(转载)python应用svm算法过程
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类。因为Python中的sklearn库也集成了SVM算法,本文的运行环境是Pycharm。
一、导入sklearn算法包
Scikit-Learn库已经实现了所有基本机器学习的算法,具体使用详见官方文档说明:http://scikit-learn.org/stable/auto_examples/index.html#support-vector-machines。
skleran中集成了许多算法,其导入包的方式如下所示,
逻辑回归:from sklearn.linear_model import LogisticRegression
朴素贝叶斯:from sklearn.naive_bayes import GaussianNB
K-近邻:from sklearn.neighbors import KNeighborsClassifier
决策树:from sklearn.tree import DecisionTreeClassifier
支持向量机:from sklearn import svm
二、sklearn中svc的使用
(1)使用numpy中的loadtxt读入数据文件
loadtxt()的使用方法:

fname:文件路径。eg:C:/Dataset/iris.txt。
dtype:数据类型。eg:float、str等。
delimiter:分隔符。eg:‘,’。
converters:将数据列与转换函数进行映射的字典。eg:{1:fun},含义是将第2列对应转换函数进行转换。
usecols:选取数据的列。
以Iris兰花数据集为例子:
由于从UCI数据库中下载的Iris原始数据集的样子是这样的,前四列为特征列,第五列为类别列,分别有三种类别Iris-setosa, Iris-versicolor, Iris-virginica。
当使用numpy中的loadtxt函数导入该数据集时,假设数据类型dtype为浮点型,但是很明显第五列的数据类型并不是浮点型。
因此我们要额外做一个工作,即通过loadtxt()函数中的converters参数将第五列通过转换函数映射成浮点类型的数据。
首先,我们要写出一个转换函数:
|
1
2
3
|
def iris_type(s): it = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2} return it[s] |
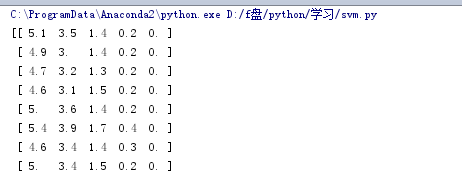
接下来读入数据,converters={4: iris_type}中“4”指的是第5列:
|
1
2
|
path = u'D:/f盘/python/学习/iris.data' # 数据文件路径data = np.loadtxt(path, dtype=float, delimiter=',', converters={4: iris_type}) |
读入结果:
(2)将Iris分为训练集与测试集
|
1
2
3
|
x, y = np.split(data, (4,), axis=1)x = x[:, :2]x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6) |
1. split(数据,分割位置,轴=1(水平分割) or 0(垂直分割))。
2. x = x[:, :2]是为方便后期画图更直观,故只取了前两列特征值向量训练。
3. sklearn.model_selection.train_test_split随机划分训练集与测试集。train_test_split(train_data,train_target,test_size=数字, random_state=0)
参数解释:
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
(3)训练svm分类器
|
1
2
3
|
# clf = svm.SVC(C=0.1, kernel='linear', decision_function_shape='ovr') clf = svm.SVC(C=0.8, kernel='rbf', gamma=20, decision_function_shape='ovr') clf.fit(x_train, y_train.ravel()) |
kernel='linear'时,为线性核,C越大分类效果越好,但有可能会过拟合(defaul C=1)。
kernel='rbf'时(default),为高斯核,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
decision_function_shape='ovr'时,为one v rest,即一个类别与其他类别进行划分,
decision_function_shape='ovo'时,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
