使用python抓取App数据
App接口爬取数据过程
使用抓包工具
手机使用代理,app所有请求通过抓包工具
获得接口,分析接口
反编译apk获取key
突破反爬限制
需要的工具:
夜神模拟器
Fiddler
Pycharm
实现过程
首先下载夜神模拟器模拟手机也可以用真机,然后下载Fiddler抓取手机APP数据包,分析接口完成以后使用Python实现爬虫程序
Fiddler安装配置过程
第一步:下载神器Fiddler
Fiddler下载完成之后,傻瓜式的安装一下!
第二步:设置Fiddler
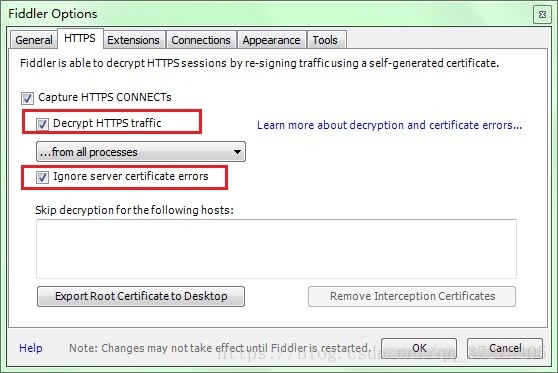
打开Fiddler, Tools-> Fiddler Options (配置完后记得要重启Fiddler)
选中”Decrpt HTTPS traffic”, Fiddler就可以截获HTTPS请求
选中”Allow remote computers to connect”. 是允许别的机器把HTTP/HTTPS请求发送到Fiddler上来
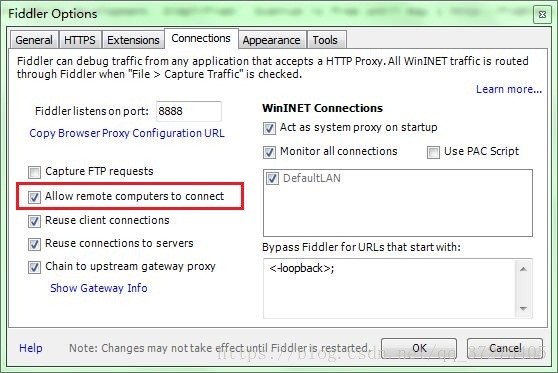
记住这个端口号是:8888
夜神模拟器安装配置过程
第一步:下载安装
夜神模拟器下载完成之后,傻瓜式的安装一下!
第二步:配置桥接 实现互通
首先将当前手机网络桥接到本电脑网络 实现互通
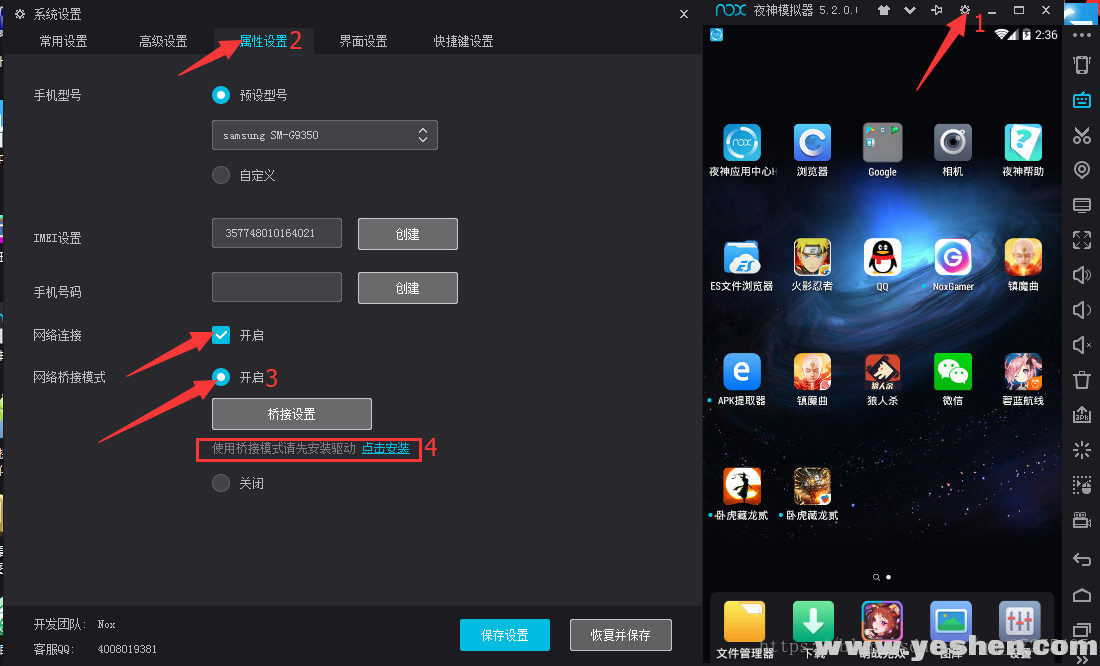
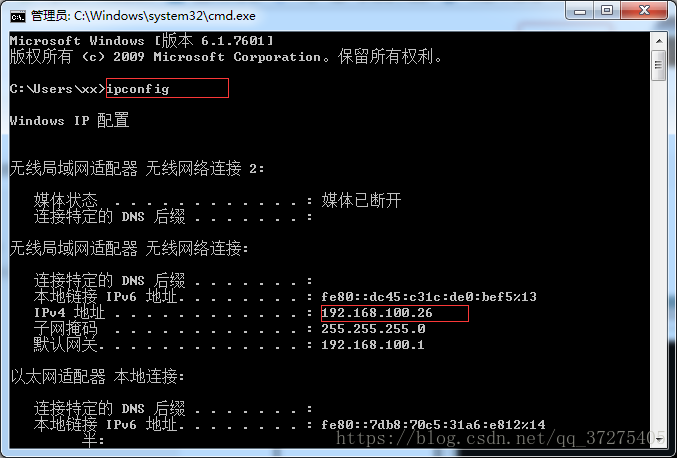
安装完成桥接驱动后配置IP地址,要配成和本机互通的网段,配置完成后打开主机cmd终端ping通ok
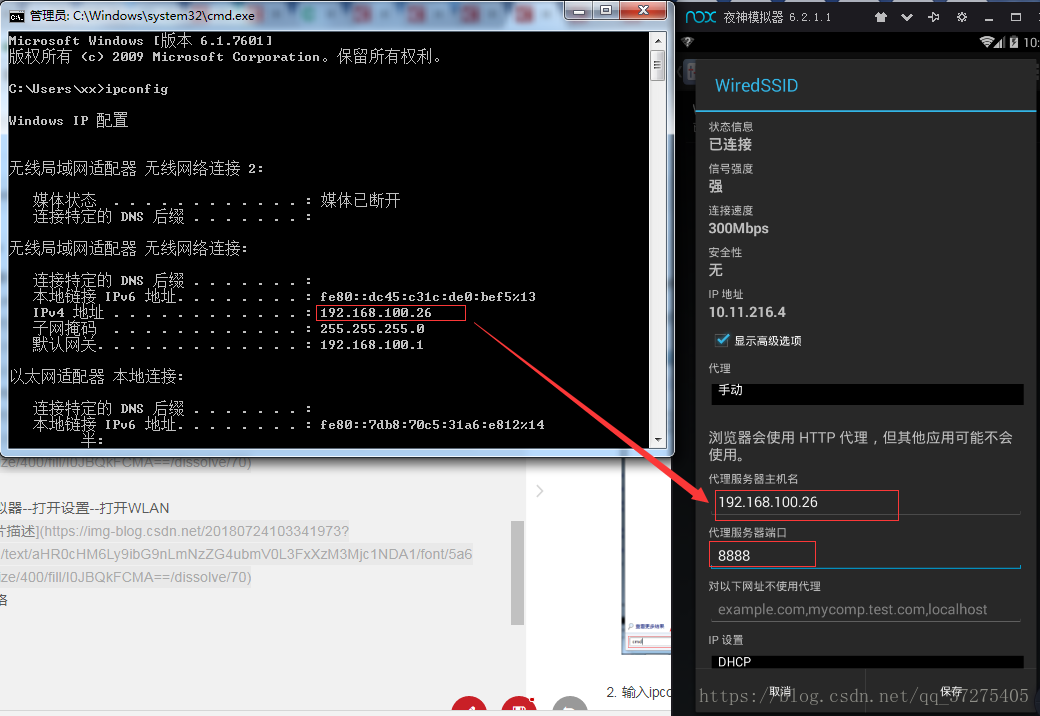
第三步:配置代理
- 打开主机cmd
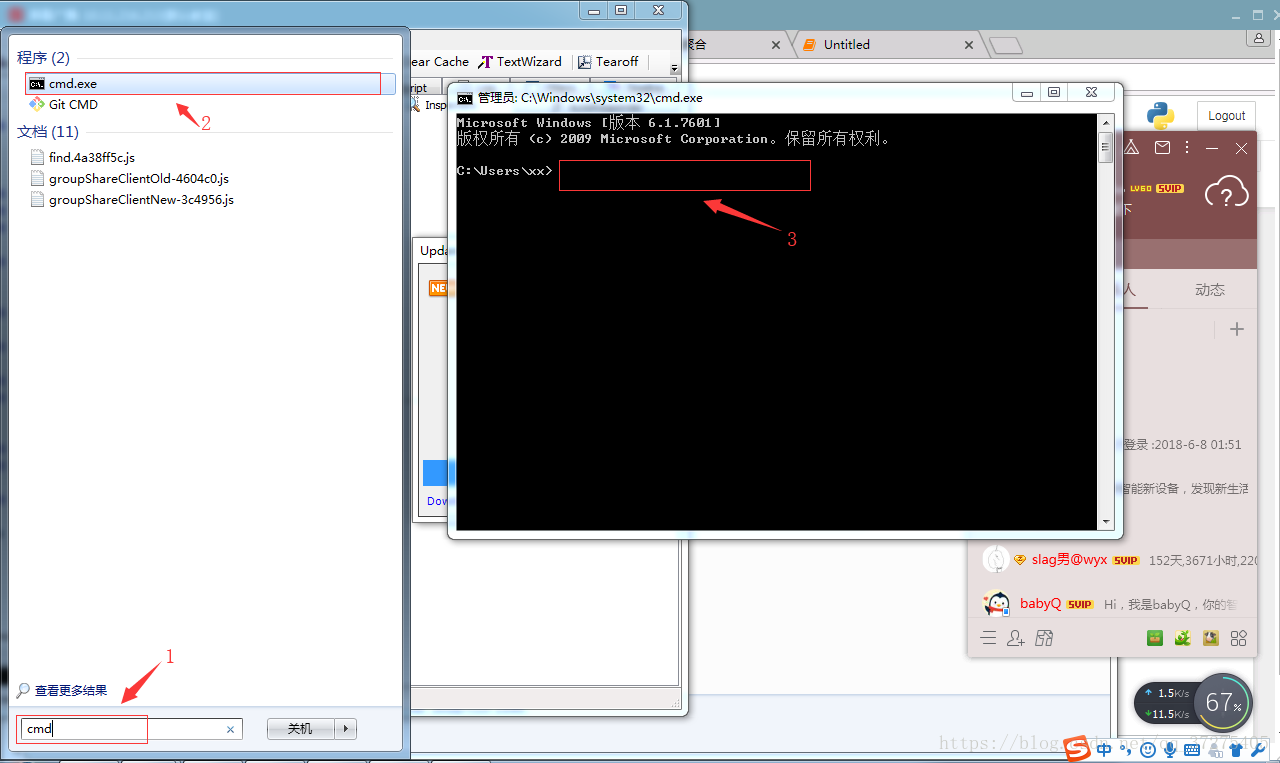
- 输入ipconfig查看本机IP
- 配置代理
进入夜神模拟器–打开设置–打开WLAN - 点击修改网络–配置代理 如下图:
配置完后保存
到这里我们就设置好所有的值,下面就来测试一下,打开手机的超级课程表APP - 在夜神模拟器上下载你想爬取得App使用Fiddler抓包分析api后使用python进行爬取就可以了
爬取充电网APP实例
爬取部分内容截图:
部分python代码分享:
import requests
import city
import json
import jsonpath
import recity_list = city.jsons
tags_list = city.Tagdef city_func(city_id):
try:
city = jsonpath.jsonpath(city_list, '$..sub[?(@.code=={})]'.format(int(city_id)))[0]["name"]
except:
city = jsonpath.jsonpath(city_list, '$[?(@.code=={})]'.format(int(city_id)))[0]["name"]
return citydef tags_func(tags_id):
tags_join = []
if tags_id:
for tags in tags_id:
t = jsonpath.jsonpath(tags_list,'$..spotFilterTags[?(@.id=={})]'.format(int(tags)))
tags_join.append(t[0]["title"])return ('-'.join(tags_join))
def split_n(ags):
return re.sub('\n',' ',ags)def request(page):
print('开始下载第%d页'%page)
url = 'https://app-api.chargerlink.com/spot/searchSpot'
two_url = "https://app-api.chargerlink.com/spot/getSpotDetail?spotId={d}"
head = {
"device": "client=android&cityName=%E5%8C%97%E4%BA%AC%E5%B8%82&cityCode=110106&lng=116.32154281224254&device_id=8A261C9D60ACEBDED7CD3706C92DD68E&ver=3.7.7&lat=39.895024107858724&network=WIFI&os_version=19",
"appId": "20171010",
"timestamp": "1532342711477",
"signature": "36daaa33e7b0d5d29ac9c64a2ce6c4cf",
"forcecheck": "1",
"Content-Type": "application/x-www-form-urlencoded",
"Content-Length": "68",
"Host": "app-api.chargerlink.com",
"Connection": "Keep-Alive",
"User-Agent": "okhttp/3.2.0"
}data = {
"userFilter[operateType]": 2,
"cityCode": 110000,
"sort": 1,
"page": page,
"limit": 10,
}response = requests.post(url,data=data,headers=head)
#获取数据
data = response.json()
for i in data['data']:
c = []
id = i['id']
name = i["name"] #充电桩名
phone = i["phone"] #手机号
num = i['quantity'] #有几个充电桩
