函数在创建defaultdict对象时传入。除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
ordereddict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d)
{'a': 1, 'c': 3, 'b': 2} #dict的key是无序的
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
OrderedDict([('a', 1), ('b', 2), ('c', 3)]) #OrderedDict的key是有序的
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序: >>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
other
双端队列和列表的区别:表现在效率,底层的数据结构上 向列表最后一个地方存值和删除都是非常快的 尽量写append() pop(),
列表中删除第一个或使用insert插入一个数据是非常耗费性能的,再删除的时候,后面的值都要向上和之前未删除的连接起来,
在插入的时候,在插入位置后面的数据都要向下后移一个位置,所以尽量写append() pop(),不要写insert和pop(0) 如果从中间插入或者删除比较频繁的操作使用:双端队列
如果单纯的增加append和删除pop的话,使用列表最好,但是尽量别使用pop(0)或者insert(1,'')等
列表的sort()和sorted()的区别是什么?
一个在原有的基础上进行修改, alist.sort()
一个是生成一个新的列表 返回一个新的列表 sorted(),但是alist.sort(更节省内存)
list提供的方法都是修改这个列表本身
注意:reversed返回一个生成器
内置函数是在已有序列的基础上,再生成一个新的
filter zip map等内置函数返回的都是生成器或迭代器,为的就是节省内存
python基础之 time,datetime,collections的更多相关文章
- python基础--time和datetime模块
一:说明在Python中,通常有这几种方式来表示时间:1)时间戳 2)格式化的时间字符串 3)元组(struct_time)共九个元素.由于Python的time模块实现主要调用C库,所以各个平台可能 ...
- python 基础 7.1 datetime 获得时间
一 datatime 的使用 object timedeta tzinfo time data dat ...
- Day13 Python基础之time/datetime/random模块一(十一)
time模块 import time print(help(time)) time.time() #return current time in seconds since the Epoch as ...
- Python基础、collections补充
collections collections是Python数据类型的补充,可以实现Counter计数.可命名元组(namedtuple).默认字典.有序字典.双向队列等功能 参考:http://py ...
- Python基础教程【读书笔记】 - 2016/7/31
希望通过博客园持续的更新,分享和记录Python基础知识到高级应用的点点滴滴! 第十波:第10章 充电时刻 Python语言的核心非常强大,同时还提供了更多值得一试的工具.Python的标准安装包括 ...
- python基础系列教程——Python3.x标准模块库目录
python基础系列教程——Python3.x标准模块库目录 文本 string:通用字符串操作 re:正则表达式操作 difflib:差异计算工具 textwrap:文本填充 unicodedata ...
- 一、python基础相关知识体系
python基础 a. Python(解释型语言.弱类型语言)和其他语言的区别? 一.编译型语言:一次性,将全部的程序编译成二进制文件,然后在运行.(c,c++ ,go) 运行速度快.开发效率低 二. ...
- python基础 — 致初学者的天梯
Python简介 Python是一种计算机程序设计语言.是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新 功能的添加,越来越多被用于独立的.大型项目 ...
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
随机推荐
- php获取两个时间戳之间相隔多少天多少小时多少分多少秒
/** * 返回两个时间的相距时间,*年*月*日*时*分*秒 * @param int $one_time 时间一 * @param int $two_time 时间二 * @param int $r ...
- beta冲刺1/7
目录 摘要 团队部分 个人部分 摘要 队名:小白吃 组长博客:hjj 作业博客:beta冲刺(1/7) 团队部分 后敬甲(组长) 过去两天完成了哪些任务 团队完成测试答辩 整理博客 复习接口 接下来的 ...
- cmd应用基础 扫盲教程
cmd是什么? 对于程序员而言,cmd命令提示符是windows操作系统下一个比较重要的工具.对于程序员而言,为了追求更高的效率而抛弃花俏的界面已然是意见很常见的行为,截止到目前的,全世界仍有大量的服 ...
- windows应用程序框架及实例
应用程序框架:同一类型应用程序的结构大致相同,并有很多相同的源代码,因此可以通过一个应用程序框架AFX(Application FrameWorks)编写同一类型应用程序的通用源代码. 主要向导: D ...
- 在页面上获取web项目信息
获取协议名称:request.getScheme() 获取域名:request.getServerName() 获取项目名称:request.getContextPath() 使用EL表达式获取项目名 ...
- __x__(15)0906第三天__超链接
HTML5 中的新属性. 属性 值 描述 charset char_encoding HTML5 中不支持.规定被链接文档的字符集. coords coordinates HTML5 中不支持.规定链 ...
- __x__(48)0910第六天__CSS Hack
CSS Hack: 不到万不得已,不要使用.不易于维护. 有一些情况,需要一段特殊代码在遇到特殊浏览器环境才执行,而在其他条件下,不执行. 此时,CSS Hack 就能实现. CSS Hack 实际上 ...
- php中的public、protected、private三种访问控制模式及self和parent的区别(转)
php的public.protected.private三种访问控制模式的区别 public: 公有类型 在子类中可以通过self::var调用public方法或属性,parent::method调用 ...
- 小程序上拉加载更多数据(onReachBottom)
<!--pages/test/test.wxml--> <block wx:for="{{list}}" wx:key="item.id"&g ...
- PHP 可以获取客户端哪些访问信息---来自网页转载
php是一种弱类型的程序语言,但是最web的 在程序语言中有系统全局函数: $_SERVER <?php echo "".$_SERVER['PHP_SELF'];#当前正在 ...