利用phpspider爬取网站数据
本文实例原址:PHPspider爬虫10分钟快速教程
在我们的工作中可能会涉及到要到其它网站去进行数据爬取的情况,我们这里使用phpspider这个插件来进行功能实现。
1、首先,我们需要php环境,这点不用说。
2、安装composer,这个网上教程很多,这里不多做赘述,一面显得篇幅太长。
3、利用composer进行phpspider安装。
在安装的过程中,我们可能会遇到composer require长时间没反应的情况,这样的话。我们就需要换到中国镜像。方法如下:
镜像配置好后,我们就进行phpspider的安装了。
新建一个文件夹,这里暂时取名为composerInstallDemo。
打开文件夹,并在文件夹地址栏中输入“cmd”直接进入该文件夹的cmd模式。

再在dos窗口中输入一下命令:
composer require owner888/phpspider
出现一下界面,则证明,phpspider已经安装成功。

4、编写自己的第一个爬虫程序。
打开composerInstallDemo文件夹,在文件夹下新建一个php文件(名字随意,这里我创建的是index.php)
<?php
require '/vendor/autoload.php';
use phpspider\core\phpspider;
/* Do NOT delete this comment */
/* 不要删除这段注释 */
$configs = array(
'name' => '简书',
'log_show' =>false,
'tasknum' => 1,
//数据库配置
'db_config' => array(
'host' => '127.0.0.1',
'port' => 3306,
'user' => 'root',
'pass' => '',
'name' => 'demo',
),
'export' => array(
'type' => 'db',
'table' => 'jianshu', // 如果数据表没有数据新增请检查表结构和字段名是否匹配
),
//爬取的域名列表
'domains' => array(
'jianshu',
'www.jianshu.com'
),
//抓取的起点
'scan_urls' => array(
'https://www.jianshu.com/c/V2CqjW?utm_medium=index-collections&utm_source=desktop'
),
//列表页实例
'list_url_regexes' => array(
"https://www.jianshu.com/c/\d+"
),
//内容页实例
// \d+ 指的是变量
'content_url_regexes' => array(
"https://www.jianshu.com/p/\d+",
),
'max_try' => 5,
'fields' => array(
array(
'name' => "title",
'selector' => "//h1[@class='title']",
'required' => true,
),
array(
'name' => "content",
'selector' => "//div[@class='show-content-free']",
'required' => true,
),
),
);
$spider = new phpspider($configs);
$spider->start();
稍微解释一下一下句法的含义:
//h1[@class='title']
获取所有class值为title的h1节点
//div[@class='show-content-free']
获取所有class值为show-content-free的div节点
具体为什么这么写呢?自己看简书的html源码吧。
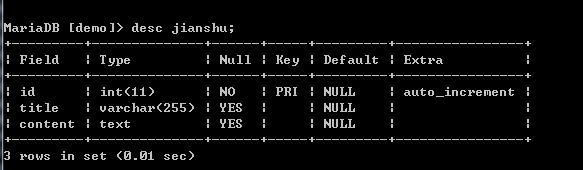
打完代码后,记得根据要抓取的内容建立对应的数据库、数据表,字段要能对对上。
数据库如下:
利用phpspider爬取网站数据的更多相关文章
- 利用linux curl爬取网站数据
看到一个看球网站的以下截图红色框数据,想爬取下来,通常爬取网站数据一般都会从java或者python爬取,但本人这两个都不会,只会shell脚本,于是硬着头皮试一下用shell爬取,方法很笨重,但旨在 ...
- Python 利用 BeautifulSoup 爬取网站获取新闻流
0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流: 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- C# 关于爬取网站数据遇到csrf-token的分析与解决
需求 某航空公司物流单信息查询,是一个post请求.通过后台模拟POST HTTP请求发现无法获取页面数据,通过查看航空公司网站后,发现网站使用避免CSRF攻击机制,直接发挥40X错误. 关于CSRF ...
- 手把手教你用Node.js爬虫爬取网站数据
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请自行百度 ...
- Node爬取网站数据
npm安装cheerio和axios npm isntall cheerio npm install axios 利用cheerio抓取对应网站中的标签根据链接使用axios获取对应页面数据 cons ...
- 3.15学习总结(Python爬取网站数据并存入数据库)
在官网上下载了Python和PyCharm,并在网上简单的学习了爬虫的相关知识. 结对开发的第一阶段要求: 网上爬取最新疫情数据,并存入到MySql数据库中 在可视化显示数据详细信息 项目代码: im ...
- 使用node.js如何爬取网站数据
数据库又不会弄,只能扒扒别人的数据了. 搭建环境: (1).创建一个文件夹,进入并初始化一个package.json文件. npm init -y (2).安装相关依赖: npm install ...
随机推荐
- 为ivew的Page组件的跳页增加跳页确定按钮
首次使用vue做后台管理项目,首次使用ivew框架,好不容易所有的功能都做完了,前几天产品经理让在每个列表的跳页后面加个‘确定’按钮,说没有确定按钮有点反人类,心想那还不分分钟的事儿嘛,立马回个‘好的 ...
- 转:浅谈SimpleDateFormat的线程安全问题
转自:https://blog.csdn.net/weixin_38810239/article/details/79941964 在实际项目中,我们经常需要将日期在String和Date之间做转化, ...
- SSM 记录
前言:本过程从0开始,先是导入最核心的jar包,然后随着ssm中的功能实现,打包===>启动===>报错,一步步解决问题,增加额外的必须的jar包来熟悉ssm 1.导包(核心包) myba ...
- 长时间关机测试脚本.VBS
Sub Main Dim cnt Dim delay Dim time Dim atttime atttime = 20 delay = 3000 time = 50 cnt_time=3 crt.s ...
- 对不可描述的软件安装sfbo插件
0 后来...突然有一天,我就需要sfbo了. 1 安装 yum search "不可描述插件"是空的,只能用源码安装. 官方信息可以链接到这里,obfs. 1.1 编译安装 gi ...
- linux-rhel7配置网卡bond双网卡主备模式
参考以下文章中的 2.centos7配置bonding: https://www.cnblogs.com/huangweimin/articles/6527058.html 以下是配置过程的操作和打印 ...
- Spring AOP功能和目标
1.AOP的作用 在OOP中,正是这种分散在各处且与对象核心功能无关的代码(横切代码)的存在,使得模块复用难度增加.AOP则将封装好的对象剖开,找出其中对多个对象产生影响的公共行为,并将其封装为一个可 ...
- C语言学习随笔记
第一次接触C语言,心中对新知识还是充满好奇的.最开始是从晓鹏老师那听说的C语言,记得当时晓鹏老师是在给我们介绍软考,叫我们去准备软考的时候说到了C语言告诉我们C语言是基础,C语言很重要,叫我们能学多好 ...
- 在linux服务器下JMeter如何执行jmx性能脚本
准备环境:linux平台.jmeter安装包. jdk 一. 安装jdk jdk的安装可以参考以下内容 http://jingyan.baidu.com/article ...
- 声明式开发 & 命令式开发
何为声明式开发,何又为命令式开发~~~ 这里我不做太多概念的剖析,我们只要明确一个: 声明式开发只是告诉计算机需要什么,而不是把每一步都计划好:典型代表为React: 命令式开发则是每一步明确的去操作 ...