sql多行多列重复
在sql的查询中我们会遇到查询的结果比如这样的:
查询这张表的sql语句:
select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID
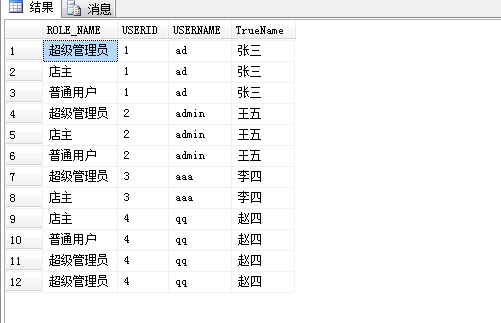
就拿钱三行来说就一个ROLE_NAME不一样其他的列的数值都是一样的难道我们就要这样的结果,就算我们要这样的结果但是当我们想要在前台这样显示一个页面的时候我们怎么办
这样的话我们该怎么去查询该怎么组合,把它分开来查询当然也能解决,但是想想那样我们要查询多少次要连接数据库对少次。
这样想想就觉得很麻烦当然想想也知道这样做肯定是降低了程序的执行效率。所以我们就应该想另一种方法怎样查询一次就可以变成这种效果。
想想看我们查询的结果是一张表那我们就看这张表的XML文件的组成是什么样的
查看表的组成的XML文件的sql语句:
select * from (select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t for XML path
查出表的XML文件的组成
想想看如果我们可以替换XML文件的组成的话我们是不是就可以改变表的结构了
我们先看一个简单的表,多行的重复是怎么合并的
select * from table1
查询结果:

看看这样的一个简单的表我们是怎样合并相同的列的
第一步:当然是查看表的XML文件看看表是怎样组成的
select * from table1 for XML path;
查询的结果:
<row>
<uid>1</uid>
<rname>管理员</rname>
</row>
<row>
<uid>1</uid>
<rname>店主</rname>
</row>
<row>
<uid>1</uid>
<rname>买家</rname>
</row>
<row>
<uid>2</uid>
<rname>店主</rname>
</row>
<row>
<uid>2</uid>
<rname>店主</rname>
</row>
根据查询的结果我们不难看出表的组成的简单结构,可能是数据库自己定义好的也可能是我们在查询的时候自动生成的,不管是定义好的还是自己生成的我们先看看是否可以改变表的组成结构如果可以的话我们是不是就可以改变我们想要的结构呢?
第二步:改变表的组成结构
select * from table1 for XML path;
还是这句语句既然可以查询表的XML文件组成那是否可以改变表的XML文件的组成呢。试试就知道了(程序就是你想的再多不如你敲几行代码一试)
select * from table1 for XML path('a');
我们这样写语句看看我们的表的XML文件的组成变成了什么样:
<a>
<uid>1</uid>
<rname>管理员</rname>
</a>
<a>
<uid>1</uid>
<rname>店主</rname>
</a>
<a>
<uid>1</uid>
<rname>买家</rname>
</a>
<a>
<uid>2</uid>
<rname>店主</rname>
</a>
<a>
<uid>2</uid>
<rname>店主</rname>
</a>
比较两次的查询结果看看我们的表的XML文件发生了什么变化:
select * from table1 for XML path; XML文件:
<row>
<uid>1</uid>
<rname>管理员</rname>
</row> select * from table1 for XML path('a'); XML文件的组成:
<a>
<uid>1</uid>
<rname>管理员</rname>
</a>
可以产出<row>标签变成了<a>,那么我们把path('a')中的a去掉会变成什么样:
查询语句:
select * from table1 for XML path('');
查询结果:
<uid>1</uid>
<rname>管理员</rname>
<uid>1</uid>
<rname>店主</rname>
<uid>1</uid>
<rname>买家</rname>
<uid>2</uid>
<rname>店主</rname>
<uid>2</uid>
<rname>店主</rname>
比较两次的查询结果:
select * from table1 for XML path('a');
查询结果:
<a>
<uid>1</uid>
<rname>管理员</rname>
</a>
select * from table1 for XML path('');
查询结果:
<uid>1</uid>
<rname>管理员</rname>
可以看出<a>去掉了,我们想要的是什么是用户的角色那我们就要角色看看:
第三步:去掉多余的行
select rname from table1 for XML path('');
查询的结果:
<rname>管理员</rname>
<rname>店主</rname>
<rname>买家</rname>
<rname>店主</rname>
<rname>店主</rname>
当然这仍然不是我们想要的结果我们想要的里面的数据,所以我们需要去掉<rname>标签:
第四步:去掉不要的标签:
select rname+',' from table1 for XML path('');
查询的结果:
管理员,店主,买家,店主,店主,
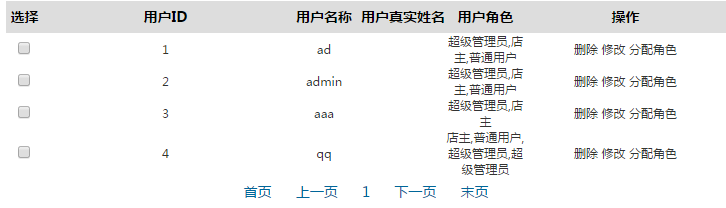
这就是我们想要的结果了,结果是拿到了但是我们想要的是什么效果啊,先看看我们们想要的表是什么样的

