java+spark-sql查询excel
Spark官网下载Spark
Spark下载,版本随意,下载后解压放入bigdata下(目录可以更改)
下载Windows下Hadoop所需文件winutils.exe
同学们自己网上找找吧,这里就不上传了,其实该文件可有可无,报错也不影响Spark运行,强迫症可以下载,本人就有强迫症~~,文件下载后放入bigdata\hadoop\bin目录下。
不用创建环境变量,再Java最开始处定义系统变量即可,如下:
System.setProperty("hadoop.home.dir", HADOOP_HOME);
创建Java Maven项目java-spark-sql-excel
建立相关目录层次如下:
父级目录(项目所在目录)
- java-spark-sql-excel
- bigdata
- spark
- hadoop
- bin
- winutils.exe
编码
初始化SparkSession
static{
System.setProperty("hadoop.home.dir", HADOOP_HOME);
spark = SparkSession.builder()
.appName("test")
.master("local[*]")
.config("spark.sql.warehouse.dir",SPARK_HOME)
.config("spark.sql.parquet.binaryAsString", "true")
.getOrCreate();
}
读取excel
public static void readExcel(String filePath,String tableName) throws IOException{
DecimalFormat format = new DecimalFormat();
format.applyPattern("#");
//创建文件(可以接收上传的文件,springmvc使用CommonsMultipartFile,jersey可以使用org.glassfish.jersey.media.multipart.FormDataParam(参照本人文件上传博客))
File file = new File(filePath);
//创建文件流
InputStream inputStream = new FileInputStream(file);
//创建流的缓冲区
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
//定义Excel workbook引用
Workbook workbook =null;
//.xlsx格式的文件使用XSSFWorkbook子类,xls格式的文件使用HSSFWorkbook
if(file.getName().contains("xlsx")) workbook = new XSSFWorkbook(bufferedInputStream);
if(file.getName().contains("xls")&&!file.getName().contains("xlsx")) workbook = new HSSFWorkbook(bufferedInputStream);
System.out.println(file.getName());
//获取Sheets迭代器
Iterator<Sheet> dataTypeSheets= workbook.sheetIterator();
while(dataTypeSheets.hasNext()){
//每一个sheet都是一个表,为每个sheet
ArrayList<String> schemaList = new ArrayList<String>();
// dataList数据集
ArrayList<org.apache.spark.sql.Row> dataList = new ArrayList<org.apache.spark.sql.Row>();
//字段
List<StructField> fields = new ArrayList<>();
//获取当前sheet
Sheet dataTypeSheet = dataTypeSheets.next();
//获取第一行作为字段
Iterator<Row> iterator = dataTypeSheet.iterator();
//没有下一个sheet跳过
if(!iterator.hasNext()) continue;
//获取第一行用于建立表结构
Iterator<Cell> firstRowCellIterator = iterator.next().iterator();
while(firstRowCellIterator.hasNext()){
//获取第一行每一列作为字段
Cell currentCell = firstRowCellIterator.next();
//字符串
if(currentCell.getCellTypeEnum() == CellType.STRING) schemaList.add(currentCell.getStringCellValue().trim());
//数值
if(currentCell.getCellTypeEnum() == CellType.NUMERIC) schemaList.add((currentCell.getNumericCellValue()+"").trim());
}
//创建StructField(spark中的字段对象,需要提供字段名,字段类型,第三个参数true表示列可以为空)并填充List<StructField>