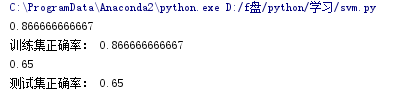
(4)计算svc分类器的准确率
|
1
2
3
4
5
6
|
print clf.score(x_train, y_train) # 精度y_hat = clf.predict(x_train)show_accuracy(y_hat, y_train, '训练集')print clf.score(x_test, y_test)y_hat = clf.predict(x_test)show_accuracy(y_hat, y_test, '测试集') |
结果为:
如果想查看决策函数,可以通过decision_function()实现
|
1
2
|
print 'decision_function:\n', clf.decision_function(x_train)print '\npredict:\n', clf.predict(x_train) |
结果为:


decision_function中每一列的值代表距离各类别的距离。
(5)绘制图像
1.确定坐标轴范围,x,y轴分别表示两个特征
|
1
2
3
4
5
|
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j] # 生成网格采样点grid_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点# print 'grid_test = \n', grid_testgrid_hat = clf.predict(grid_test) # 预测分类值grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同 |
这里用到了mgrid()函数,该函数的作用这里简单介绍一下:
假设假设目标函数F(x,y)=x+y。x轴范围1~3,y轴范围4~6,当绘制图像时主要分四步进行:
【step1:x扩展】(朝右扩展):
[1 1 1]
[2 2 2]
[3 3 3]
【step2:y扩展】(朝下扩展):
[4 5 6]
[4 5 6]
[4 5 6]
【step3:定位(xi,yi)】:
[(1,4) (1,5) (1,6)]
[(2,4) (2,5) (2,6)]
[(3,4) (3,5) (3,6)]
【step4:将(xi,yi)代入F(x,y)=x+y】
因此这里x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j]后的结果为:
再通过stack()函数,axis=1,生成测试点
2.指定默认字体
|
1
2
|
mpl.rcParams['font.sans-serif'] = [u'SimHei']mpl.rcParams['axes.unicode_minus'] = False |
3.绘制
|
1
2
3
4
5
6
7
8
9
10
11
12
|
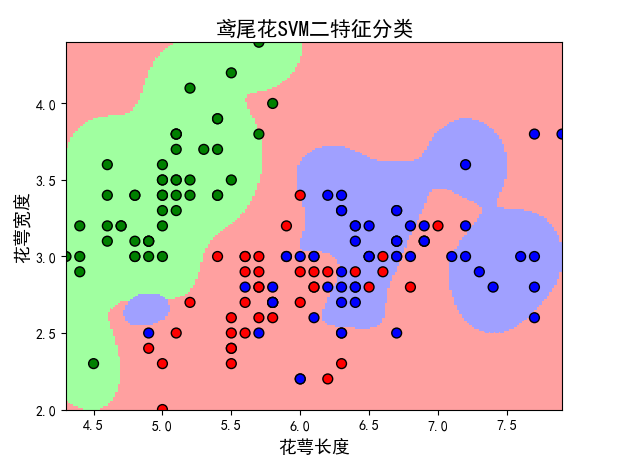
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light)plt.scatter(x[:, 0], x[:, 1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本plt.scatter(x_test[:, 0], x_test[:, 1], s=120, facecolors='none', zorder=10) # 圈中测试集样本plt.xlabel(u'花萼长度', fontsize=13)plt.ylabel(u'花萼宽度', fontsize=13)plt.xlim(x1_min, x1_max)plt.ylim(x2_min, x2_max)plt.title(u'鸢尾花SVM二特征分类', fontsize=15)# plt.grid()plt.show() |
pcolormesh(x,y,z,cmap)这里参数代入x1,x2,grid_hat,cmap=cm_light绘制的是背景。
scatter中edgecolors是指描绘点的边缘色彩,s指描绘点的大小,cmap指点的颜色。
xlim指图的边界。
最终结果为:
(转载)python应用svm算法过程的更多相关文章
- SVM: 使用kernels(核函数)的整个SVM算法过程
将所有的样本都选做landmarks 一种方法是将所有的training data都做为landmarks,这样就会有m个landmarks(m个trainnign data),这样features就 ...
- 转载 python多重继承C3算法
备注:O==object 2.python-C3算法解析: #C3 定义引用开始 C3 算法:MRO是一个有序列表L,在类被创建时就计算出来. L(Child(Base1,Base2)) = [ Ch ...