city = city_func(i["provinceCode"]) #城市
tags =tags_func(i["tags"].split(','))#标签
message = c + [id,name,phone,num,city,tags]
parse_info(two_url.format(d=id),message)def parse_info(url,message):
#打开文件
with open('car.csv','a',encoding='utf-8')as c:
head = {
"device": "client=android&cityName=&cityCode=&lng=116.32154281224254&device_id=8A261C9D60ACEBDED7CD3706C92DD68E&ver=3.7.7&lat=39.895024107858724&network=WIFI&os_version=19",
"TOKEN": "036c8e24266c9089db50899287a99e65dc3bf95f",
"appId": "20171010",
"timestamp": "1532357165598",
"signature": "734ecec249f86193d6e54449ec5e8ff6",
"forcecheck": "1",
"Host": "app-api.chargerlink.com",
"Connection": "Keep-Alive",
"User-Agent": "okhttp/3.2.0",
}
#发起详情请求
res = requests.get(url,headers=head)
price = split_n(jsonpath.jsonpath(json.loads(res.text),'$..chargingFeeDesc')[0]) #价钱
payType = jsonpath.jsonpath(json.loads(res.text),'$..payTypeDesc')[0] #支付方式
businessTime =split_n(jsonpath.jsonpath(json.loads(res.text),'$..businessTime')[0]) #营业时间
result = (message + [price,payType,businessTime])
r = ','.join([str(i) for i in result])+',\n'
c.write(r)def get_page():
url = 'https://app-api.chargerlink.com/spot/searchSpot'
head = {
"device": "client=android&cityName=%E5%8C%97%E4%BA%AC%E5%B8%82&cityCode=110106&lng=116.32154281224254&device_id=8A261C9D60ACEBDED7CD3706C92DD68E&ver=3.7.7&lat=39.895024107858724&network=WIFI&os_version=19",