for (String fieldName : schemaList) {
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}
//根据List<StructField>创建spark表结构org.apache.spark.sql.types.StructType
StructType schema = DataTypes.createStructType(fields);
//字段数len
int len = schemaList.size();
//获取当前sheet数据行数
int rowEnd = dataTypeSheet.getLastRowNum();
//遍历当前sheet所有行
for (int rowNum = 1; rowNum <= rowEnd; rowNum++) {
//一行数据做成一个List
ArrayList<String> rowDataList = new ArrayList<String>();
//获取一行数据
Row r = dataTypeSheet.getRow(rowNum);
if(r!=null){
//根据字段数遍历当前行的单元格
for (int cn = 0; cn < len; cn++) {
Cell c = r.getCell(cn, Row.MissingCellPolicy.RETURN_BLANK_AS_NULL);
if (c == null) rowDataList.add("0");//空值简单补零
if (c != null&&c.getCellTypeEnum() == CellType.STRING) rowDataList.add(c.getStringCellValue().trim());//字符串
if (c != null&&c.getCellTypeEnum() == CellType.NUMERIC){
double value = c.getNumericCellValue();
if (p.matcher(value+"").matches()) rowDataList.add(format.format(value));//不保留小数点
if (!p.matcher(value+"").matches()) rowDataList.add(value+"");//保留小数点
}
}
}
//dataList数据集添加一行
dataList.add(RowFactory.create(rowDataList.toArray()));
}
//根据数据和表结构创建临时表
spark.createDataFrame(dataList, schema).createOrReplaceTempView(tableName+dataTypeSheet.getSheetName());
}
}
在项目目录下创建测试文件

第一个Sheet:
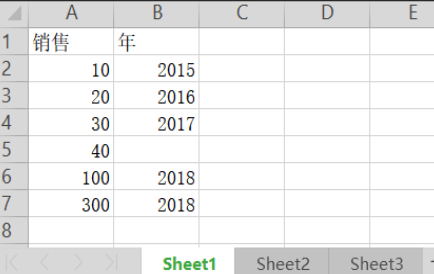
第二个Sheet:

第三个Sheet:
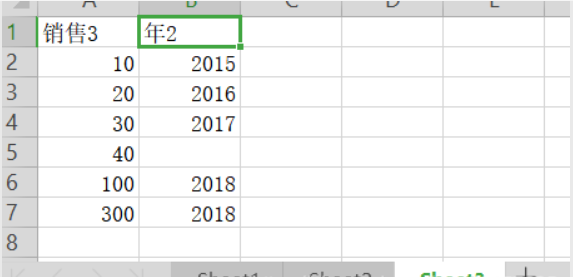
测试
public static void main(String[] args) throws Exception {
//需要查询的excel路径
String xlsxPath = "test2.xlsx";
String xlsPath = "test.xls";
//定义表名
String tableName1="test_table1";
String tableName2="test_table2";
//读取excel表名为tableNameN+Sheet的名称
readExcel(xlsxPath,tableName2);
spark.sql("select * from "+tableName2+"Sheet1").show();
readExcel(xlsPath,tableName1);
spark.sql("select * from "+tableName1+"Sheet1").show();
spark.sql("select * from "+tableName1+"Sheet2").show();
spark.sql("select * from "+tableName1+"Sheet3").show();
}
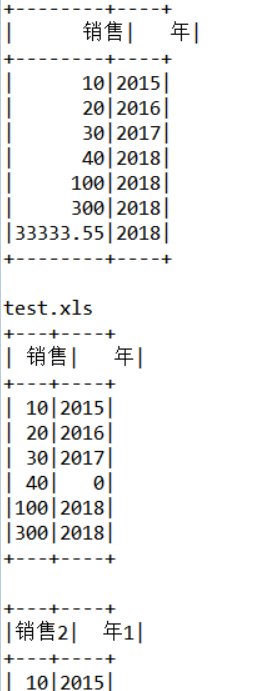
运行结果
相关依赖
<dependencies>
<dependency>
<groupId>org.spark-project.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1.spark2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
</dependencies>
java+spark-sql查询excel的更多相关文章
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 64位环境中使用SQL查询excel的方式解决
--64位环境中使用SQL查询excel的方式 环境: OS:Windows Server 2008 R2 Enterprise MSSQL:Microsoft SQL Server 2008 R2 ...
- Java 获取SQL查询语句结果
step1:构造连接Class.forName("com.mysql.jdbc.Driver"); Connection con = DriverManager.getConnec ...