这是我们想要的表,但是怎么组成呢?
再看看我们原来的表:

想想看我们应该把这张表变形:
uid是多行的那我们就先不看rname这一列,我们先进行分组:
第五步:分组
根据uId进行分组
select uid from table1 group by uid
结果:

好,最重要的一步来了:
我们怎么把管理员,店主,买家,放在对应uid为1的一行,怎么把店主,店主,放在对应的uid为2的一行后面
第六步:合并:
也就是在这个表的后面添加一列。这样就简单了
select uid,(这一列就是rname)from table1 t group by uid;
那我们就增加一列:
上面我们的查询时查询所有的列现在我们加上条件:
select rname+',' from table1 t1 where t1.uid=1 for XML path('');
查询结果:
管理员,店主,买家,
这不就是我们想要的嘛,只要把条件改变一下就可以了嘛,现在我们进行合并也就是增加一列。
select uid,(这一列就是rname)from table1 t group by uid;
增加rname这一列:
select uid,(select rname+',' from table1 t1 where t1.uid=t.uid for XML path('')) as rname from table1 t group by uid;
我们看看这个语句的查询结果是什么?
select uid,(select rname+',' from table1 t1 where t1.uid=t.uid for XML path('')) as rolenames from table1 t group by uid;
结果:

这就是我们想要的结果了。
好了简单表的组成会了我们来点复杂的
继续完成我们刚开始提出的问题:
合成这张表试试看
查询语句:
select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID

我们该怎么合并这张表呢。仔细想想看其实道理是一样的我们直接把这张表当让是table1表,在往刚刚的sql语句一套不就行了
看看刚才的sql语句:
select uid,(select rname+',' from table1 t1 where t1.uid=t.uid for XML path('')) as rolenames from table1 t group by uid;
看看哪里用到了table1我们改变一下就行了
select uid,(select rname+',' from (table1表) t1 where t1.uid=t.uid for XML path('')) as rolenames from (table1表) t group by uid;
再根据我们的表看一看也就是改变一下查询的列的问题:
我们改变一下
select USERID,(select t.ROLE_NAME+',' from (table1表))t where t.USERID=t1.USERID for XML path('')) as RoleName from(table1表)t1 group by USERID,TrueName,USERNAME
好了把我们的“table1表”放进去,执行一下看看什么结果
select USERID,(select t.ROLE_NAME+',' from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t where t.USERID=t1.USERID for XML path('')) as RoleName from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t1 group by USERID
查询结果:

可是跟上面的表比较一下我们的表少了几列所以我们要把少的几列加上:
select USERID,TrueName,USERNAME,(select t.ROLE_NAME+',' from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t where t.USERID=t1.USERID for XML path('')) as RoleName from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t1 group by USERID,TrueName,USERNAME
看看查询的结果是不是我们想要的