"appId": "20171010",
"timestamp": "1532342711477",
"signature": "36daaa33e7b0d5d29ac9c64a2ce6c4cf",
"forcecheck": "1",
"Content-Type": "application/x-www-form-urlencoded",
"Content-Length": "68",
"Host": "app-api.chargerlink.com",
"Connection": "Keep-Alive",
"User-Agent": "okhttp/3.2.0"
}data = {
"userFilter[operateType]": 2,
"cityCode": 110000,
"sort": 1,
"page": 1,
"limit": 10,
}
response = requests.post(url, data=data, headers=head)
# 获取数据
data = response.json()
total = (data["pager"]["total"])
page_Size = (data["pager"]["pageSize"])
totalPage = (data['pager']["totalPage"])
print('当前共有{total}个充电桩,每页展示{page_Size}个,共{totalPage}页'.format(total=total,page_Size=page_Size,totalPage=totalPage))
if __name__ == '__main__':
get_page()
start = int(input("亲,请输入您要获取的开始页:"))
end = int(input("亲,请输入您要获取的结束页:"))
for i in range(start,end+1):
request(i)
---------------------
作者:爱python的王三金
来源:CSDN
原文:https://blog.csdn.net/qq_37275405/article/details/81181439
版权声明:本文为博主原创文章,转载请附上博文链接!

使用python抓取App数据的更多相关文章
- Python 逆向抓取 APP 数据
今天继续给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固 ...
- fillder抓取APP数据之小程序
1.下载fillder ,fillder官网:https://www.telerik.com/fiddler 2.安装好后设置fillder: 工具—>选项,打开设置面板.选择HTTPS选项卡. ...