- spark sql 查询hive表并写入到PG中
import java.sql.DriverManager import java.util.Properties import com.zhaopin.tools.{DateUtils, TextU ...
- 2. 执行Spark SQL查询
2.1 命令行查询流程 打开Spark shell 例子:查询大于21岁的用户 创建如下JSON文件,注意JSON的格式: {"name":"Michael"} ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- 从SQL查询分析器中读取EXCEL中的内容
很早以前就用sql查询分析器来操作过EXCEL文件了. 由于对于excel公式并不是很了解,所以很多时候处理excel中的内容,常常是用sql语句来处理的.[什么样的人有什么样的办法吧 :)] 今又要 ...
- Spark SQL基本概念与基本用法
1. Spark SQL概述 1.1 什么是Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为 ...
- spark第七篇:Spark SQL, DataFrame and Dataset Guide
预览 Spark SQL是用来处理结构化数据的Spark模块.有几种与Spark SQL进行交互的方式,包括SQL和Dataset API. 本指南中的所有例子都可以在spark-shell,pysp ...
- 理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的.使用这个函数执行SQL语句前需要 ...
随机推荐
- GoldenGate V11.1数据复制限制
以下对goldengate数据复制的限制情况进行说明. 不支持文件等非结构化数据复制 GoldenGate依赖对于数据库日志的解析获取数据变化,因此只能支持数据库中的数据变化复制,无法支持文件等非结构 ...
- Windows下安装Scrapy方法及常见安装问题总结——Scrapy安装教程
这几天,很多朋友在群里问Scrapy安装的问题,其实问题方面都差不多,今天小编给大家整理一下Scrapy的安装教程,希望日后其他的小伙伴在安装的时候不再六神无主,具体的教程如下. Scrapy是Pyt ...
- Vue代理&跨域
Vue 本地代理 纯前端技术解决跨域 vue-axios获取数据很多小伙伴都会使用,但如果前后端分离且后台没设置跨域许可,那要怎样才能解决跨域问题? 常用方法有几种: 通过jsonp跨域 通过修改do ...
- C# 从需要登录的网站上抓取数据
[转] C# 从需要登录的网站上抓取数据 背景:昨天一个学金融的同学让我帮她从一个网站上抓取数据,然后导出到excel,粗略看了下有1000+条记录,人工统计的话确实不可能.虽说不会,但作为一个学计算 ...
- hdu 1423 最长公共递增子序列 LCIS
最长公共上升子序列(LCIS)的O(n^2)算法 预备知识:动态规划的基本思想,LCS,LIS. 问题:字符串a,字符串b,求a和b的LCIS(最长公共上升子序列). 首先我们可以看到,这个问题具有相 ...
- QString::toStdString() crashes
今天在Qt中开发程序时,遇到一个QString::toStdString()的内存问题,用法如下: void test(const QString& theFileName) { std::s ...
- 在Qt 4.4中,Alien Widget诞生了(Window负责与窗口系统的联系。Alien被号称是所有闪烁的终结者)
2011年09月29日 23:47:46 阅读数:7269 Qt 4.0 automatically double-buffers Qt 4.1 QWidget::autoFillBackground ...
- Haproxy压测
目的:测试Haproxy压测情况 环境: Ha服务器:8核16G虚机,后端6个2核4G,压测客户端3个2核4G 安装和优化: 一.Haproxy #cd /opt/soft #wget http:// ...
- JavaWeb简单介绍
服务器端编程 技术种类 Servlet JSP Struts Spring Hibernate EJB Web Service Web服务器 IIS Apache Tomcat (提供对JSP和Ser ...
- HDU 5446 Unknown Treasure Lucas+中国剩余定理+按位乘
HDU 5446 Unknown Treasure 题意:求C(n, m) %(p[1] * p[2] ··· p[k]) 0< n,m < 1018 思路:这题基本上算是模版题了 ...