在这里一定要注意一下group by 后面的语句,虽然我们写那么多的分组条件就只是第一个条件及作用我们仍然要写因为只有这样我们在查询的时候才可以去查询想要的列。
所以当你想要的查询其他的列的时候你就需要在group by 后面加上此列。
sql多行多列重复的更多相关文章
- sql的行转列(PIVOT)与列转行(UNPIVOT) webapi 跨域问题 Dapper 链式查询 扩展 T4 代码生成 Demo (抽奖程序)
sql的行转列(PIVOT)与列转行(UNPIVOT) 在做数据统计的时候,行转列,列转行是经常碰到的问题.case when方式太麻烦了,而且可扩展性不强,可以使用 PIVOT,UNPIVOT比 ...
- Sql Server 行转列
--摘自百度 PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PIVOT(聚合函数(列) FOR 列 in (… ...
- sql的行转列(PIVOT)与列转行(UNPIVOT)
在做数据统计的时候,行转列,列转行是经常碰到的问题.case when方式太麻烦了,而且可扩展性不强,可以使用 PIVOT,UNPIVOT比较快速实现行转列,列转行,而且可扩展性强 一.行转列 1.测 ...
- 做图表统计你需要掌握SQL Server 行转列和列转行
说在前面 做一个数据统计和分析的项目,每天面对着各种数据,经过存储过程从源表计算汇总后需要写入中间结果表以提高数据使用效率,那么此时就需要用到行转列和列转行. 1.列转行 数据经过计算加工后会直接生成 ...
- SQL Server 行转列重温
转载自http://www.cnblogs.com/kerrycode/ 行转列,列转行是我们在开发过程中经常碰到的问题.行转列一般通过CASE WHEN 语句来实现,也可以通过 SQL SERVER ...
- sql server 行转列(转载)
SQL Server中行列转换 Pivot UnPivot PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PI ...
- sql server 行转列解决方案
主要应用case语句来解决行转列的问题 行转列问题主要分为两类 1)简单的行转列问题: 示例表: id sid course result 1 2005001 语文 ...
- sql server 行转列 Pivot UnPivot
SQL Server中行列转换 Pivot UnPivot 本文转自:张志涛 原文地址: http://www.cnblogs.com/zhangzt/archive/2010/07/29/17878 ...
- 【转载】SQL Server行转列,列转行
行转列,列转行是我们在开发过程中经常碰到的问题.行转列一般通过CASE WHEN 语句来实现,也可以通过 SQL SERVER 2005 新增的运算符PIVOT来实现.用传统的方法,比较好理解.层次清 ...
随机推荐
- 网络编程-Python高级语法-装饰器
理论:装饰器就是运行一个函数之前首先运行装饰器函数,python装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使用python装饰器的好处就是在不用更改原函数 ...
- 异常之Tomcat8
在部署新项目后,启动tomcat突然报出如下错误: 问题:Publishing failed Could not publish to the server. Cannot acquire J2EEF ...
- PostgreSQL自学笔记:1 初识 PostgreSQL
博主教材:李小威.清华大学出版社.<PostgreSQL 9.6 从零开始学> 博主操作系统系统:Windows10 博主PostgreSQL版本:PostgreSQL 9.6 和 Pos ...
- [Python]sort与sorted高级技巧
与其他语言不同,python 3.0之后,弃用了其他语言中常见的cmp方法,在sort方法中改用key实现. 之前一直疑惑自定义对象的排序如何写comparator,最后发现还是通过内部的__cmp_ ...
- linux(debian) arm-linux-g++ v4.5.1交叉编译 embedded arm 版本的QtWebkit (browser) 使用qt 4.8.6 版本 以及x64上编译qt
最近需要做一个项目 在arm 架构的linux下 没有桌面环境的情况下拉起 有界面的浏览器使用. 考虑用qt 的界面和 qtwebikt 的库去实现这一系列操作. 本文参考: Qt移植到ARM Lin ...
- How to change Eclipse loading image
Eclipse IDE has many customize components, the splash welcome image (purple color loading image) is ...
- 使用JS获取input值
获取input值,设置input值 可以使用 $(".class") $("#id") $("input[name='name']") re ...
- python学习-01
1.编程语言分类: 编译型:(由编译器将代码编译成计算机识别的二进制文件)C \C++ \C# 运行速度较解释型语言快 解释型:(在运行时进行编译)python.php.sheel.ruby.j ...
- js 重写alert 兼容iphone使得alert 不带src
<script> window.alert = function(name){ var iframe = document.createElement("IFRAME" ...
- PHP编译报错
//usr/lib64/liblber-2.4.so.2: error adding symbols: DSO missing from command line collect2: error: l ...