- Python3.x+Fiddler抓取APP数据
随着移动互联网的市场份额逐步扩大,手机APP已经占据我们的生活,以往的数据分析都借助于爬虫爬取网页数据进行分析,但是新兴的产品有的只有APP,并没有网页端这对于想要提取数据的我们就遇到了些问题,本章以 ...
- python 抓取金融数据,pandas进行数据分析并可视化系列 (一)
终于盼来了不是前言部分的前言,相当于杂谈,算得上闲扯,我觉得很多东西都是在闲扯中感悟的,比如需求这东西,一个人只有跟自己沟通好了,总结出某些东西了,才能更好的和别人去聊,去说. 今天这篇写的是明白需求 ...
- 利用python抓取页面数据
1.首先是安装python(注意python3.X和python2.X是不兼容的,我们最好用python3.X) 安装方法:安装python 2.安装成功后,再进行我们需要的插件安装.(这里我们需要用 ...
- python 抓取alexa数据
要抓取http://www.alexa.cn/rank/baidu.com网站的排名信息:例如抓取以下信息: 需要微信扫描登录 因为这个网站抓取数据是收费,所以就利用网站提供API服务获取json信息 ...
- 记录使用jQuery和Python抓取采集数据的一个实例
从现成的网站上抓取汽车品牌,型号,车系的数据库记录. 先看成果,大概4w条车款记录 一共建了四张表,分别存储品牌,车系,车型和车款 大概过程: 使用jQuery获取页面中呈现的大批内容 能通过页面一次 ...
- 利用Fidder工具抓取App数据包
第一步:下载神器Fiddler,下载链接: http://fiddler2.com/get-fiddler 下载完成之后,傻瓜式的安装一下了! 第二步:设置Fiddler打开Fiddler, ...
- 网络爬虫-使用Python抓取网页数据
搬自大神boyXiong的干货! 闲来无事,看看了Python,发现这东西挺爽的,废话少说,就是干 准备搭建环境 因为是MAC电脑,所以自动安装了Python 2.7的版本 添加一个 库 Beauti ...
随机推荐
- dotnet core test with NUnit
https://github.com/nunit/dotnet-test-nunit if you are using Visual Studio. Your project.json in your ...
- m_Orchestrate learning system---十一、thinkphp查看临时文件的好处是什么
m_Orchestrate learning system---十一.thinkphp查看临时文件的好处是什么 一.总结 一句话总结:可以知道thinkphp的标签被smarty引擎翻译而来的php代 ...
- MyBatis数据持久化(七)多表连接查询
本节继续以多表连接查询的案例介绍使用resultMap的好处,对于两张以上的表进行关联查询,当我们有选择的从不同表查询所需字段时,使用resultMap是相当方便的.例如我们有两张表,分别为用户表Us ...
- Avalon.js 实现列表
<table border="0" cellpadding="0" cellspacing="0" class="tab1& ...
- 【原创】TimeSten安装与配置
1.安装TimeSten 2.安装时要指定TNS_ADMIN_LOCATION,即tnsnames.ora的路径,因为tt会根据这个连接Oracle.C:\TimesTen\tt1122_32\net ...
- 获取新浪微博的Access_token
最近想爬取新浪微博的评论,百度了一下,有个新浪开放平台提供了这个API 于是按照它的说明,去获取Access_token: 1.点击微链接 2.立即创建微链接 3.选择网页应用 4.填写信息后提交 5 ...
- 使用IDEA在Maven中创建MyBatis逆向工程以及需要注意的问题(入门)
逆向工程简介: mybatis官方提供逆向工程,可以针对单表自动生成mybatis执行所需要的代码(mapper.java.mapper.xml.pojo…),可以让程序员将更多的精力放在繁杂的业务逻 ...
- BZOJ2225: [Spoj 2371]Another Longest Increasing CDQ分治,3维LIS
Code: #include <cstdio> #include <algorithm> #include <cstring> #define maxn 20000 ...
- LRU算法与LRUCache
关于LRU LRU(Least recently used,最近最少使用)算法是操作系统中一种经典的页面置换算法,当发生缺页中断时,需要将内存的一个或几个页面置换出,LRU指出应该将内存最近最少使用的 ...
- 集合(set)的基本操作
集合是一个无序的,不重复的数据组合,它的主要作用如下: 去重,把一个列表变成集合,就自动去重了 集合中的元素必须是不可变类型 关系测试,测试两组数据之前的交集.差集.并集等关系 常用操作 a = se ...