- 转载:scikit-learn学习之SVM算法
转载,http://blog.csdn.net/gamer_gyt 目录(?)[+] ========================================================= ...
- 转载 | Python AI 教学│k-means聚类算法及应用
关注我们的公众号哦!获取更多精彩哦! 1.问题导入 假如有这样一种情况,在一天你想去某个城市旅游,这个城市里你想去的有70个地方,现在你只有每一个地方的地址,这个地址列表很长,有70个位置.事先肯定要 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 转载 - Vim 的 Python 编辑器详细配置过程 (Based on Ubuntu 12.04 LTS)
出处:http://www.cnblogs.com/ifantastic/p/3185665.html Vim 的 Python 编辑器详细配置过程 (Based on Ubuntu 12.04 LT ...
- 程序员训练机器学习 SVM算法分享
http://www.csdn.net/article/2012-12-28/2813275-Support-Vector-Machine 摘要:支持向量机(SVM)已经成为一种非常受欢迎的算法.本文 ...
- Machine Learning in Action(5) SVM算法
做机器学习的一定对支持向量机(support vector machine-SVM)颇为熟悉,因为在深度学习出现之前,SVM一直霸占着机器学习老大哥的位子.他的理论很优美,各种变种改进版本也很多,比如 ...
- SVM算法
本文主要介绍支持向量机理论推导及其工程应用. 1 基本介绍 支持向量机算法是一个有效的分类算法,可用于分类.回归等任务,在传统的机器学习任务中,通过人工构造.选择特征,然后使用支持向量机作为训练器,可 ...
随机推荐
- Delphi中ARC内存管理的方向
随着即将发布的10.3版本,RAD Studio R&D和PM团队正在制作Delphi在内存管理方面的新方向. 几年前,当Embarcadero开始为Windows以外的平台构建新的Delph ...
- bzoj 3301 Cow Line
题目大意: n的排列,K个询问 为P时,读入一个数x,输出第x个全排列 为Q时,读入N个数,求这是第几个全排列 思路: 不知道康拓展开是什么,手推了一个乱七八糟的东西 首先可以知道 把排列看成是一个每 ...
- Olddriver’s books
Olddriver 的书多的吓人,什么算法导论,组合数学英 文版(orz)......他把 n 本书都放在身后的桌子上, 每本书有一定的面积,并且书可以覆盖,求 n 本书覆盖桌面 的面积 输入格式: ...
- jeesite自定义主题
jeesite cms首页太丑不够逼格,然而国内有很多高大上的皮肤供你选择,那么本文就一步一步教你如何定制自己的CMS站点视图. 1.下载 jeesite 源码,并安装配置成功 2.进入jeesite ...
- 那些有意思的Github
https://github.com/ngosang/trackerslist Linux下那些有趣的命令.. https://www.linu&xp&robe.com/linux-i ...
- JS判断数组是否包含某元素
我在学习ES6数组拓展时,发现了新增了不少了有趣的数组方法,突然想好工作中判断数组是否包含某个元素是非常常见的操作,那么这篇文章顺便做个整理. 1.for循环结合break 可能很多人第一会想到for ...
- IDEA报错,注解标红,提示Cannot resolve symbol xxx
一般都是jar包没导进来,可以先看一下setting里maven配置的路径对不对
- win10 激活方法 (各版本)
很多人都在找Win10专业版永久密钥,其实win10激活码不管版本新旧都是通用的,也就是说一个win10专业版key,可以同时激活windows10专业版1809.1803.1709.1703.160 ...
- JavaScript--编程挑战
小伙伴们,请编写"改变颜色"."改变宽高"."隐藏内容"."显示内容"."取消设置"的函数,点击相应 ...
- flask 三剑客
1.flask中的httpresponse @app.route("/") # app中的route装饰器 def index(): # 视图函数 return "Hel ...